the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Apr 2026
| 01 Apr 2026
Failure classification of wind turbine operational conditions using hybrid machine learning
Marcela Rodrigues Machado
Amanda Aryda Silva Rodrigues de Sousa
Jefferson da Silva Coelho
Rafael de Oliveira Teloli
Wind turbines are complex electromechanical systems that require continuous monitoring to ensure operational efficiency, reduce maintenance costs, and prevent critical failures. Machine learning has shown great promise in structural health monitoring (SHM) by enabling automated fault detection through data-driven approaches. However, challenges remain in adapting SHM methods to complex environmental conditions while maintaining reliable fault detection and classification. This work proposes a hybrid model that combines supervised and unsupervised learning techniques for classifying operational failures in wind turbines. The proposed framework integrates multimodal data, combining structural and environmental information to monitor four distinct operational states. The approach begins with analysing sensor signals and extracting descriptive features that capture the turbine's dynamic behaviour, accounting for the effects of temperature and wind speed. The unsupervised k-means is applied to label and cluster the dataset, while feature and sensor selection are performed using canonical correlation analysis to rank the most informative variables. A novel relative change damage index is introduced to normalize and scale features based on their relative variability, enhancing the accuracy of clustering and fault classification. Classification is performed using six machine learning algorithms, and the best model is identified. Experimental results, also considering environmental conditions and sensor failures, demonstrate strong performance across both binary and multi-class tasks, including the detection of pitch drive faults and the accurate identification of rotor icing and aerodynamic imbalance. The model achieved classification accuracies ranging from 85 % to 98 %, highlighting its effectiveness in diagnosing wind turbine conditions, and improving the overall reliability and operational analysis of these systems.
- Article
(7724 KB) - Full-text XML
- BibTeX
- EndNote




Wind turbines are complex electromechanical systems that operate in hazardous environments and contain critical components, including blades, main bearing, main shaft, gearbox, nacelle, tower, foundation, yaw system, and connecting bolts. Continuous monitoring of these components is essential to ensure their integrity, reduce costs, and enhance the operational efficiency of the turbines (Veers et al., 2023). Like any other electromechanical system, wind turbines are subject to several unforeseen and serious failures that can result in downtime (Asian et al., 2017; Machado and Dutkiewicz, 2024; Dutkiewicz and Machado, 2019a). Mechanical, electrical, and environmental failures are the primary causes of issues in wind turbines (Thomas, 2024). Mechanical failures typically affect components such as the rotor blades, gearbox, bearings, and main shaft, compromising the turbine's performance. In the electrical system, which includes generators, converters, and control systems, failures can result from insulation degradation, thermal voltages, and electrical transients, impacting the efficiency and safety of operation (Liu et al., 2024; Dutkiewicz and Machado, 2019b, c). Environmental factors, such as extreme temperatures, atmospheric discharges, humidity, wind direction and speed, and corrosion, pose significant challenges to turbine reliability and service life (Figueiredo et al., 2010; Morozovska et al., 2024). An effective wind turbine monitoring strategy combines the condition monitoring (CM) of mechanical subsystems and SHM of structural elements (Civera and Surace, 2022). The authors highlight the growing integration of both into AI-based systems, aiming to improve reliability and operational safety. Research on the fault detection of turbine components using machine learning (ML) techniques has advanced significantly over the past decade. It has significantly enhanced the efficiency and accuracy of SHM techniques by automating data analysis and improving damage detection (Smarsly et al., 2016; Flah et al., 2020; Farrar and Worden, 2012). These algorithms process large volumes of data, identifying patterns and anomalies that may indicate structural deterioration. Thus, structural health monitoring with machine learning (SHM-ML) has emerged as a powerful data-driven approach, enhancing multi-sensor systems and intelligent algorithms to detect, localize, and quantify structural damage under complex environmental and operational conditions.
Deep learning (DL) and machine learning (ML) models have emerged as leading approaches for wind turbine fault diagnosis, outperforming traditional methods in handling complex, nonlinear, and noisy operational data. Their applications span vision-based approaches (Li et al., 2024; Dwivedi et al., 2024; Li et al., 2025; Zhao et al., 2025), acoustic-based techniques (Regan et al., 2017; Kuo et al., 2022; Lei et al., 2025; Carmona-Troyo et al., 2025), and vibration-based monitoring, among others. Vision-based methods, however, remain limited to identifying superficial or external damage, and are strongly affected by lighting and weather conditions, while being unable to detect subsurface faults. Acoustic techniques are highly sensitive to environmental noise and often require expensive sensor maintenance, adding complexity to the monitoring process. Vibration-based monitoring is among the most established SHM strategies, as variations in natural frequencies, mode shapes, and damping ratios are closely associated with structural degradation. Nevertheless, its effectiveness can be reduced by operational variability, which makes it more difficult to detect early-stage or localized damage. Despite these limitations, vibration monitoring remains a widely applied technique for various wind turbine components.
Hybrid approaches involve strategies that combine multiple machine learning models, integrate multimodal or heterogeneous data, or fuse complementary algorithms with multiphysics information, thereby enhancing model generalization, interpretability, and reliability in complex monitoring scenarios. In this context, Baquerizo et al. (2022) proposed a Siamese neural network using image-like matrices from 24-channel triaxial accelerometer data for jacket structures, achieving 100 % accuracy in crack and bolt looseness detection. Building on this, Antoniadou et al. (2015b) combined vibration analysis, SCADA, and ML algorithms (SVM, neural networks, Gaussian processes) for blade and gearbox monitoring, extracting features from time, frequency, and time-frequency domains using diverse sensors, including accelerometers, fibre optics, and thermography. Hybrid intelligent models for floating offshore turbines using a conventional neural network long short-term memory with attention mechanism (CNN-LSTM-ATT) with Chebyshev decomposition to forecast mooring-line tension under harsh seas were proposed in (Tang et al., 2025). This is a Gaussian process system for predicting crack location, severity, and remaining useful life composite blades in Krishna et al. (2025); and a transformer-based PatchTST virtual sensor, trained on Alpha Ventus data, that accurately reconstructs strain in jacket foundations (Ángel Encalada-Dávila et al., 2025). A digital twin for mooring-line monitoring (Mousavi et al., 2024) used a hybrid CNN-LSTM with CEEMD/FDD-derived natural frequencies, achieving 97.65 % accuracy in damage localization and severity classification, outperforming the deep convolution neural network (DCNN), backpropagation neural network (BPNN), and support vector machine (SVM) under noise and environmental variability.
Wind turbine blade monitoring has increasingly leveraged hybrid machine learning models. Early approaches combined neural networks and Gaussian processes using frequency response functions and SCADA data (Antoniadou et al., 2013, 2015a), while Dervilis et al. (2014b, a) employed auto-associative neural networks with RBF models to achieve high sensitivity with few false positives. Rule-based and ensemble methods (Joshuva and Sugumaran, 2017; Joshuva et al., 2019), which integrated MLPs and logistic model trees with ARMA features, achieved 94.75 % accuracy in crack localization. More recent studies focus on hybrid architectures that fuse different algorithms or modalities. Tsiapoki et al. (2018) combined environmental and operational effects with unsupervised clustering, Movsessian et al. (2022) integrated Mahalanobis distance, XGBoost, and SHAP for explainable SHM, Song et al. (2024) and Sharma and Nava (2024) employed CNN-GRU and AR-CNN hybrids for offshore blade and mooring system monitoring (with over 93 % accuracy), and Ashkarkalaei et al. (2025a, b) combined one-class SVM, autoencoders, and DSFs with ANOVA-selected features with random forest (achieving F1 >95 %). Bayesian-optimized kNN/SVM frameworks (Korolis et al., 2025) and relevance vector machines (Kuai et al., 2024) further demonstrate the advantages of hybrid and sparse models, offering high accuracy and computational efficiency under environmental variability.
The vulnerability of towers and foundations has driven the development of hybrid ML-based SHM strategies. Nguyen et al. (2018) combined artificial neural networks (ANNs) with modal parameters, such as mode shapes and frequencies, to localize and quantify tower damage in simulations. An extension proposed in Hoxha et al. (2020) integrated vibration responses with multiple classifiers, including kNN, quadratic SVM, and Gaussian SVM, for tower fault detection. For jacket-type foundations, Vidal et al. (2020) and Leon-Medina et al. (2021) employed PCA for dimensionality reduction combined with classifiers such as kNN, SVM, and XGBoost to detect and localize cracks. Ren and Yong (2022) advanced unsupervised hybrid methods using dynamically weighted k-means clustering to categorize tower fault types. Random forest classifiers can effectively monitor blade pitch misalignment, capturing subtle deviations (Milani et al., 2025). ANNs and Gaussian processes combined with SVM were used in drivetrain monitoring (Elforjani, 2020), and feature extraction and PCA can enhance gearbox fault detection. Zarrin et al. (2021) developed a neuromorphic model for classifying accelerometer data from healthy and damaged gearboxes, while Gao et al. (2021) applied CNNs for bearing and gearbox fault detection. Praveen et al. (2022) improved vibration monitoring by segmenting gearbox signals and validating them with decision trees, SVM, and deep neural networks. For bearing faults, Vives (2022); Vives et al. (2022) demonstrated the effectiveness of combining kNN, SVM, and deep learning, whereas Meyer (2022) and Amin et al. (2023) employed unsupervised and cyclostationary-feature CNNs for accurate health state classification. These studies highlight the advantages of hybrid approaches that integrate multiple algorithms and preprocessing techniques to enhance robustness in fault detection and classification.
Data quality, imbalance, generalization, feature selection, and explainability remain challenges in wind turbine monitoring, with ongoing research focused on improving applicability, addressing data limitations, and enhancing interpretability. Despite recent advances, SHM techniques still face difficulties in generalizing across operational and environmental conditions while ensuring reliable detection. While many studies employ supervised, unsupervised, or hybrid learning for anomaly detection and classification, these methods are still limited to specific operations and the detection of local component faults. Hybrid machine learning models, particularly those that account for environmental variability, have strong potential for wind turbine diagnostics, enabling accurate early fault detection and adaptability. However, a research gap remains in designing hybrid frameworks that balance computational efficiency and interpretability without compromising diagnostic performance.
This study proposes a hybrid monitoring that integrates multiple machine learning models with multimodal data to enhance the reliability, accuracy, and interpretability of fault detection in the Aventa wind turbine. Unlike conventional single-model or single-source approaches, the proposed framework effectively captures cross-domain correlations and accounts for environmental variability, enabling dependable monitoring under complex operational conditions. The methodology employs unsupervised k-means clustering to partition the data into homogeneous clusters, thereby facilitating pattern recognition without predefined labels. These clusters are subsequently analysed using multiple supervised machine learning algorithms for binary and multi-class fault classification, based on structural-temporal response signals and SCADA data (wind speed and temperature) from the Aventa onshore wind turbine. The framework simultaneously performs fault classification, feature ranking, and sensor selection, demonstrating flexibility in handling diverse input features and reinforcing SHM decision-making. The main contributions of this study are (i) the development of a hybrid ML framework for operational fault assessment combining multiple supervised and unsupervised learning techniques and multimodal data, (ii) the formulation of a feature relative change damage index strategy for feature normalization and scaling, and (iii) the implementation of a canonical correlation-based feature and sensor selection process. By integrating multiphysics information, the proposed model enhances diagnostic capability, computational efficiency, and prediction accuracy. Experimental validation on the Aventa 6.7 kW onshore wind turbine confirms high performance in both binary and multi-class fault classification. Six ML algorithms were compared, and the best-performing model achieved classification accuracies of 85 %–98 %. The framework reliably detected pitch drive faults, and accurately identified rotor icing and aerodynamic imbalance, even under varying environmental conditions and sensor failure scenarios, demonstrating its effectiveness and potential for real-world SHM applications.
The proposed monitoring model consists of seven steps, as illustrated in Fig. 1, including (1) receiving the acquired data; (2) data processing and organization; (3) feature extraction, normalization, and grouping for similarity pattern; (4) unsupervised feature labelling and clustering; (5) feature and sensor selection; (6) data splitting, and ML failure identification and classification; and (7) fault classification and model evaluation. The final step also outputs the operational failure and identifies the best-performing ML algorithm based on its performance metric. The novelties of the presented study are associated with feature and sensor selection, data normalization, and multimodal and multiple fault classification, which are detailed in Sects. 2.2, 2.3, and 2.1. The pseudocode developed for the failure classification, presented in Algorithm 1, has the following structure.
Algorithm 1Hybrid ML model for Aventa wind turbine failure classification.
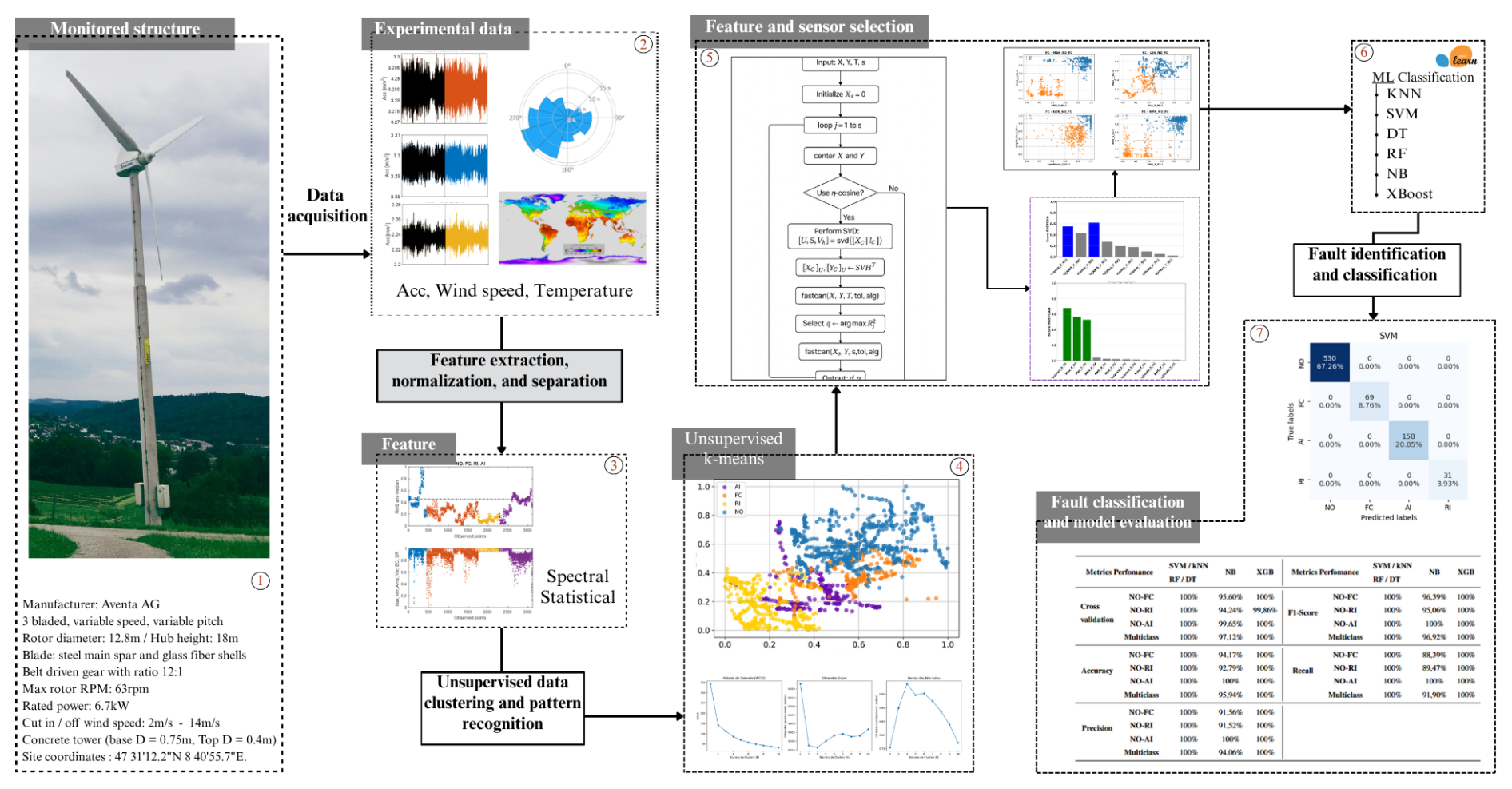
Figure 1Pipeline of the hybrid machine learning model for fault classification on the Aventa 6.7 kW wind turbine.
2.1 Data processing, signal, and sensor analysis
The wind turbine monitored in this study is the Aventa AV-7 model, manufactured by Aventa AG (Switzerland) and commissioned by ETH. This turbine has a rated power of 6.7 kW and operates using a belt-driven generator coupled with a frequency converter and a variable-speed drive. It begins generating power at a wind speed of 2 m s−1 and has a cut-off speed of 14 m s−1. The rotor has a diameter of 12.8 m with three blades and is mounted at a hub height of 18 m. The maximum rotational speed reaches 63 rpm. Turbine control is managed through a variable-speed and variable-pitch mechanism. The turbine is installed in Taggenberg, Switzerland (coordinates: 47°31′12.2′′ N, 8°40′55.7′′ E). Instrumentation and data acquisition were provided in Chatzi et al. (2023) and include 14 accelerometers strategically placed along the tower, on the nacelle main frame, the main bearing, and the generator, as shown in Fig. 2. Additionally, two full-bridge strain gauges are mounted at the tower base to measure fore-aft and side-to-side strain, which can be converted into bending moments. Acceleration and strain signals are sampled at 200 Hz. Environmental measurements, including temperature and humidity, are collected at the tower base at a sampling rate of 1 Hz. Operational performance data (SCADA), including wind speed, nacelle yaw orientation, rotor RPM, power output, and turbine status, are recorded at 10 Hz. To ensure data quality and enhance the reliability of fault detection, a comprehensive supervised data preprocessing was implemented. This included supervised sensor analysis, outlier removal, signal segmentation, detrending, feature extraction, normalization, and similar feature identification and grouping.
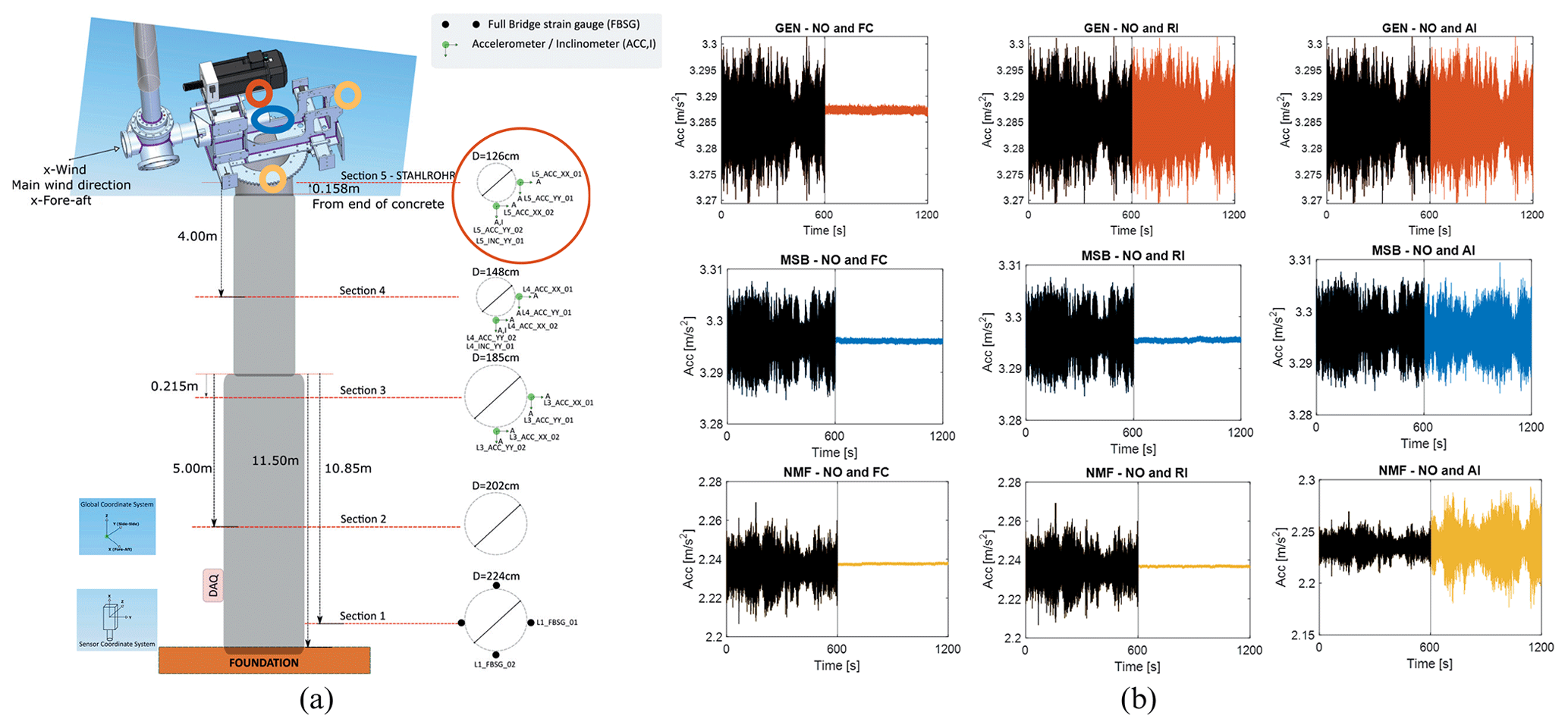
Figure 2Schematic representation of the turbine sensor channel and location (Chatzi et al., 2023). SCADA data and accelerometers marked in orange, blue, and yellow colours are adopted in the monitoring (a). Temporal signal data of the turbine's NO and operation with failures (b): top: sensor GEN NO-FC, NO-RI, and NO-AI placed from left to right, respectively; middle: sensor MSB NO-FC, NO-RI, and NO-AI; and bottom: sensor NMF NO-FC, NO-RI, and NO-AI.
Table 1Information on SCADA data and accelerometers used in the monitoring, with the respective sensor channel and location.
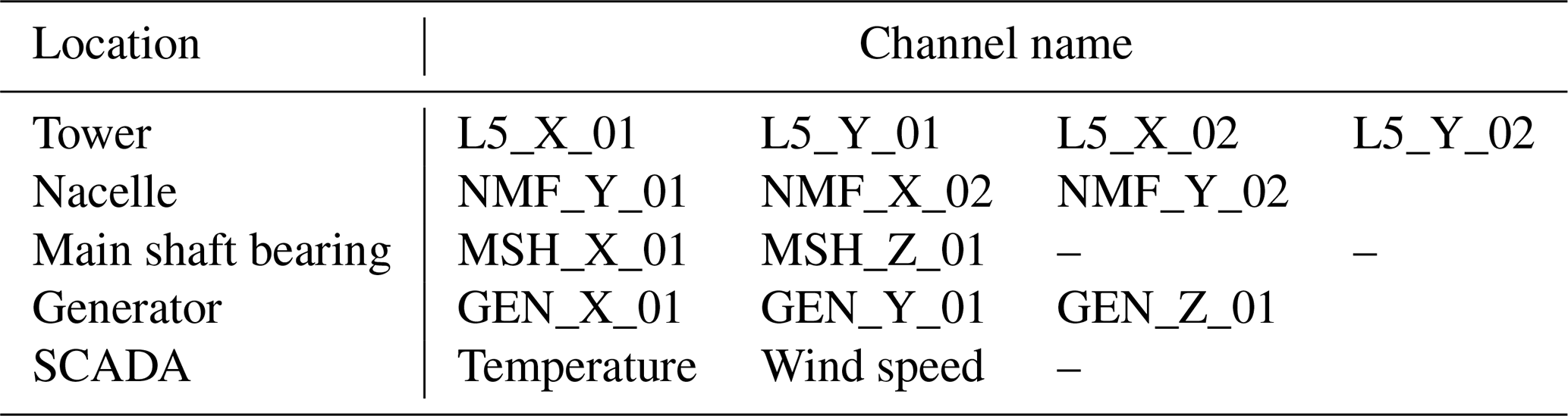
The data preprocessing stage begins by analysing the sensors' physics and evaluating each sensor's contribution to failure identification. The pre-established failures are the rotor icing event (RI), the flexible coupling of the linear drive of the collective pitch system (FC), and aerodynamic imbalance on one blade (AI). The Aventa dataset provides three-axis acceleration signals. Table 1 lists the SCADA data and accelerometers used for monitoring, along with their respective sensor channels and locations. The x axis captures side-to-side turbine motion, and the y axis captures fore-aft turbine motion. Figure 2a illustrates the sensor locations within the turbine. Aside from the SCADA data (temperature and wind velocity), accelerometers marked in orange, blue, and yellow are used for monitoring. Specifically, three accelerometers are located in the nacelle, GEN_ACC (orange), NMF_ACC (blue), and MSB_ACC (yellow); and one is located at the tower top, F5_ACC. The sensors record signals under the different operational conditions, including normal operation (NO). Figure 2 also presents the raw temporal data available in the dataset. In the acceleration graphs, black lines indicate normal turbine operation, whereas coloured lines represent various failure conditions. To ensure consistent comparisons, all signals were selected from the same day, minimizing the influence of changing environmental conditions.
The top row of graphs shows the x axis response from the generator-mounted sensor (GEN), comparing NO with failures FC, RI, and AI, from left to right. The middle row displays the x axis response from the main shaft bearing sensor (MSB), and the bottom row shows the same for the nacelle main frame sensor (NMF), following the same failure comparison pattern. Both x and y axis signals were analysed, revealing consistent trends: FC failures led to a pronounced amplitude reduction, whereas RI and AI failures resulted in only minor amplitude changes. These variations may fluctuate daily due to environmental conditions. To ensure effective fault detection, data from accelerometer sensors placed at the tower top, nacelle, main shaft bearing, and generator were used in the model, considering their sensitivity to structural, mechanical, and aerodynamic failures.
2.2 Dataset
During data analysis, duplicate files were identified, prompting a data redistribution strategy to eliminate redundancies and streamline the process. The data were categorized and colour-coded by operational conditions and events, making patterns – such as seasonality, frequency, and duration – more apparent and visually accessible. These cleaning and reorganization steps ensure that the same data are not reused across different turbine operations, thereby reducing the risk of misclassification and misinterpretation during monitoring.
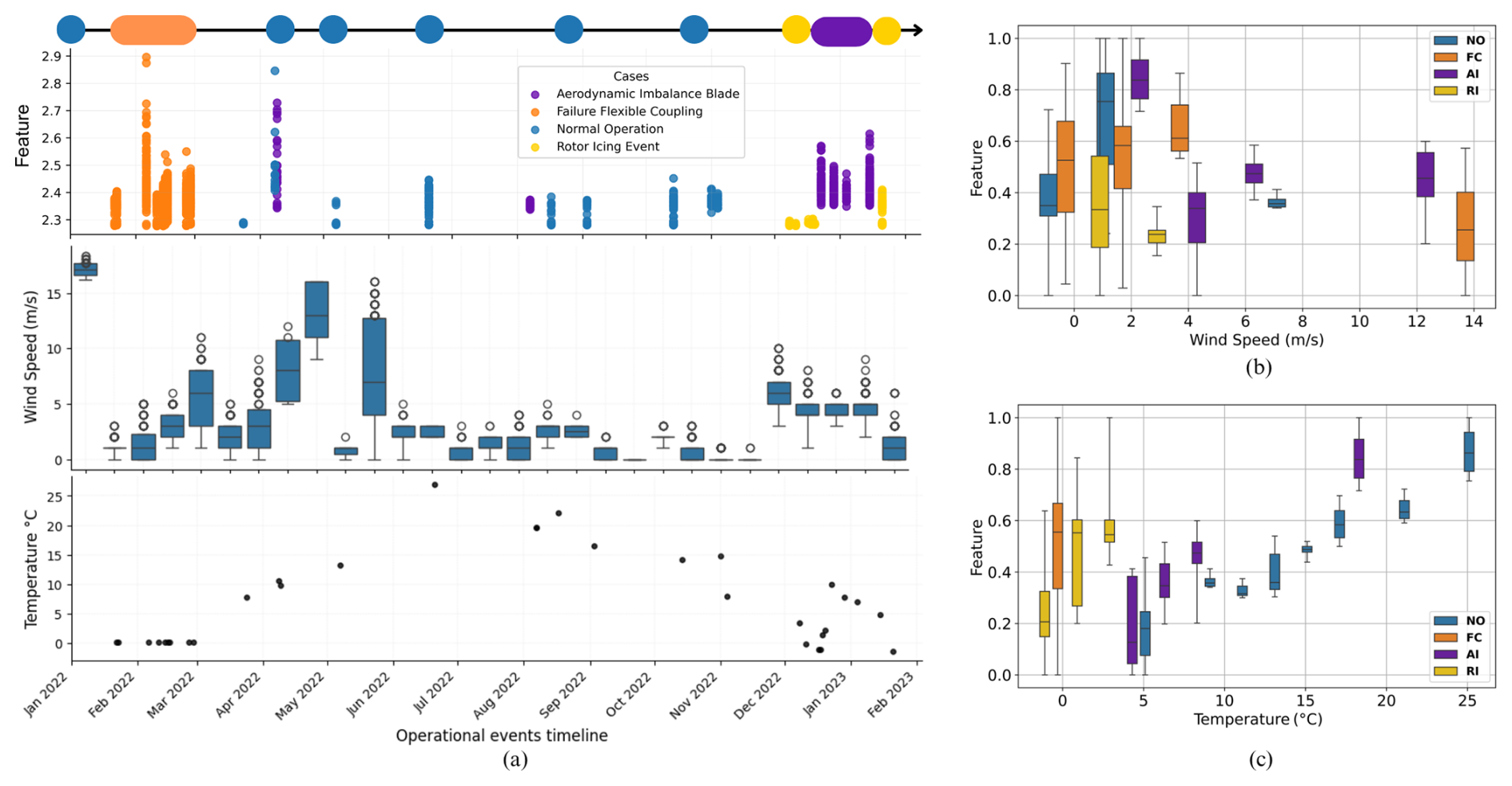
Figure 3The feature dataset volume over the monitoring timeline categorized by yellow indicates RI, blue denotes NO, purple corresponds to AI, and orange represents the FC condition (a) (top). Wind speed boxplot (a) (middle), and mean temperature ((a) bottom). Boxplot of L05 sensor feature by wind speed variation (b) and feature by temperature variation (c).
Feature extraction was performed after this reorganization. Aside from the accelerometer sensors, the supervisory control and data acquisition (SCADA) data include the temperature, wind speed, humidity, and power output. Temperature, wind speed, and acceleration responses are used for monitoring. Figure 3a shows the maximum values of the temporal spectrum for each operational condition mapped over the monitoring timeline. Each condition is colour-coded for clarity: yellow for RI, blue for NO, purple for AI, and orange for flexible FC. Events are plotted along the horizontal axis to highlight their temporal distribution. The timeline begins with a NO sample, followed by a pitch drive coupling failure recorded on 16 February 2022, which required replacement. From April to November 2022, the turbine operated normally, during which AI was intentionally simulated using roughness tape on the blades. Additionally, naturally occurring RI events were observed between December 2022 and February 2023. Wind speed fluctuates throughout the monitoring period, as indicated by the boxplot, which displays the minimum, maximum, median, and first and third quartiles of the wind speed data. Meanwhile, ambient temperature ranges from −2 to 26 °C throughout the year (see Fig. 3c).
Both environmental conditions – wind speed and temperature – significantly influence the dynamic response of the wind turbine over time. Figure 3b–c present boxplots showing the feature values corrected by wind speed and temperature, respectively. This analysis focuses on the RMS value of sensor NMF, selected for its highest-scoring features and well-defined failure patterns, which represent the general behaviour of the features. When correlating feature values with wind speed, the FC and AI conditions exhibit the greatest sensitivity to increasing wind speeds, though with relatively low dispersion. Conversely, RI, NO, and FC show higher maximum, minimum, and quartile values at lower wind speeds. Regarding temperature, rising temperatures primarily affect NO and AI conditions, whereas lower temperatures have a greater impact on FC and RI. These findings underscore the importance of incorporating environmental variables into the monitoring framework to improve the robustness and accuracy of fault classification. The SCADA data in the general dataset are considered the mean temperature and mean wind speed, both acquired over the 24 h of the respective day.
2.3 Feature extraction, normalization, and dataset organization
Feature selection involves choosing a subset of variables from the original dataset. This step transforms the spectrum data into new variables to create a refined dataset (Bishop, 2006). Fifteen features are formulated using the time-domain signal (Knittel et al., 2019; Barreto et al., 2021; Ashkarkalaei et al., 2025a), as presented in Table 2, where x is the temporal spectrum signal and p is the sampling points value.
Table 2Temporal and statistical formulation used for feature extraction.
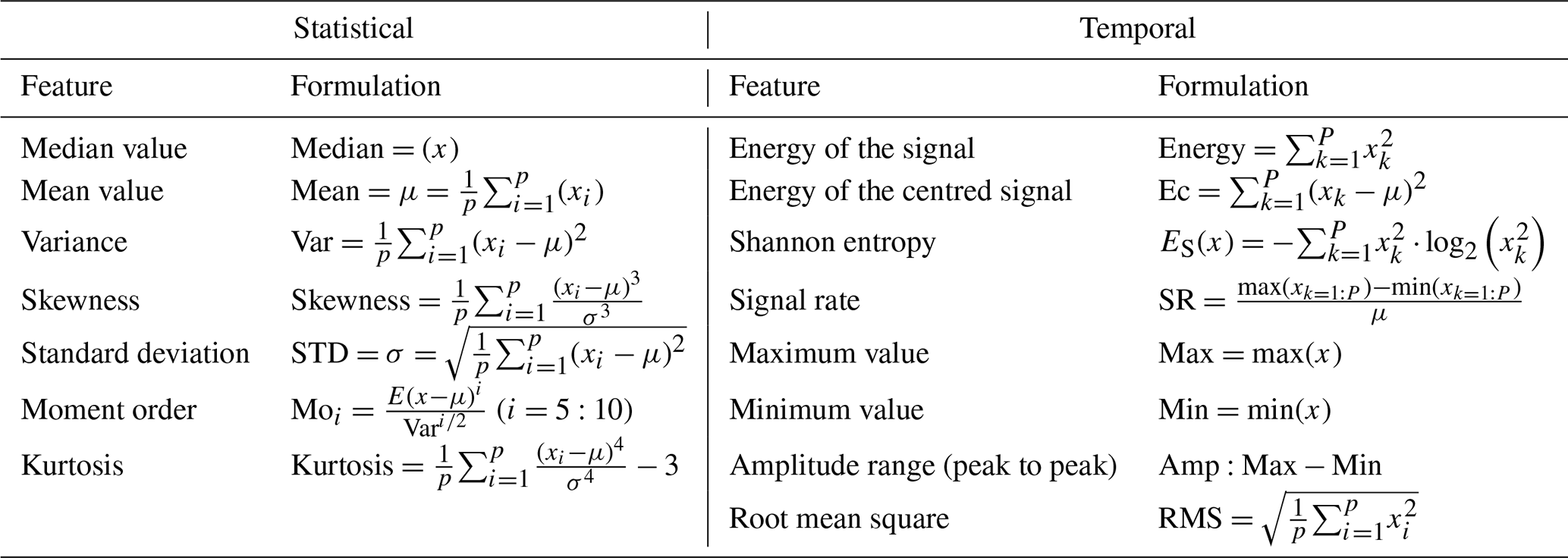
Temporal features are extracted from a signal's frequency or time content, such as maximum, minimum, amplitude range, energy, energy centre, skewness, signal rate, and RMS. It captures how the signal's energy is distributed over time. Statistical features, in turn, are computed from the signal's time-domain values, including the median, mean, variance, skewness, kurtosis, higher-order moments, and standard deviation, which characterize the overall distribution and variability of the signal. Together, these features are compiled, analysed, and evaluated for their similarity and sensitivity to the system's dynamic behaviour.
Despite feature refinement and grouping, the remaining features still pose a challenge due to their minimal amplitude variation, often differing by only a few digits. Such small variations can hinder accurate machine learning classification. To address this issue, the proposed relative change damage index incorporates a normalization step based on the relative change of each feature, defined as
where X is a table containing the selected features and Δf measures each feature's deviation from its maximum value within the selected feature set to each feature vector point (Xi). The normalization factor RC rescales these deviations to the [0, 1] interval. This linear transformation preserves the original ordering and proportionality of the data, ensuring that the intrinsic dynamic pattern is maintained. At the same time, it amplifies subtle differences that would otherwise be masked by small numerical variations, thereby enhancing the sensitivity of the features for fault detection and classification. Hence, the RC normalization converts the data into dimensionless features that, prior to normalization, differed only slightly (e.g. 3.280 vs 3.286), rendering these differences numerically negligible for machine learning models. Thus, the proposed approach amplifies these small variations while preserving the intrinsic dynamic pattern. Features with values close to unity correspond to undamaged conditions, whereas values approaching zero indicate faults. Hence, the method enhances fault sensitivity and enables consistent comparison across features of different magnitudes, making the damage feature more sensitive to anomalies under varying operating states.
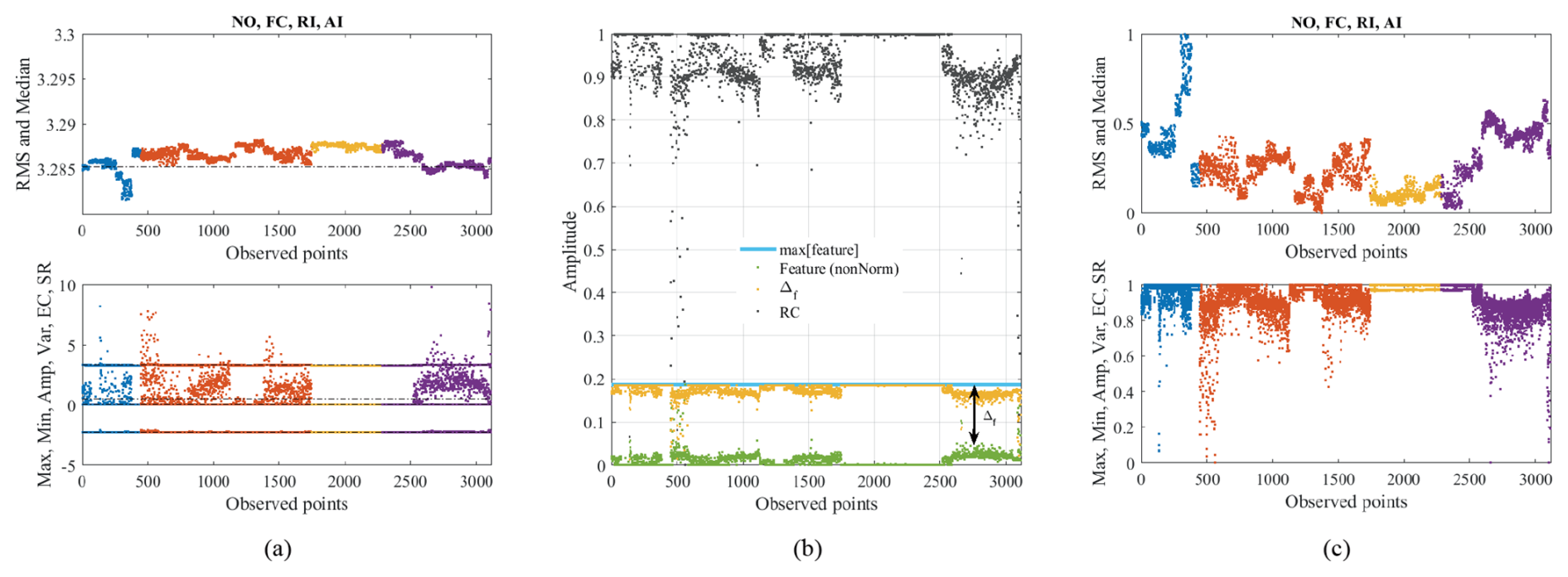
Figure 4(a) Non-normalized features grouped by similarity under different operating conditions: NO – blue, FC – orange, RI – yellow, and AI – purple. (b) Demonstration of the scaling and normalization on the Amp feature related to Eq. (1). Scaled and normalized features grouped by similarity under different conditions (c).
The relative change normalization provides a theoretical foundation based on relative scaling and dimensionless feature representation. Figure 4a–c illustrates the process: (a) the non-normalized features, (b) the scaling and normalization applied to the Amp feature (extended to all others), and (c) the normalized features obtained using the proposed relative change technique. Features such as energy, kurtosis, higher-order moments, and Shannon entropy exhibited low sensitivity to failures and were excluded during normalization and analysis. This first supervised analysis revealed two feature groups with similar behaviour. Group 1 consists of the RMS and median (Fig. 4c, top), while Group 2 comprises the maximum, minimum, amplitude range, variance, energy centre, and signal rate (Fig. 4c, bottom). The formation of two feature groups indicates a high degree of correlation within each group, with RMS and median primarily capturing the signal's central tendency. In contrast, the features of Group 2 describe its variability and extremes. Therefore, using all features would introduce redundancy, increase computational cost, and risk overfitting due to the curse of dimensionality. Selecting only representative features from each group ensures that the classifier retains the essential discriminatory information while improving efficiency and generalization.
From the two correlated feature groups, four representative features (RMS, maximum, variance, and amplitude range) were selected to compose the global dataset. Those four features were chosen over the other in their respective group due to near-equivalence, thus avoiding redundancy. The initial global dataset, therefore, consisted of the four selected features extracted from each sensor axis, resulting in a structure of measurement_rows × 48 columns, plus the SCADA data, as detailed in Table 1. However, including all these features may appear arbitrary and degrade model performance due to their high similarity. To refine the global dataset, a canonical correlation analysis was applied to identify the most sensitive features for each sensor, accounting for all axes simultaneously within the sensor group. The highest feature correlation scores were selected, reducing the dataset to four representative features plus SCADA. This process yielded the final datasets: the binary classification dataset has six columns (four features plus SCADA), and the multi-class dataset has nine columns (selected features plus SCADA). Identifying the most informative sensor is also relevant, as it indicates which sensor contributes most to classification accuracy and provides resilience in the event of sensor loss. To validate this study, the most sensitive feature from the best-performing sensor was removed in subsequent tests, thereby demonstrating the robustness and consistency of the proposed feature selection strategy. Feature and sensor selection are detailed in Sect. 2.1.
Structured final datasets
The final refined dataset organization is a crucial step for enabling machine learning algorithms to accurately classify operational failures. The deployed dataset exhibits a multimodal nature, integrating structural, temperature, and wind velocity information. The structural data are directly acquired from the accelerometers, which capture the system's physical response and potential failure signatures. In contrast, temperature and wind speed data are obtained from the SCADA system and represent indirect but relevant variables that influence the dynamic behaviour measured by the accelerometers. However, they do not directly describe the damage dynamics. The final dataset is organized into four configurations, which are evaluated. Their relevance is demonstrated in Sect. 4, yielding the following:
-
Fe-kms-Sc. Dataset composed of the selected features (Fe) extracted from the accelerometer time signals, followed by the SCADA data (Sc) and label defined by the k-means clustering (kms),
-
Fe-Sc-kms. Dataset including the selected features, the SCADA data, and the corresponding k-means labels,
-
Fe-kms. Dataset including the selected features and the k-means labels, without incorporating the SCADA information,
-
Fe-kms-LoseSensor. Dataset including the selected features excluding those obtained from the most sensitive sensor identified by the Fast CCA method, together with the k-means labels and SCADA data. This configuration simulates the loss of the most sensitive sensor in each analysis scenario.
The k-means labelling of the datasets Fe-kms-Sc and Fe-kms-LoseSensor is applied exclusively to the features that contain the most relevant physical information about the damage. The SCADA data are then organized by the corresponding day and hour for each feature sample. This ensures that the SCADA records follow the same row reordering imposed by the k-means clustering, while preserving the correct temporal (day and hour) correspondence between the SCADA measurements and the related accelerometer data.
The monitoring model integrates sequential stages, starting with data processing and feature extraction, followed by pattern recognition through clustering, and extending to feature and sensor selection to strengthen dataset reliability. By coupling unsupervised clustering with canonical-correlation-based feature selection, the framework ensures the preservation of the most informative variables, thereby enhancing classification accuracy.
3.1 Pattern recognition and clustering
Unsupervised pattern recognition, labelling, and clustering of the normalized features were performed using the k-means algorithm, with the elbow method applied to determine the optimal number of clusters. The silhouette coefficient and Davies–Bouldin index are internal validation metrics used to assess the number and quality of clusters identified by k-means. Table 3 lists the k-means metrics for each sensor and case of study.
Table 3k-means clustering identification for each sensor related to the failure associated with the silhouette coefficient and Davies–Bouldin index performance metrics.

For binary cases (k=2), the results indicate good separability between operating conditions, with consistent metrics across different components and failure types. In NO-FC scenarios, silhouette score values remain high (between 0.86 and 0.87), and Davies–Bouldin indices are low (between 0.12 and 0.13), indicating that points within each group are very similar to each other and that the clusters are well separated. In NO-RI and NO-AI conditions, the results still exhibit a satisfactory clustering structure, with silhouette values ranging from 0.56 to 0.60, and Davies–Bouldin scores between 0.58 and 0.75, indicating good cluster quality. In general, all binary-scenario cases yielded metrics superior to the reference values recommended in the literature (silhouette >0.5 and Davies–Bouldin <1.0), confirming that the clustering method can adequately distinguish the different operational states of the turbines. For the multi-class case with k=4, the validation metrics indicate good clustering quality. Silhouette score values range from 0.52 to 0.60, and the Davies–Bouldin index values range from 0.50 to 0.60, indicating compact and well-separated clusters. These results confirm that the clustering process identified variations in turbine operational states. Therefore, these metrics provide strong evidence that the clustering step is reliable and that the labels assigned during the unsupervised phase are consistent.
Table 4Explicit description of the datasets used for training, validation, and testing.

The outputs are subsequently used as inputs for the feature and sensor selection. Furthermore, the samples were randomly divided, and the clustered dataset was split into training/validation 75 % and test 25 %, which were used for model construction and evaluation, as shown in Table 4. Each classifier was assessed using a 5-fold cross-validation procedure to enhance training accuracy, which was achieved by randomly partitioning the training dataset into five distinct subsets.
3.2 Feature and sensor fast selection
The supervised feature analysis indicates that changes in the turbine's dynamic behaviour are associated with specific events. For the subsequent procedures, feature and sensor selection are performed using the canonical-correlation-based feature selection method (FASTCAN) introduced by Zhang et al. (2025), which was initially applied only for feature selection and is extended in this work to include sensor selection. Therefore, the selection process is carried out in two steps: first, identifying the best feature(s) for each sensor and, second, selecting the most relevant sensor(s). The pseudocode for this process is given in Algorithm 2, which is repeated for each fault diagnosis. The FASTCAN method is based on the canonical correlation coefficient (CCA), a measure of the linear association between two multivariate random variables. It evaluates the relevance of features with respect to the response matrix. Given the feature matrix and the response matrix , the canonical correlation coefficient is defined as
where XC and YC are column-centred matrices and denotes the Pearson correlation. The projection vectors αi∈ℝn and βi∈ℝm are obtained by solving the following eigenvalue problems:
The eigenvalues correspond to the squared canonical correlation coefficients, while αi and βi are the canonical weight vectors that define the canonical variates XCαi and YCβi. There are at most non-zero canonical correlation coefficients . The overall criterion for feature selection is the sum of squared canonical correlations (SSC):
To accelerate computation, the SSC can be reformulated using two equivalent decompositions: (i) the h-correlation form (valid when ),
where {wi} and {vj} are orthogonal bases of the feature and response spaces; and (ii) the θ-angle form (valid when ),
where the canonical correlations are expressed as squared cosines of the principal angles between the subspaces of X and Y. In the greedy selection step, the next feature xri is chosen to maximize the incremental SSC:
where Xs denotes the already selected features. This formulation allows efficient feature ranking by reducing computational complexity while preserving the theoretical properties of canonical correlation analysis.
This process involves looping through the features for each sensor in an interaction. In sequence, a similar procedure is performed for sensor ranking, with the feature matrix defined as , where Xs contains the highest ranking feature(s) of each sensor.
Algorithm 2Pseudocode for the feature and sensor selection with canonical correlation.
3.3 Classification and model evaluation
ML algorithms are applied to classify the operational condition of the wind turbine by analysing datasets. As an automated approach, ML identifies patterns in data through various algorithms, and uses these learned patterns for predictive analysis and decision-making. The proposed model follows a hybrid unsupervised-supervised ML-based framework, incorporating classification strategies to improve the structure of data attributes. The data-driven ML models are fed selected features extracted from the multiphysics database, incorporating vibration responses and environmental data, and the output corresponds to the wind turbine's operational classification state.
For the classification task, six supervised ML algorithms are utilized, and the unsupervised k-means algorithm is used for initial clustering. At the same time, the supervised classifiers Naive Bayes (NB), decision tree (DT), random forest (RF), kNN, SVM, and extreme gradient boosting (XGB) are employed to detect the system's operational conditions. The ML algorithms embedded in the framework are based on the open-source Scikit-learn library. These algorithms perform final classification based on the initial clustering results, producing outputs including confusion matrices and performance metrics. The selection of hyperparameters follows the recommendations in de Sousa et al. (2023) and Coelho et al. (2024, 2025), which identified optimal configurations for this application. Specifically, the SVM model employs a linear kernel with a penalty parameter of C=100, a one-vs-one multi-class strategy, and a tolerance of . For kNN, the number of neighbours is set to k=3, using the Euclidean distance metric, uniform weights, and a leaf size of 30. The RF and DT algorithms both use 100 trees, a maximum depth of 3, and the Gini splitting criterion. The Naive Bayes classifier employs a Gaussian model, while XGBoost uses the XGBClassifier implementation. These configurations have shown high accuracy and robustness in prior studies, and are adopted here to optimize classification performance.
The final step involves evaluating model performance on a previously separated test dataset. Hyperparameters may be fine-tuned to improve accuracy, precision, recall, and the F1-score. A confusion matrix is also analysed to provide further diagnostic insight. To prevent overfitting and ensure generalizability, a 5-fold cross-validation scheme is employed. Performance metrics and confusion matrices are generated for all algorithms, enabling the framework to identify the most accurate model and guide users in selecting the most suitable ML algorithm for wind turbine monitoring.
During the monitoring process, data from various sensors are available. To ensure accurate failure identification and classification, it is essential to evaluate the most informative sensor data. In the proposed framework, both features and sensors are ranked and selected to compose the reduced dataset, ensuring that only the most sensitive information related to the specific failure is included and fed into the ML algorithm for wind turbine condition classification. The feature and sensor scores, normalized to the range [0, 1], are returned by the CCA's ranking process. Further, the dataset for the ML algorithms was built by selecting the top-ranked features from each sensor, along with the SCADA wind speed and temperature.
The evaluation of the turbine's operational condition includes both binary and multi-class classification tasks. Table 5 summarizes the failure cases related to the most sensitive feature of each sensor (Xs) and the most sensitive sensor associated with its features for each failure.
Table 5Description of the sensitive feature of each sensor (Xs) and an indication of the most sensitive sensor of each failure case.

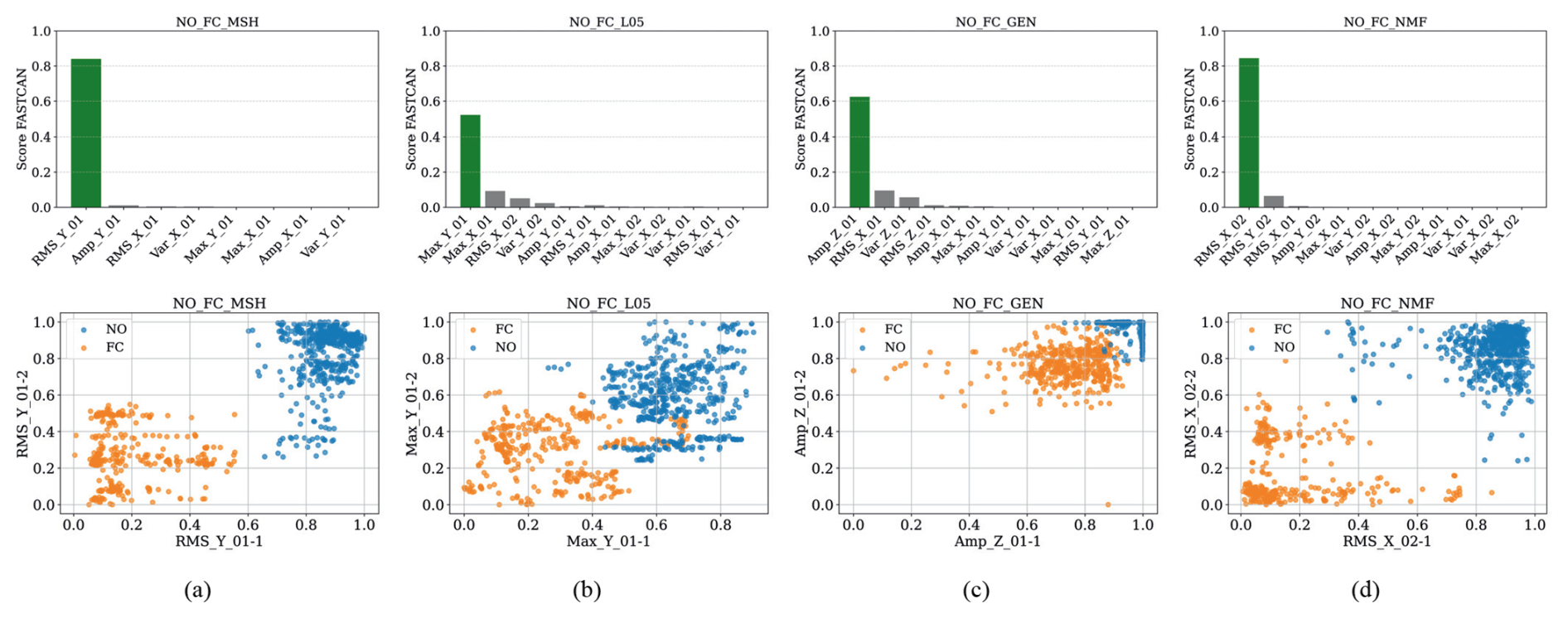
Figure 5CCA feature score and dispersion diagrams of the highest-scoring feature for the NO-FC failure: (a) sensor MSH, (b) sensor L05 (1 and 2), (c) sensor GEN, and (d) sensor NMF (1 and 2).
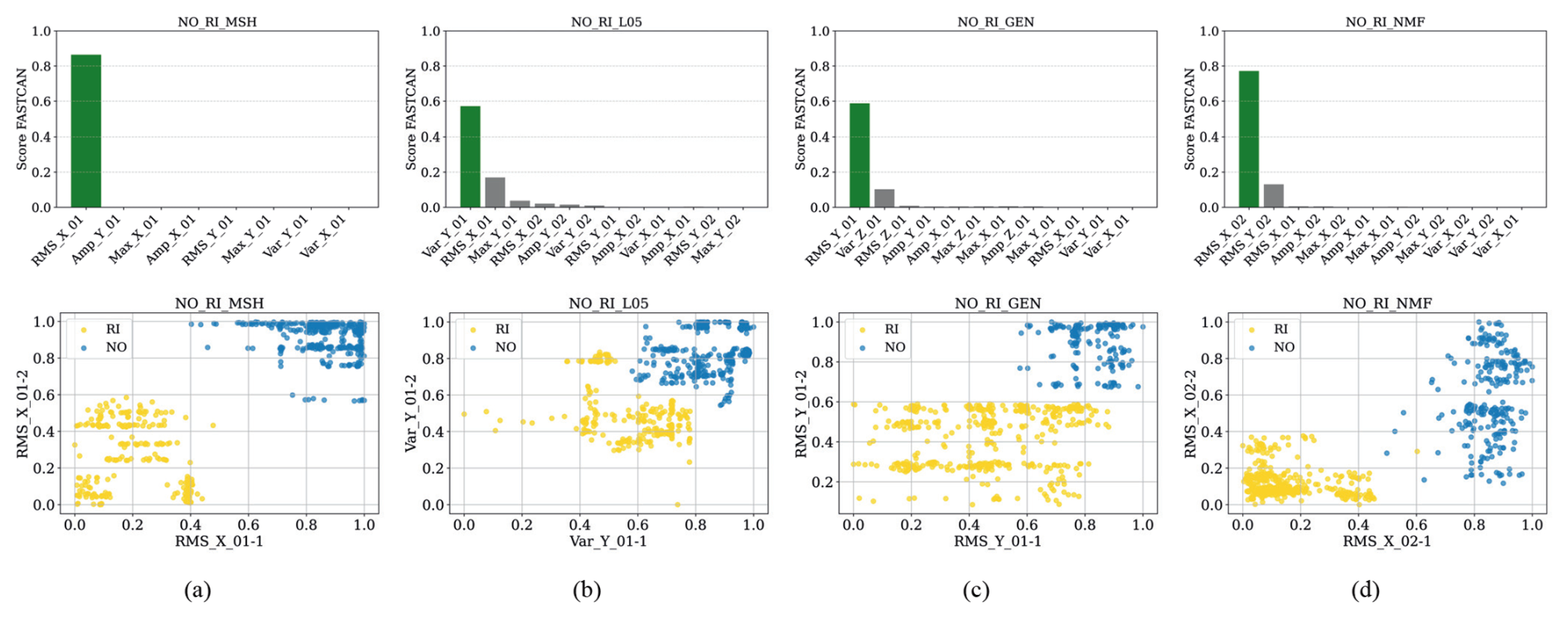
Figure 6CCA feature score and dispersion diagrams of the highest-scoring feature for the NO-RI failure: (a) sensor MSH, (b) sensor L05 (1 and 2), (c) sensor GEN, and (d) sensor NMF (1 and 2).
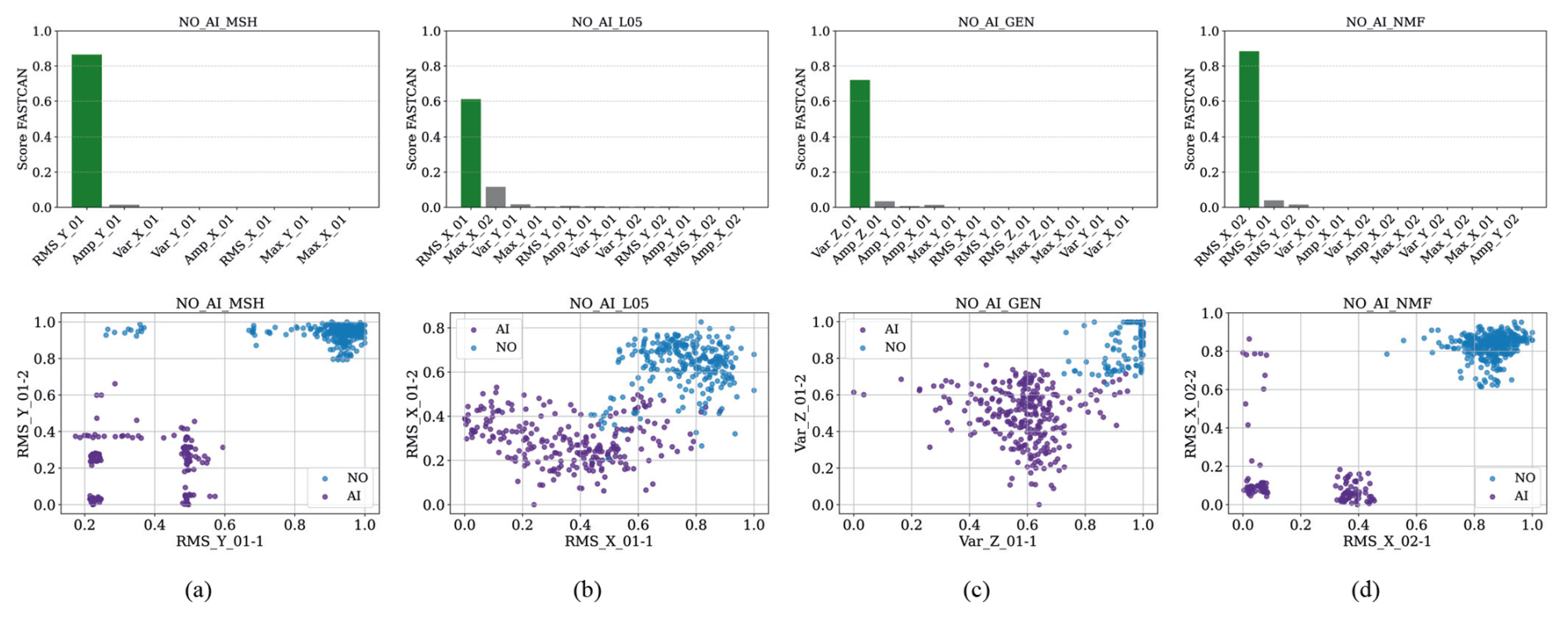
Figure 7CCA feature score and dispersion diagrams of the highest-scoring feature for the NO-AI failure: (a) sensor MSH, (b) sensor L05 (1 and 2), (c) sensor GEN, and (d) sensor NMF (1 and 2).
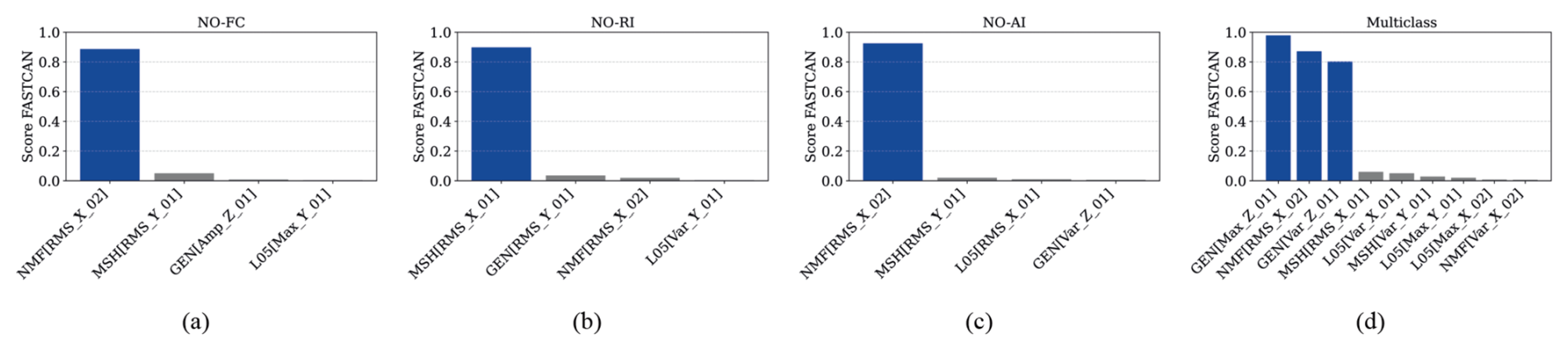
Figure 8Sensor score based on the top-performing features of each operational condition: (a) NO-FC, (b) NO-AI, (c) NO-RI, and (d) multi-class.
For binary classification between NO and FC failure, the individual feature scores for each accelerometer sensor are shown in Fig. 5a–d. Subsequently, in the sensor ranking, the NMF sensor (RMS_X02NMF) yields the highest score, indicating it as the most sensitive to FC-related failures, as shown in Fig. 8a. The k-means algorithm is applied to label and organize the data based on similarities among the selected features. Incorporating more informative features improves both pattern recognition and classification accuracy. Each feature is visualized individually for clarity, and the final classification integrates all selected features along with SCADA data to strengthen the overall decision-making process. Features with minimal overlap between operational states are especially valuable, as they contribute to clearer distinctions and improved ML performance in identifying fault conditions. Scatter plots in Fig. 5e–h display the correlation between Feature-1 and Feature-2, which represent two groups derived from splitting each selected feature column. These diagrams highlight how high-scoring features cluster across sensors, revealing patterns that differentiate between normal and faulty operating conditions. The identified clusters exhibit consistent grouping and dispersion, thereby enhancing the interpretability of each operational condition.
For classification between NO and RI, the feature scores for each accelerometer are shown in Fig. 6a–d and Table 5, with the MSH sensor (RMS_X02MSH) achieving the highest score, indicating strong sensitivity to RI-related anomalies, as indicated in Fig. 8b. The k-means clustering is applied to the selected features to identify patterns and assign labels. Scatter plots in Fig. 6e–h display the highest-scoring feature pairs (Feature-1 vs Feature-2) per sensor, revealing clear cluster separation between NO and RI. These dispersion diagrams highlight how specific failures impact dynamic behaviour, with minimal overlap between classes indicating highly informative features for classification. For the NO-AI, the feature ranking scores of each accelerometer are presented in Fig. 7a–d, where the NMF sensor (RMS_X02NMF) shows the highest relevance, indicating strong responsiveness to RI-related conditions – see Fig. 8c. The k-means clustering is applied to the selected features to identify patterns and assign labels. The resulting scatter plots in Fig. 7e–h show the top-ranked feature pairs (Feature-1 vs Feature-2) for each sensor, revealing distinct cluster boundaries between NO and AI. These diagrams illustrate how different faults affect the turbine's dynamic behaviour, with low class overlap indicating that the selected features are highly effective for classification.
In the multi-class classification, the k-means algorithm identifies four clusters corresponding to NO, FC, RI, and AI conditions, organizing the dataset accordingly into response clusters. These clusters support further validation of classification through performance metrics. Figure 9 displays the highest-scoring features of each sensor and their related dispersion diagrams, labelled by k-means and ranked by Algorithm 2, respectively. Each class is colour-coded to facilitate quick visual identification and analysis of overlaps between operational states.
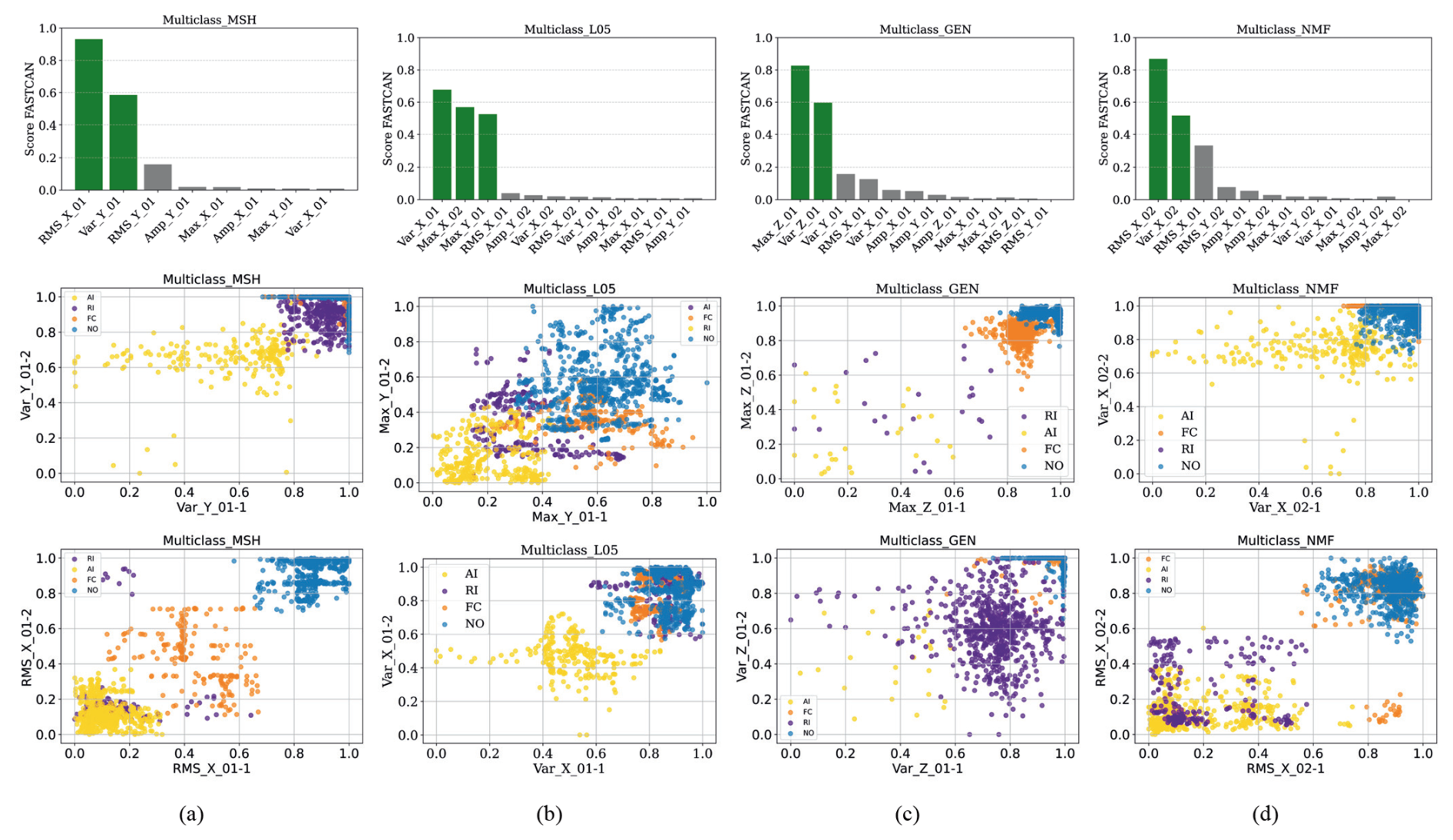
Figure 9CCA feature score and dispersion diagrams of the highest-scoring feature: (a) sensor MSH, (b) sensor L05 (1 and 2), (c) sensor GEN, and (d) sensor NMF (1 and 2).
Figure 9a–d gives the top-ranked features from each sensor, MSH, L05, NMF, and GEN, respectively, highlighting the most sensitive sensors selected for multi-class classification. Likewise, in the binary case, features with higher scores are included in the global dataset for classification, with the GEN and NMF sensors showing the highest relevance, indicating strong sensitivity, as shown in Fig. 8d. Each selected feature is visualized through its dispersion correlation, also in Fig. 9a–d. Overall, k-means effectively assigns each operational fault to a class. Certain features exhibit a clear separation between normal conditions and fault types, although overlap among fault classes is evident in all cases. This suggests that while individual features may help to detect abnormal behaviour, they are not self-sufficient alone to discriminate between specific failure modes. These individual feature analyses reveal important patterns. However, when classification models are applied, features are considered in combination. This integrated approach improves both classification accuracy and the robustness of the performance metrics. While some features aid in distinguishing normal from faulty states, reliable fault classification generally requires the combined contribution of multiple informative features.
Operational condition classification and metrics evaluation
The fault classification uses six supervised machine learning algorithms: kNN, SVM, DT, RF, Naive Bayes, and XGBoost. These algorithms perform the final classification using the input dataset, producing confusion matrices and performance metrics. The selection of hyperparameters is based on the investigations of de Sousa et al. (2023), which specify optimal configurations for this assignment and are briefly described in Sect. 3.3.
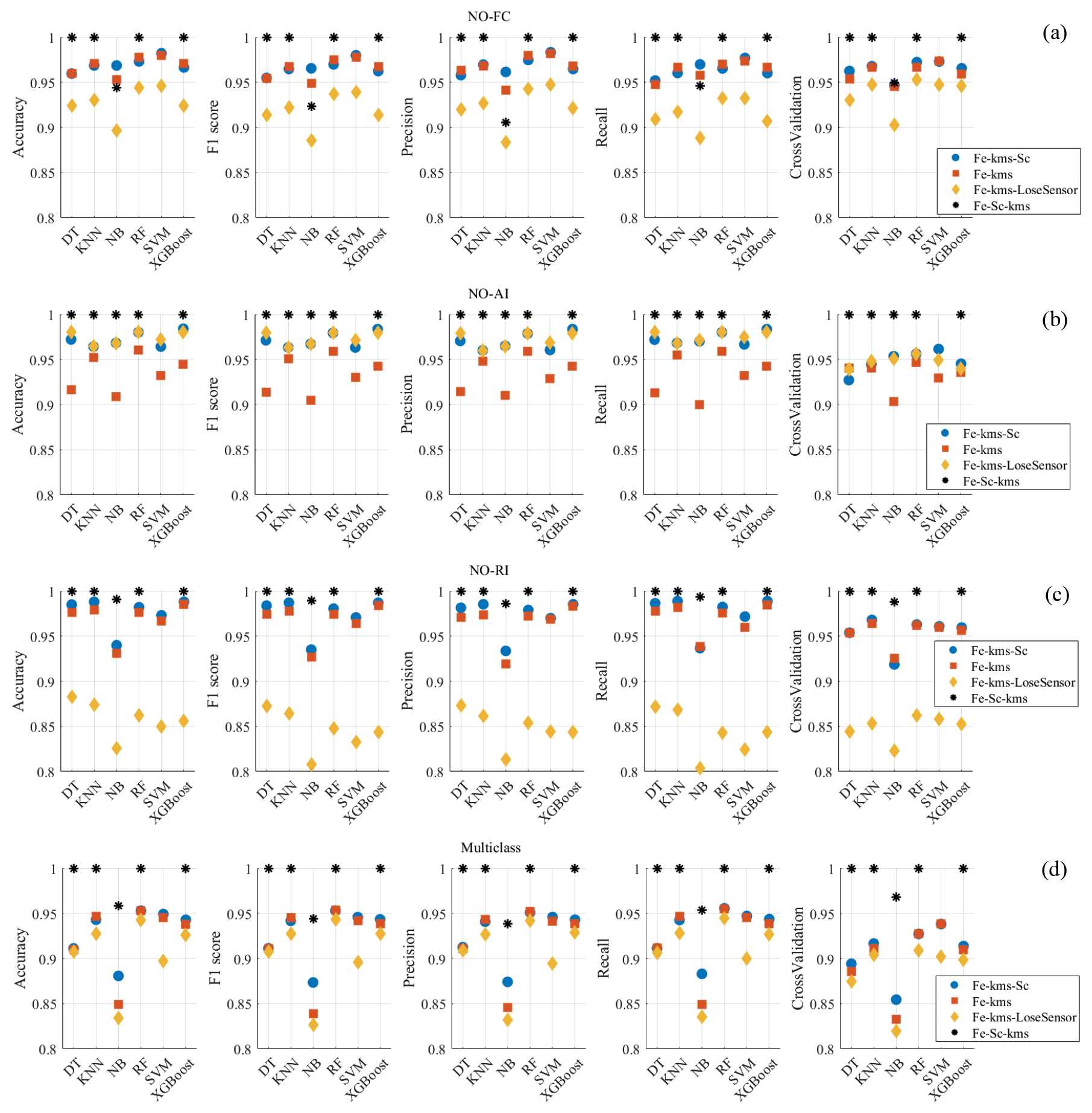
Figure 10Comparison of the metrics (accuracy, F1-score, precision, recall, and cross-validation) for the six ML algorithms and each arranged final dataset. (a) Binary NO-FC, (b) binary NO-AI, (c) binary NO-RI, and (d) multi-class failure study cases.
Figure 10 presents the performance of ML models for binary classification (NO-FC, NO-RI, and NO-AI) and multiple failure conditions, evaluated via cross-validation and metrics such as accuracy, precision, recall, and F1-score. For metric estimation, micro-, macro-, and weighted averages were tested, assuming the micro as the standard because it computes classification metrics by globally summing true positives, false positives, and false negatives across all classes, resulting in similar precision, recall, and F1-score.
The ML models were tested on the Fe-kms-Sc, Fe-Sc-kms, Fe-kms, and Fe-kms-LoseSensor datasets to assess the influence of environmental dependencies (SCADA data) and the sensitivity of each sensor in failure evaluation. The metrics for the Fe-Sc-kms dataset, shown as black (∗) in Fig. 10a–d, indicate that, except for the NB classifier, all ML models achieved 100 % accuracy. Such a perfect performance across multiple models can suggest potential issues, such as data leakage, overfitting, or improper dataset splitting. However, cross-validation with multiple random partitions was performed to ensure statistical robustness. In this case, the consistently high accuracy reflects the physical consistency and strong discriminative power of the selected features rather than methodological flaws.
The k-means clustering results and associated metrics also reveal clear class separation. The feature scores derived from the CCA, which quantify the linear association between the selected features and the k-means clusters (Fig. 11), highlight the strong correlation between SCADA data and the structural sensors (accelerometers). The SCADA system provides environmental variables, such as daily temperature and wind speed but lacks important structural information more directly related to damage states. In the Fe-Sc-kms dataset configuration, both features and SCADA inputs are used in the k-means clustering, which is predominantly influenced by the SCADA parameters. This result is supported by Wang et al. (2026). Therefore, the perfect ML metrics are attributed to dataset bias, where the models primarily classify failure conditions based on environmental variations rather than the structural response itself.
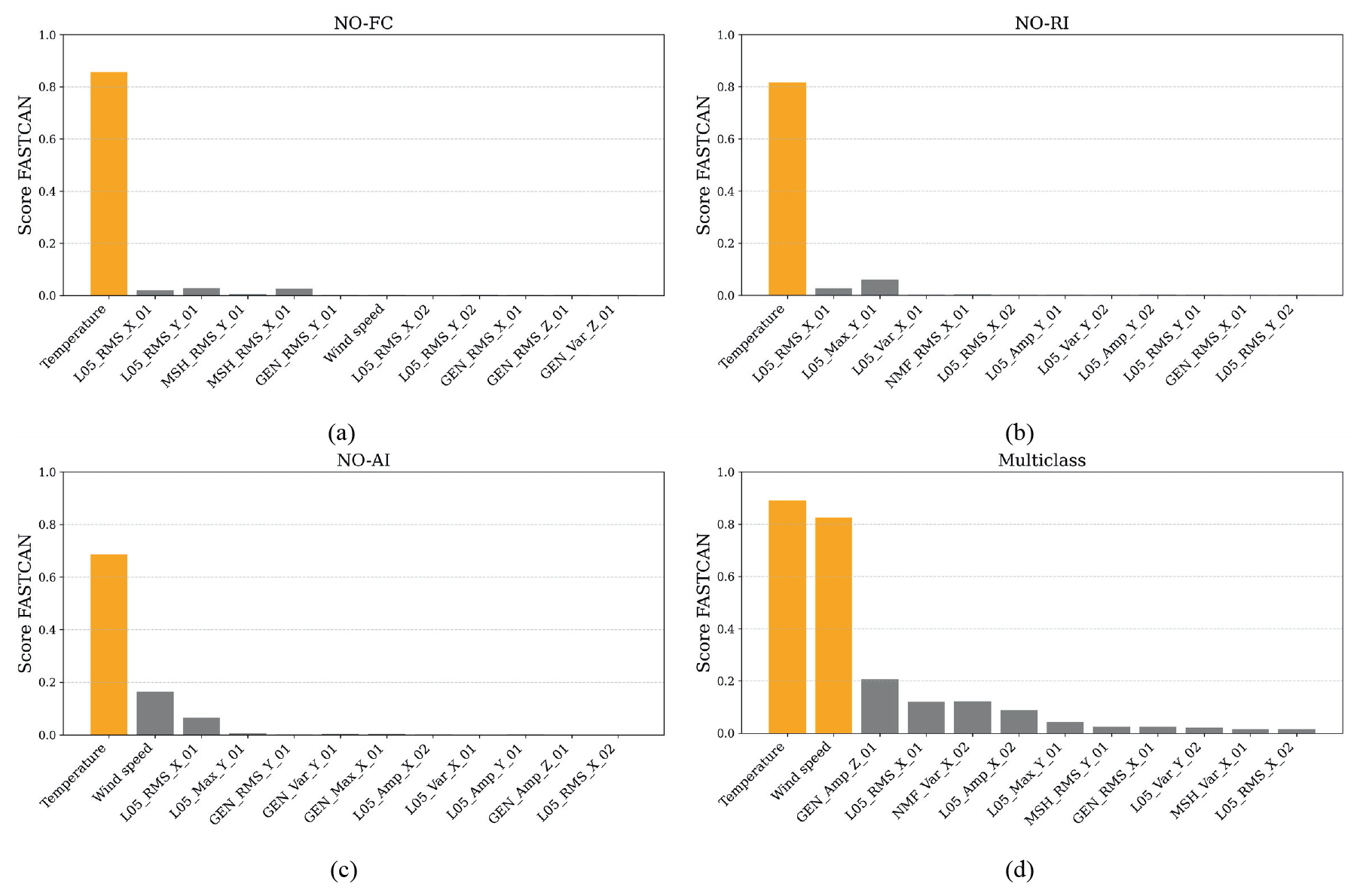
Figure 11Feature score of the Fe-Sc-kms dataset for (a) NO-FC, (b) NO-RI, (c) NO-AI, and (d) multi-class.
The models' metrics for the Fe-kms-Sc dataset, shown as blue (•) in Fig. 10a–d, indicate the sensitivity of the ML algorithms to the failure classification. The k-means is performed on the structural features, and the SCADA follows its data reorganization, but it is not directly considered in the k-means labelling. For the binary case, the model's metrics range from 0.93 to 0.99. The SVM model reached 0.98 on the NO-FC case, XGBoost reached 0.98 for NO-AI, and XGBoost reached 0.99 for NO-RI. The multi-class case varied from 0.86 by NB to 0.955 by RF. The SCADA data are not included in the Fe-kms dataset, shown as orange (▪) in Fig. 10a–d. The performance metrics reached 0.98 with the SVM model for the NO-FC case, 0.955 with RF for the NO-AI case, 0.98 with XGBoost for the NO-RI case, and 0.95 with RF in the multi-class analysis. When the most sensitive sensor for each failure case was removed from the Fe-kms-LoseSensor dataset (yellow ⧫), performance metrics decreased, except for NO-AI, indicating the importance of this sensor's information for monitoring accuracy and model performance. This result also reinforces the fact that the most sensitive sensor is typically located near the damage site. In the NO-AI case, all sensors were positioned on the nacelle and tower. Although these sensors can capture the dynamic effects of blade aero-imbalance, they are distant from the local damage, which reduces their sensitivity to this phenomenon. Consequently, the sensor group primarily captured global structural responses to the fault rather than local damage effects, which explains the variation in performance when one sensor was removed.
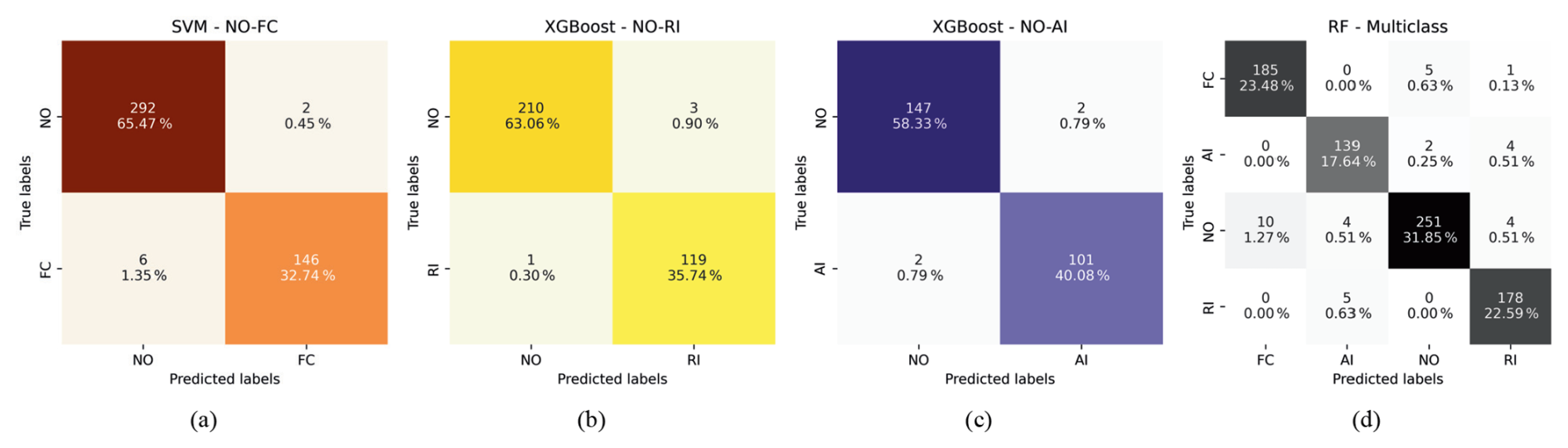
Figure 12Confusion matrix of binary operational classification for (a) NO-FC, (b) NO-RI, (c) NO-AI, and (d) multi-classification. The dataset assumes the best features plus SCADA data (temperature and wind speed) in each analysis.
The confusion matrices shown in Fig. 12a–c present the results of binary classification using the respective best-performing ML algorithms using the Fe-kms-Sc dataset. In the NO-FC case, the SVM model achieved optimal accuracy and cross-validation, correctly classifying 292 samples as NO (65.47 %) and 146 as FC (32.74 %). For the NO-RI classification, the XGBoost model correctly classifies 210 samples as NO (63.06 %) and 119 as RI (35.74 %). In the NO-AI scenario, the XGBoost model outperformed the others, correctly classifying 101 samples as AI (40.08 %) and 147 as NO (58.33 %). Figure 12d displays the confusion matrix for the multi-class classification involving AI, FC, NO, and RI. The RF model correctly identified 139 samples as AI (17.64 %), 185 as FC (23.48 %), 178 as RI (22.59 %), and 251 as NO (31.85 %).
Among the evaluated configurations, the Fe-kms-Sc dataset provided the most balanced and reliable results for the treated failure identification, including structural and environmental condition information. The dataset Fe-Sc-kms yielded perfect metrics across all models, primarily because environmental parameters, such as temperature and wind speed, were dominant, biasing the classification towards environmental conditions rather than structural responses. In contrast, excluding SCADA data (Fe-kms) enabled the models to capture damage-related structural dynamics more accurately, but it did not account for environmental variability. The Fe-kms-LoseSensor results highlighted the critical role of the most sensitive sensor, typically located near the damage, in maintaining model accuracy. Overall, the Fe-kms-Sc dataset, which integrates structural features with aligned but non-dominant environmental information, yielded the most physically consistent and discriminative performance for the wind turbine failure classification.
This study proposes a data-driven hybrid framework for classifying operational conditions of a wind turbine, including normal operation, pitch drive faults, rotor icing, and aerodynamic imbalance, integrating in a hybrid approach multimodal data and multiple ML algorithms. The monitoring process follows this pipeline: data processing and organization, feature extraction, normalization and grouping, clustering, feature and sensor selection, data splitting, machine learning classification, and model evaluation. A novel relative change damage index was introduced to enhance scalability and normalize features extracted from structural dynamic responses and environmental conditions. Canonical correlation analysis was used to identify and rank the most sensitive features among the 15 extracted from temporal responses and SCADA data (wind speed and temperature), and to rank sensors. Thus, multimodal information, including vibration signals from six accelerometers distributed across the turbine and environmental parameters(wind speed and temperature), was incorporated into the framework. Unsupervised k-means clustering enabled the discovery of homogeneous data groups, supporting robust pattern recognition without predefined labels.
Failure classification was implemented as both binary and multi-class tasks using kNN, SVM, DT, RF, Naive Bayes, and XGBoost. Models were tested on the Fe-kms-Sc, Fe-Sc-kms, Fe-kms, and Fe-kms-LoseSensor datasets to evaluate the influence of environmental factors and sensor sensitivity. Using the Fe-kms-Sc dataset, the models performed best, where SVM achieved the highest accuracy for NO-FC (0.98), XGBoost for NO-RI (0.99) and NO-AI (0.98), and RF for multi-class classification (0.955). The Fe-kms-Sc dataset, which combines structural features with aligned SCADA data, yielded the most reliable failure detection. Excluding SCADA data (Fe-kms), the models focused on structural changes, with binary accuracies of 0.93–0.99 and multi-class accuracies of 0.86–0.95. Including SCADA alone (Fe-Sc-kms) produced perfect metrics due to environmental dominance, whereas removing the most sensitive sensor (Fe-kms-LoseSensor) reduced performance, confirming the importance of sensor placement near the damage and identifying the most sensitive sensor in each analysis.
The proposed hybrid model, developed and tested on a 6.7 kW Aventa turbine, effectively manages the complexity of multi-source turbine data and representative fault variations. Its success relies on careful feature and sensor selection, ML model selection, the inclusion of environmental data, dataset multimodality, and thoughtful dataset arrangement, which together enhance discriminative power and classification reliability. However, validation is limited by the small size of the wind turbine, the use of induced faults to simulate aero-imbalance in the blades, and differences between small-scale experimental turbines and large-scale operational turbines or wind farms. Extreme environmental and operational events, such as strong turbulence, large-scale icing, and mixed-fault scenarios, were not included in this study due to the controlled nature and limited scope of the experimental datasets. Ongoing studies aim to evaluate the methodology on larger, more diverse datasets; to further explore environmental effects; to extend the study to offshore wind farms; and to assess the reliability, generalization, and applicability to utility-scale systems.
The underlying code for this study is available at https://github.com/iMOSS-Lab/rp-wedowind-challenge -ASCE-EMI (last access: 20 March 2026) and https://doi.org/10.5281/zenodo.18940555 (Machado, 2026).
The public data used in this article can be accessed at https://doi.org/10.5281/zenodo.8229750 (Chatzi et al., 2023).
All authors contributed to the conceptualization and methodology. AASRS and JSC carried out data curation, formal analysis, investigation, and software development. MRM and ROL were responsible for funding acquisition, project administration, resources, and supervision. MRM prepared the paper, with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
This research is part of project no. 444595/2024-4, funded by the National Council for Scientific and Technological Development-CNPq. Marcela Rodrigues Machado acknowledges the sponsors of projects (CNPq, Capes Finance Code 001, and FAPDF.00193-00002143/2023-02).
This research has been supported by the Conselho Nacional de Desenvolvimento Científico e Tecnológico (grant no. 444595/2024-4).
This paper was edited by Yi Guo and reviewed by three anonymous referees.
Amin, A., Bibo, A., Panyam, M., and Tallapragada, P.: Vibration based fault diagnostics in a wind turbine planetary gearbox using machine learning, Wind Engineering, 47, 175–189, https://doi.org/10.1177/0309524X221123968, 2023. a
Ángel Encalada-Dávila, Vidal, Y., and Tutivén, C.: Strain virtual sensor for offshore wind turbine jacket supports: A time series transformer approach validated with Alpha Ventus wind farm data, Mech. Syst. Signal Pr., 231, 112653, https://doi.org/10.1016/j.ymssp.2025.112653, 2025. a
Antoniadou, I., Dervilis, N., Barthorpe, R. J., Manson, G., and Worden, K.: Advanced tools for damage detection in wind turbines, Key Engineering Materials, 569–570, 547–554, https://doi.org/10.4028/www.scientific.net/KEM.569-570.547, 2013. a
Antoniadou, I., Dervilis, N., Papatheou, E., Maguire, A. E., and Worden, K.: Aspects of structural health and condition monitoring of offshore wind turbines, Philos. T. R. Soc. A, 373, https://doi.org/10.1098/rsta.2014.0075, 2015a. a
Antoniadou, I., Dervilis, N., Papatheou, E., Maguire, A. E., and Worden, K.: Aspects of structural health and condition monitoring of offshore wind turbines, Philos. T. R. Soc. A, 373, 20140075, https://doi.org/10.1098/rsta.2014.0075, 2015b. a
Ashkarkalaei, M., Ghiasi, R., Pakrashi, V., and Malekjafarian, A.: Feature selection for unsupervised defect detection of a wind turbine blade considering operational and environmental conditions, Mech. Syst. Signal Pr., 230, 112568, https://doi.org/10.1016/j.ymssp.2025.112568, 2025a. a, b
Ashkarkalaei, M., Ghiasi, R., Pakrashi, V., and Malekjafarian, A.: Optimum feature selection for the supervised damage classification of an operating wind turbine blade, Struct. Health Monit., 0, 1475, https://doi.org/10.1177/14759217251313815, 2025b. a
Asian, S., Ertek, G., Haksoz, C., Pakter, S., and Ulun, S.: Wind Turbine Accidents: A Data Mining Study, IEEE Syst. J., 11, 1567–1578, https://doi.org/10.1109/JSYST.2016.2565818, 2017. a
Baquerizo, J., Tutivén, C., Puruncajas, B., Vidal, Y., and Sampietro, J.: Siamese Neural Networks for Damage Detection and Diagnosis of Jacket-Type Offshore Wind Turbine Platforms, Mathematics, 10, https://doi.org/10.3390/math10071131, 2022. a
Barreto, L. S., Machado, M. R., Santos, J. C., De Moura, B. B., and Khalij, L.: Damage indices evaluation for one-dimensional guided wave-based structural health monitoring, Lat. Am. J. Solids Stru., 18, 1–17, 2021. a
Bishop, C. M.: Pattern Recognition and Machine Learning, Springer, 2nd edn., ISBN 978-1493938438, 2006. a
Carmona-Troyo, J. A., Trujillo, L., Enríquez-Zárate, J., Hernandez, D. E., and Cárdenas-Florido, L. A.: Classification of Damage on Wind Turbine Blades Using Automatic Machine Learning and Pressure Coefficient, Expert Systems, 42, e70024, https://doi.org/10.1111/exsy.70024, 2025. a
Chatzi, E., Abdallah, I., Hofsäß, M., Bischoff, O., Barber, S., and Marykovskiy, Y.: Aventa AV-7 ETH Zurich Research Wind Turbine SCADA and high frequency Structural Health Monitoring (SHM) data, Zenodo [data set], https://doi.org/10.5281/zenodo.8229750, 2023. a, b, c
Civera, M. and Surace, C.: Non-Destructive Techniques for the Condition and Structural Health Monitoring of Wind Turbines: A Literature Review of the Last 20 Years, Sensors, 22, https://doi.org/10.3390/s22041627, 2022. a
Coelho, J. S., Machado, M. R., Dutkiewicz, M., and O. Teloli, R.: Data-driven machine learning for pattern recognition and detection of loosening torque in bolted joints, J. Braz. Soc. Mech. Sci., 46, https://doi.org/10.1007/s40430-023-04628-6, 2024. a
Coelho, J. S., Machado, M. R., and Dutkiewicz, M.: Integrating Virtual Sensor Data Augmentation Into Machine Learning for Damage Quantification of Bolted Structures Under Assembly Uncertainty, Structural Control and Health Monitoring, 2025, 8030 303, https://doi.org/10.1155/stc/8030303, 2025. a
Dervilis, N., Choi, M., Antoniadou, I., Farinholt, K. M., Taylor, S. G., Barthorpe, R. J., Park, G., Farrar, C. R., and Worden, K.: Machine learning applications for a wind turbine blade under continuous fatigue loading, Key Eng. Mat., 588, 166–174, https://doi.org/10.4028/www.scientific.net/KEM.588.166, 2014a. a
Dervilis, N., Choi, M., Taylor, S., Barthorpe, R., Park, G., Farrar, C., and Worden, K.: On damage diagnosis for a wind turbine blade using pattern recognition, J. Sound Vib., 333, 1833–1850, https://doi.org/10.1016/j.jsv.2013.11.015, 2014b. a
de Sousa, A. A. S. R., da Silva Coelho, J., Machado, M. R., and Dutkiewicz, M.: Multiclass Supervised Machine Learning Algorithms Applied to Damage and Assessment Using Beam Dynamic Response, J. Vib. Eng. Technol., 11, 2709–2731, https://doi.org/10.1007/s42417-023-01072-7, 2023. a, b
Dutkiewicz, M. and Machado, M.: Measurements in Situ and Spectral Analysis of Wind Flow Effects on Overhead Transmission Lines, Sound & Vibration, 53, 161–175, https://doi.org/10.32604/sv.2019.04803, 2019a. a
Dutkiewicz, M. and Machado, M.: Spectral Approach in Vibrations of Overhead Transmission Lines, IOP Conference Series: Materials Science and Engineering, 471, Session 4, https://doi.org/10.1088/1757-899x/471/5/052029, 2019b. a
Dutkiewicz, M. and Machado, M.: Dynamic Response of Overhead Transmission Line in Turbulent Wind Flow with Application of the Spectral Element Method, IOP Conference Series: Materials Science and Engineering, 471, Session 5, https://doi.org/10.1088/1757-899x/471/5/052031, 2019c. a
Dwivedi, D., Babu, K. V. S. M., Yemula, P. K., Chakraborty, P., and Pal, M.: Identification of surface defects on solar PV panels and wind turbine blades using attention based deep learning model, Eng. Appl. Artif. Intel., 131, 107836, https://doi.org/10.1016/j.engappai.2023.107836, 2024. a
Elforjani, M.: Diagnosis and prognosis of real world wind turbine gears, Renew. Energ., 147, 1676–1693, https://doi.org/10.1016/j.renene.2019.09.109, 2020. a
Farrar, C. R. and Worden, K.: Structural Health Monitoring: A Machine Learning Perspective, ISBN 9781119994336, https://doi.org/10.1002/9781118443118, 2012. a
Figueiredo, E., Park, G., Farrar, C. R., Worden, K., and Figueiras, J.: Machine learning algorithms to damage detection under operational and environmental variability, P. Soc. Photo-Opt. Ins., 7650, https://doi.org/10.1117/12.849189, 2010. a
Flah, M., Nunez, I., Chaabene, W. B., and Nehdi, M.: Machine Learning Algorithms in Civil Structural Health Monitoring: A Systematic Review, Arch. Comput. Method. E., 28, 2621–2643, https://doi.org/10.1007/s11831-020-09471-9, 2020. a
Gao, Q., Wu, X., Guo, J., Zhou, H., and Ruan, W.: Machine-Learning-Based Intelligent Mechanical Fault Detection and Diagnosis of Wind Turbines, Math. Probl. Eng., 2021, https://doi.org/10.1155/2021/9915084, 2021. a
Hoxha, E., Vidal, Y., and Pozo, F.: Damage Diagnosis for Offshore Wind Turbine Foundations Based on the Fractal Dimension, Appl. Sci., 10, https://doi.org/10.3390/app10196972, 2020. a
Joshuva, A. and Sugumaran, V.: A data driven approach for condition monitoring of wind turbine blade using vibration signals through best-first tree algorithm and functional trees algorithm: A comparative study, ISA Transactions, 67, 160–172, https://doi.org/10.1016/j.isatra.2017.02.002, 2017. a
Joshuva, A., Vishnuvardhan, R., Deenadayalan, G., Sathishkumar, R., and Sivakumar, S.: Implementation of rule based classifiers for wind turbine blade fault diagnosis using vibration signals, International Journal of Recent Technology and Engineering, 8, 320–331, https://doi.org/10.35940/ijrte.B1050.0982S1119, 2019. a
Knittel, D., Makich, H., and Nouari, M.: Milling diagnosis using artificial intelligence approaches, Software Impacts, 20, 809, https://doi.org/10.1051/meca/2020053, 2019. a
Korolis, J. S., Bourdalos, D. M., and Sakellariou, J. S.: Machine Learning-Based Damage Diagnosis in Floating Wind Turbines Using Vibration Signals: A Lab-Scale Study Under Different Wind Speeds and Directions, Sensors, 25, https://doi.org/10.3390/s25041170, 2025. a
Krishna, S. R., Sathish, J., Tarun, M., Rahul Mani Datta, T., and Vamsi, S. Raghu, a. S. S. J.: Machine Learning-Enabled Crack Diagnosis and Prognosis in Glass/Carbon Fiber Composite Structures, Iranian Journal of Science and Technology, Transactions of Mechanical Engineering, 49, 1511–1530, https://doi.org/10.1007/s40997-025-00855-5, 2025. a
Kuai, H., Civera, M., Coletta, G., Chiaia, B., and Surace, C.: Cointegration strategy for damage assessment of offshore platforms subject to wind and wave forces, Ocean Eng., 304, 117692, https://doi.org/10.1016/j.oceaneng.2024.117692, 2024. a
Kuo, J.-Y., You, S.-Y., Lin, H.-C., Hsu, C.-Y., and Lei, B.: Constructing Condition Monitoring Model of Wind Turbine Blades, Mathematics, 10, https://doi.org/10.3390/math10060972, 2022. a
Lei, Z., Lin, H., Tang, X., Xiong, Y., and Wen, H.: Wind Turbine Blade Fault Detection Method Based on TROA-SVM, Sensors, 25, https://doi.org/10.3390/s25030720, 2025. a
Leon-Medina, J. X., Anaya, M., Parés, N., Tibaduiza, D. A., and Pozo, F.: Structural Damage Classification in a Jacket-Type Wind-Turbine Foundation Using Principal Component Analysis and Extreme Gradient Boosting, Sensors, 21, https://doi.org/10.3390/s21082748, 2021. a
Li, W., Zhao, W., Wang, T., and Du, Y.: Surface Defect Detection and Evaluation Method of Large Wind Turbine Blades Based on an Improved Deeplabv3+ Deep Learning Model, Structural Durability & Health Monitoring, 18, 553, https://doi.org/10.32604/sdhm.2024.050751, 2024. a
Li, W., Zhao, W., and Du, Y.: Large-scale wind turbine blade operational condition monitoring based on UAV and improved YOLOv5 deep learning model, Mech. Syst. Signal Pr., 226, 112386, https://doi.org/10.1016/j.ymssp.2025.112386, 2025. a
Liu, H., Wang, Y., Zeng, T., Wang, H., Chan, S.-C., and Ran, L.: Wind turbine generator failure analysis and fault diagnosis: A review, IET Renewable Power Generation, 18, 3127–3148, https://doi.org/10.1049/rpg2.13104, 2024. a
Machado, M.: iMOSS-Lab/rp-wedowind-challenge-ASCE-EMI: v1, Version v1, Zenodo [code], https://doi.org/10.5281/zenodo.18940555, 2026. a
Machado, M. and Dutkiewicz, M.: Wind turbine vibration management: An integrated analysis of existing solutions, products, and Open-source developments, Energy Reports, 11, 3756–3791, https://doi.org/10.1016/j.egyr.2024.03.014, 2024. a
Meyer, A.: Vibration Fault Diagnosis in Wind Turbines Based on Automated Feature Learning, Energies, 15, https://doi.org/10.3390/en15041514, 2022. a
Milani, S., Leoni, J., Cacciola, S., Croce, A., and Tanelli, M.: A machine-learning-based approach for active monitoring of blade pitch misalignment in wind turbines, Wind Energ. Sci., 10, 497–510, https://doi.org/10.5194/wes-10-497-2025, 2025. a
Morozovska, K., Bragone, F., Svensson, A. X., Shukla, D. A., and Hellstenius, E.: Trade-offs of wind power production: A study on the environmental implications of raw materials mining in the life cycle of wind turbines, J. Clean. Prod., 460, 142578, https://doi.org/10.1016/j.jclepro.2024.142578, 2024. a
Mousavi, Z., Varahram, S., Ettefagh, M. M., Sadeghi, M. H., Feng, W.-Q., and Bayat, M.: A digital twin-based framework for damage detection of a floating wind turbine structure under various loading conditions based on deep learning approach, Ocean Eng., 292, 116563, https://doi.org/10.1016/j.oceaneng.2023.116563, 2024. a
Movsessian, A., Cava, D. G., and Tcherniak, D.: Interpretable Machine Learning in Damage Detection Using Shapley Additive Explanations, ASCE-ASME J. Risk and Uncert. in Engrg. Sys. Part B Mech. Engrg., 8, 021101, https://doi.org/10.1115/1.4053304, 2022. a
Nguyen, C. U., Huynh, T. C., and Kim, J. T.: Vibration-based damage detection in wind turbine towers using artificial neural networks, Structural Monitoring and Maintenance, 5, 507–519, https://doi.org/10.12989/smm.2018.5.4.507, 2018. a
Praveen, H. M., Sabareesh, G., Inturi, V., and Jaikanth, A.: Component level signal segmentation method for multi-component fault detection in a wind turbine gearbox, Measurement, 195, 111180, https://doi.org/10.1016/j.measurement.2022.111180, 2022. a
Regan, T., Beale, C., and Inalpolat, M.: Wind Turbine Blade Damage Detection Using Supervised Machine Learning Algorithms, J. Vib. Acoust., 139, 061010, https://doi.org/10.1115/1.4036951, 2017. a
Ren, L. and Yong, B.: Wind Turbines Fault Classification Treatment Method, Symmetry, 14, https://doi.org/10.3390/sym14040688, 2022. a
Sharma, S. and Nava, V.: Condition monitoring of mooring systems for Floating Offshore Wind Turbines using Convolutional Neural Network framework coupled with Autoregressive coefficients, Ocean Eng., 302, 117650, https://doi.org/10.1016/j.oceaneng.2024.117650, 2024. a
Smarsly, K., Dragos, K., Chowdhury, S., and Wiggenbrock, J.: Machine learning algorithms for structural health monitoring. 8th European Workshop on Structural Health Monitoring (EWSHM 2016), 5–8 July 2016, Bilbao, Spain, e-Journal of Nondestructive Testing, 21, https://www.ndt.net/?id=19828, 2016. a
Song, F., Han, Y., William Heath, A., and Hou, M.: Structural damage detection of floating offshore wind turbine blades based on Conv1d-GRU-MHA network, Eng. Fail. Anal., 166, 108896, https://doi.org/10.1016/j.engfailanal.2024.108896, 2024. a
Tang, X., Huang, W., Li, X., and Ma, G.: Prediction of mooring tension of floating offshore wind turbines by CNN-LSTM-ATT and Chebyshev polynomials, Ocean Eng., 331, 121327, https://doi.org/10.1016/j.oceaneng.2025.121327, 2025. a
Thomas, D.: Unveiling Wind Turbine Failures Causes, Detection, and Prevention for Enhanced Reliability, Journal of Failure Analysis and Prevention, 24, 2051–2053, https://doi.org/10.1007/s11668-024-02026-1, 2024. a
Tsiapoki, S., Häckell, M. W., Grießmann, T., and Rolfes, R.: Damage and ice detection on wind turbine rotor blades using a three-tier modular structural health monitoring framework, Struct. Health Monit., 17, 1289–1312, https://doi.org/10.1177/1475921717732730, 2018. a
Veers, P., Bottasso, C. L., Manuel, L., Naughton, J., Pao, L., Paquette, J., Robertson, A., Robinson, M., Ananthan, S., Barlas, T., Bianchini, A., Bredmose, H., Horcas, S. G., Keller, J., Madsen, H. A., Manwell, J., Moriarty, P., Nolet, S., and Rinker, J.: Grand challenges in the design, manufacture, and operation of future wind turbine systems, Wind Energ. Sci., 8, 1071–1131, https://doi.org/10.5194/wes-8-1071-2023, 2023. a
Vidal, Y., Aquino, G., Pozo, F., and Gutiérrez-Arias, J. E. M.: Structural Health Monitoring for Jacket-Type Offshore Wind Turbines: Experimental Proof of Concept, Sensors, 20, https://doi.org/10.3390/s20071835, 2020. a
Vives, J.: Vibration analysis for fault detection in wind turbines using machine learning techniques, Adv. Intell. Soft. Comp., 2, 1–12, https://doi.org/10.1007/s43674-021-00029-1, 2022. a
Vives, J., Roses Albert, E., Quiles, E., Palací, J., and Fuster, T.: Vibration Analysis for Fault Detection of Wind Turbines by Combining Machine-Learning Techniques and 3D Scanning Laser, Genet. Res., 2022, https://doi.org/10.1155/2022/2093086, 2022. a
Wang, S., Vidal, Y., and Pozo, F.: Recent advances in wind turbine condition monitoring using SCADA data: A state-of-the-art review, Reliab. Eng. Syst. Safe., 267, 111838, https://doi.org/10.1016/j.ress.2025.111838, 2026. a
Zarrin, P. S., Martin, C., Langendoerfer, P., Wenger, C., and Diaz, M.: Vibration Analysis of a Wind Turbine Gearbox for Off-cloud Health Monitoring through Neuromorphic-computing, IECON Proceedings (Industrial Electronics Conference), 2021-October, https://doi.org/10.1109/IECON48115.2021.9589879, 2021. a
Zhang, S., Wang, T., Worden, K., Sun, L., and Cross, E. J.: Canonical-correlation-based fast feature selection for structural health monitoring, Mech. Syst. Signal Pr., 223, 111895, https://doi.org/10.1016/j.ymssp.2024.111895, 2025. a, b
Zhao, W., Li, W., and Du, Y.: Wind turbine blade rotational condition monitoring based on RBs-YOLO deep learning model, Mech. Syst. Signal Pr., 230, 112641, https://doi.org/10.1016/j.ymssp.2025.112641, 2025. a