the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 28 Feb 2020
| 28 Feb 2020
How to improve the state of the art in metocean measurement datasets
Erik Quaeghebeur
We present an analysis of three datasets of 10 min metocean measurement statistics and our resulting recommendations to both producers and users of such datasets. Many of our recommendations are more generally of interest to all numerical measurement data producers. The datasets analyzed originate from offshore meteorological masts installed to support offshore wind farm planning and design: the Dutch OWEZ and MMIJ and the German FINO1. Our analysis shows that such datasets contain issues that users should look out for and whose prevalence can be reduced by producers. We also present expressions to derive uncertainty and bias values for the statistics from information typically available about sample uncertainty. We also observe that the format in which the data are disseminated is sub-optimal from the users' perspective and discuss how producers can create more immediately useful dataset files. Effectively, we advocate using an established binary format (HDF5 or netCDF4) instead of the typical text-based one (comma-separated values), as this allows for the inclusion of relevant metadata and the creation of significantly smaller directly accessible dataset files. Next to informing producers of the advantages of these formats, we also provide concrete pointers to their effective use. Our conclusion is that datasets such as the ones we analyzed can be improved substantially in usefulness and convenience with limited effort.
- Article
(2637 KB) - Full-text XML
-
Supplement
(22236 KB) - BibTeX
- EndNote





The planning and design of offshore wind farms depends heavily on the availability of representative meteorological and ocean or “metocean” measurement data. For example, the wind resource (the wind speed and direction distribution) at the candidate farm location is used to estimate energy production over the farm's lifetime, and information about ocean waves is needed for wind turbine support structure design and planning installation and maintenance.
The data are collected by instruments placed on fixed offshore platforms, met masts, or measurement buoys deployed in measurement campaigns. These campaigns are ordered by the project owner (a government or a farm developer) and set up and carried out by contractors (applied research institutes or companies). The dataset producer (one or more of the contractors) collects and processes the data generated in these campaigns and provides them to dataset users. The datasets produced are often available publicly to these users, although usually with some access and usage restrictions, especially for commercial purposes.
We became interested in evaluating metocean measurement datasets after encountering a number of issues in a specific dataset, both in data quality and in the dissemination format. (Our concrete purpose was to use it for wind farm energy production estimation.) Discussion with other users of such datasets showed that many found the typical dissemination approach, providing multiple files with comma-separated values, to be inconvenient or even a hindrance to their application. Most were not aware of the data quality issues we encountered, which can be categorized as faulty data, missing documentation, inappropriate statistic selection, limited data quality information, and sub-optimal value encoding.
Therefore, we performed a study of three commonly used metocean datasets to answer essentially the following questions. (i) Are these issues commonly shared in metocean datasets? (ii) How can the issues that are present be addressed? This paper reports the results of that study. In brief, (i) yes, there are shared issues, but, not unexpectedly, not all of them in all datasets, and (ii) dataset producers can address the issues with a few non-burdensome additions to their creation practice. Next to providing arguments for and detailing these conclusions, this paper is meant to raise awareness of the issues mentioned by giving concrete examples. Furthermore, it provides dataset producers with concrete ideas about how to achieve substantial improvements with reasonable effort.
The users of the produced datasets are of course the farm developers, but also the academic world, whose usage is not necessarily restricted to wind energy applications. The context of our academic research is offshore wind energy, but the work we present here is relevant outside that area as well. Therefore, we treat all measured quantities on equal footing and do not focus on wind and wave data. When our discussion goes beyond the analysis of the specific datasets we considered, it is also mostly independent of their metocean nature but generally applies to any numerical time series data.
We structure the paper into two main sections. We start with an essentially descriptive Sect. 2, to give an overview of the datasets we considered and to identify the issues we encountered. The original contributions here are our thorough description, in-depth analysis, and expressions of the uncertainties and bias in the statistics' values that make up the datasets. In this section we also mention options for addressing issues described, where it can be done compactly and where we believe it adds value for dataset producers. In the instructional Sect. 3 we discuss how the format of these datasets can be improved and thereby disseminated more conveniently. This section includes an up-to-date evaluation of binary dataset file format functionality. The recommendations to project owners, dataset producers, and users that follow from these analyses are collected at the end of this paper (Sect. 4), preceding the overall conclusions (Sect. 5).
We split our discussion of the datasets into two parts: first, in Sect. 2.1, we present the three datasets in terms of context and content, and then, in Sect. 2.2, we go over the issues we encountered.
2.1 A first look at the datasets
All three datasets we consider come from measuring masts in the North Sea and contain multiple multi-year 10 min statistics data, called “series”. These 10 min statistics are derived from higher-frequency measurements, called “signals”, of quantities measured by various instruments at various locations on the mast. The available statistics are the sample minimum, maximum, mean, and standard deviation.
For each dataset, we give a brief description of the measurement site and setup, list the measurement period and quantities measured, describe the dissemination approach, point to available documentation, and highlight some further important aspects. We do this in full detail here for the first dataset, but for the other two we put aspects that are not substantively different in Appendix A1. We also provide a brief FAIRness analysis (Wilkinson et al., 2016) of the datasets in Appendix A1.3.
Common to all three datasets is that they can be downloaded from a website, where some documentation is available. But, also for all three, we needed to look up external sources and contact parties involved in the dataset creation process to get a more complete view. The collected metadata are available as part of a separate bundle (Quaeghebeur, 2020). It also includes details not mentioned in this paper, such as the make and type of instruments and loggers.
2.1.1 OWEZ – offshore wind farm Egmond aan Zee
To gather data before and after construction of the offshore wind farm Egmond aan Zee (OWEZ; “Offshore Windpark Egmond aan Zee” in Dutch), a met mast was built on-site. Its location is 52∘36′22.9′′ N, 4∘23′22.7′′ E (WGS 84), which is 15 km off the Dutch coast near the town Egmond aan Zee. The location is indicated in Fig. 1. The mast was erected in 2003 and construction of the wind farm started in 2006. Data are publicly available for the period July 2005–December 2010. The instruments used and quantities measured and some of their characteristics are listed in Table 1.
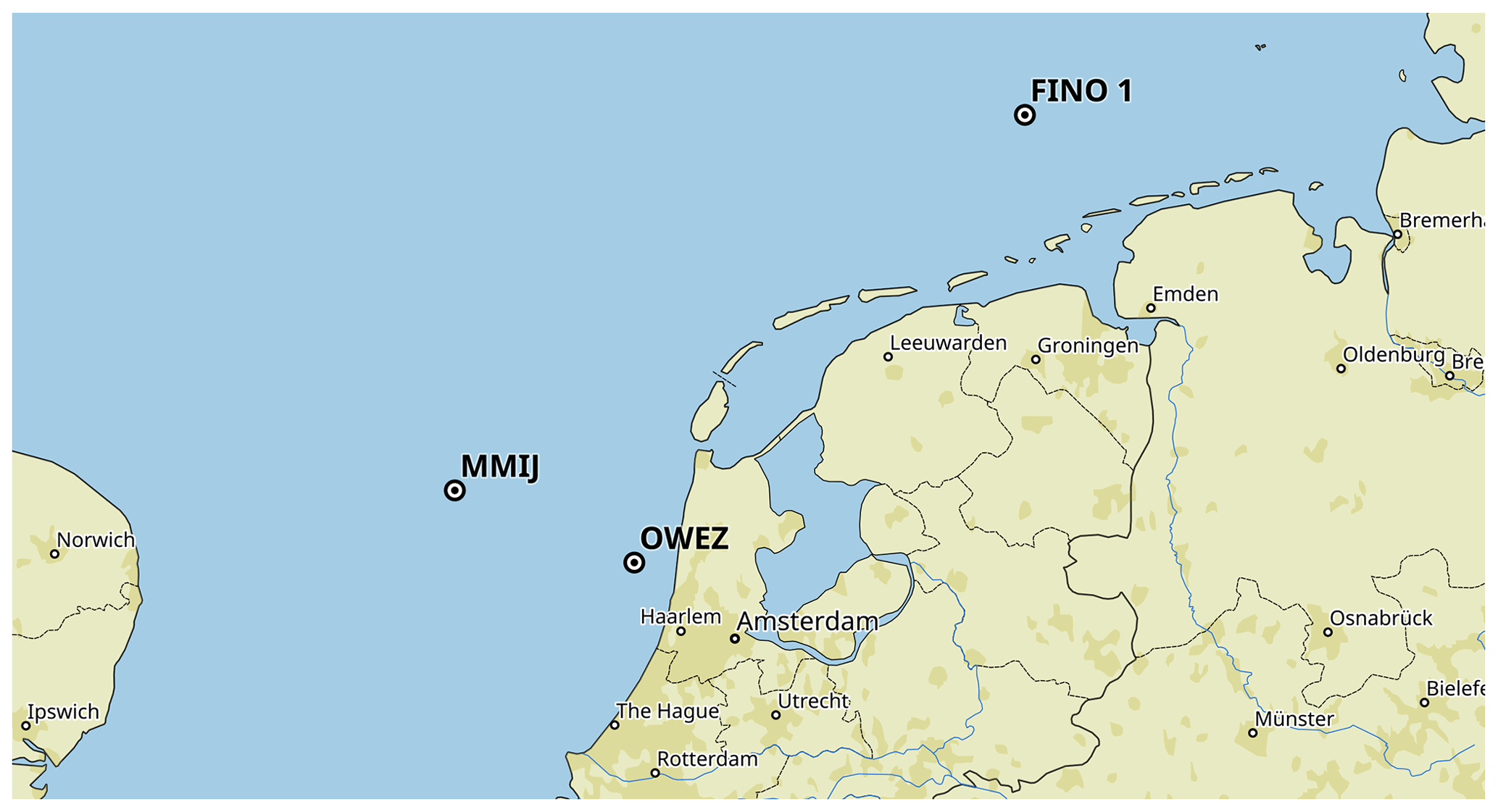
Figure 1A map with the location of the three offshore met masts from which data were analyzed: OWEZ, MMIJ, and FINO1.
Table 1An overview of the instruments and their locations on the OWEZ met mast (height in meters above mean sea level and boom orientation), the quantity measured, measurement uncertainty, the measurement ranges, and the sampling frequencies.
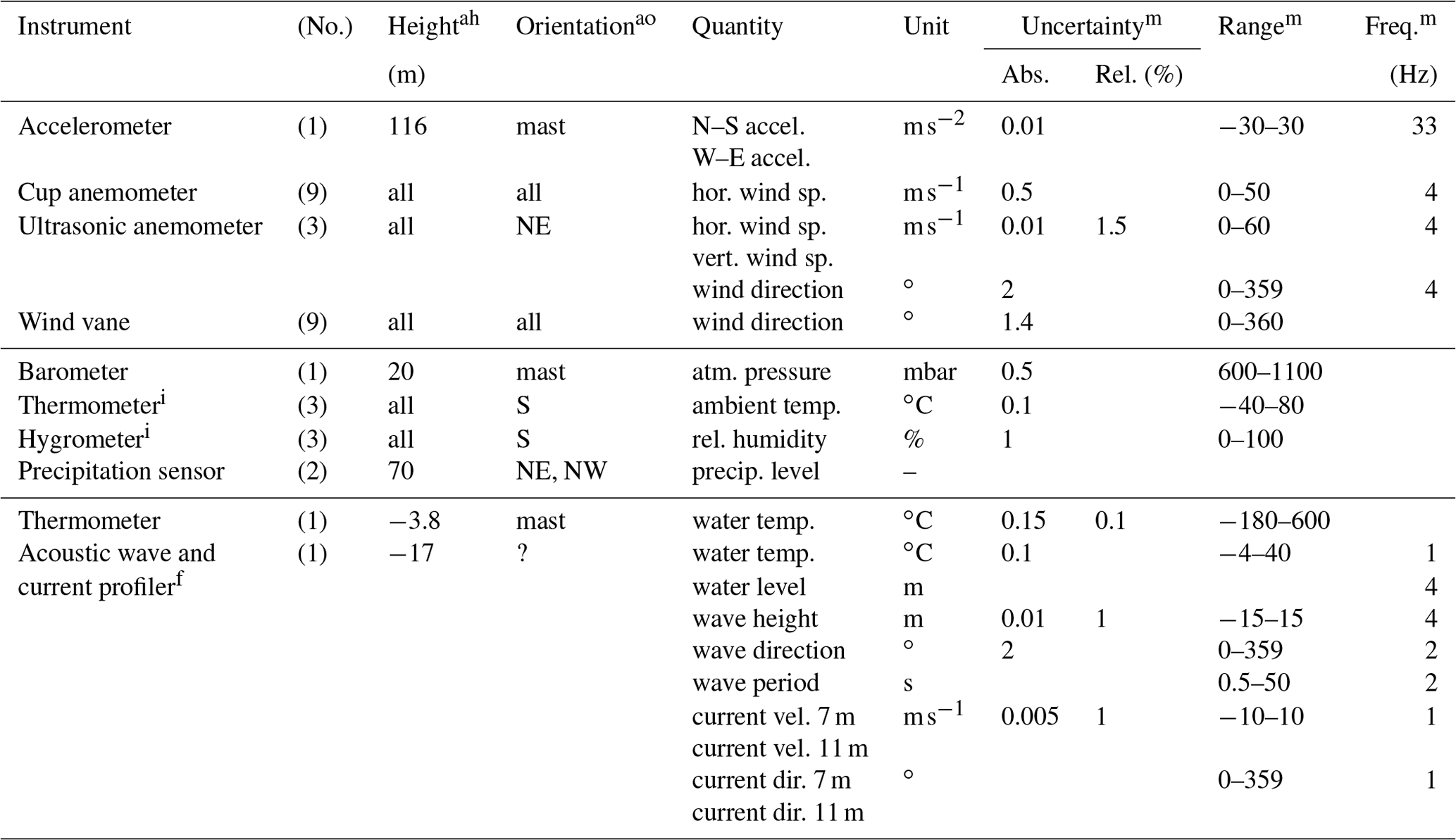
ah For height, “all” corresponds to 21, 70, and 116 m.
ao For orientation, “all” corresponds to NE, NW, and S or −60∘, 60∘, and 180∘, respectively (north corresponding to 0∘).
i Thermometer and hygrometer are contained in a single package.
f The given sampling frequencies are upper bounds.
m Missing values are unknown.
Due to an agreement between the Dutch government and the OWEZ developer, data gathered and reports written in the context of the wind farm's construction have been made publicly available. This is done through a website where these materials can be downloaded (NoordzeeWind, 2019). The metocean dataset can be downloaded as 66 separate monthly compressed Excel (xls) spreadsheet files. The total size is almost 1 GB, or about 400 MB compressed. This represents data points for 289 296 10 min intervals. The data in each file are structured as follows:
-
six date–time columns (year, month, day, hour, minutes, seconds);
-
48 “channels” of five columns each: an integer identifier “Channel” and four real-valued statistics, “Max”, “Min”, “Mean”, and “StdDev”, with each channel corresponding to a specific measured quantity and location on the mast.
In the Excel files, the statistics' values are encoded as 8 B (byte) binary floating point numbers.
Information about the dataset, the met mast, and its context is available through the same website. In particular, there is a user manual (Kouwenhoven, 2007) and several reports from which further information can be learned (e.g., Curvers, 2007; Eecen and Branlard, 2008; Wagenaar and Eecen, 2010a, b). Information about the instruments used and in particular the measurement uncertainty had to be looked up in specification sheets or obtained through personal communication with people involved in the project (see Acknowledgements).
2.1.2 MMIJ – measuring mast IJmuiden
The second dataset, “MMIJ”, comes from a met mast in the Dutch part of the North Sea. The location is indicated in Fig. 1. Details can be found in Appendix A1.1.
The exact set of signals differs of course from the OWEZ dataset; we have given an overview in Table A1 in the appendix.
The data were collected during the period 2011–2016, a period of time comparable in length to OWEZ.
The dataset is made available as a single semicolon-separated-value (csv) file, and the statistics' values are encoded in a decimal fixed-point format with five fractional digits (x...x.xxxxx).
2.1.3 FINO1 – research platform in the North Sea and the Baltic Sea Nr. 1
The third dataset, “FINO1”, comes from a met mast in the German part of the North Sea. The location is indicated in Fig. 1. Details can be found in Appendix A1.2.
The exact set of signals again differs from the OWEZ dataset; we have given an overview in Table A2 in the appendix.
The data investigated were collected during the period 2004–2016, so a period of time more than twice as long as for the other two datasets.
A difference with the other two datasets is that not all statistics are available for all signals.
Also, it is free for academic research purposes but not for commercial use, in contrast to the two other datasets.
The dataset is made available as a set of tab-separated-value (dat) files, and the statistics' values are encoded in a decimal fixed-point format with up to two fractional digits (x...x.xx).
For each quantity, a quality column is included next to the statistics' columns.
2.2 Dataset issues
We split the issues encountered in the datasets into five categories each discussed in their own section: faulty data (Sect. 2.2.1), documentation (Sect. 2.2.2), statistic selection (Sect. 2.2.3), quality flags (Sect. 2.2.4), and value encoding and uncertainty propagation (Sect. 2.2.5).
2.2.1 Faulty data
It is not unusual that the measured signals (raw data) contain faulty data. With this we mean data values that cannot correspond to the actual values or are very unlikely to correspond to them. The dataset producers deal with such faulty data, e.g., by flagging or removing it, when creating the datasets of statistics series we study. Nevertheless, each of the three datasets presented above contained remaining faulty data. We stumbled upon initial examples, but then systematically looked for issues.
To facilitate this systematic and partly automated investigation, we created binary file format versions of the datasets (HDF5 format for OWEZ and netCDF4 format for MMIJ and FINO1) in which metadata such as range and possible values can be stored alongside the data themselves. We discuss these formats in more detail in Sect. 3. The automation essentially consisted of looping over all signals and statistics to detect issues; further investigation was done manually.
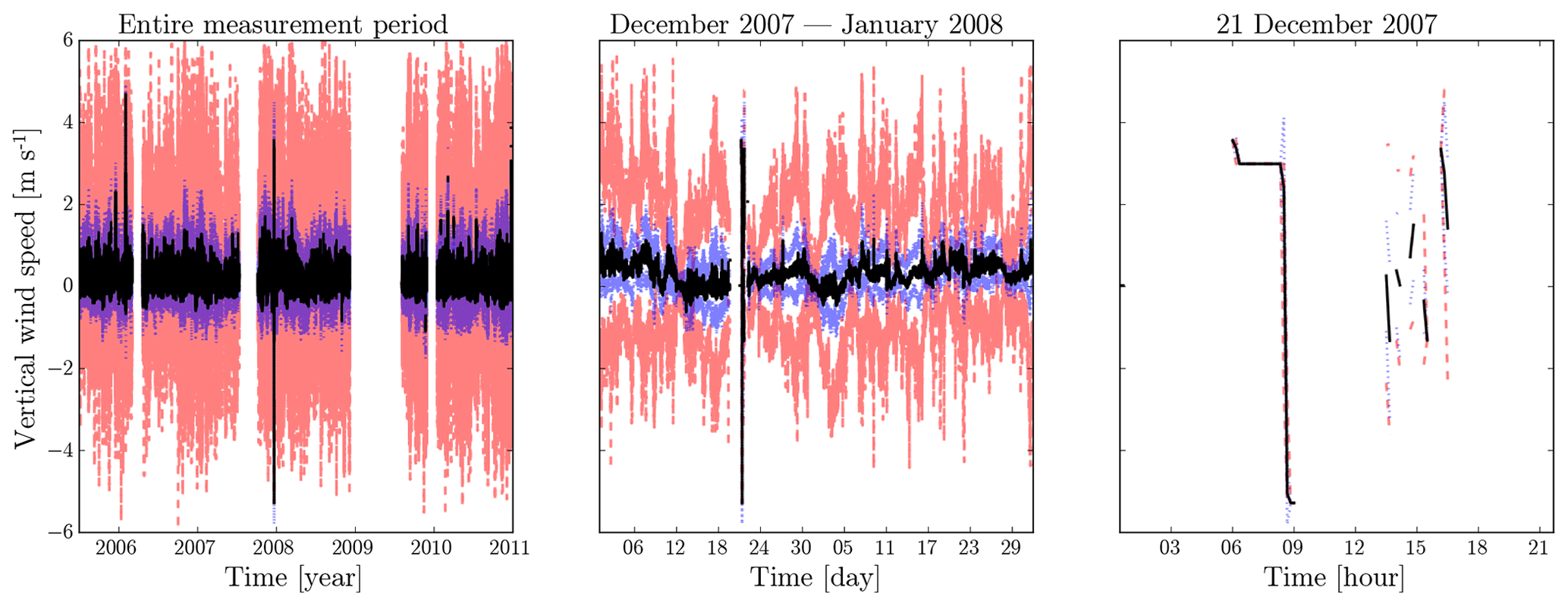
Figure 2An illustration of the visual inspection and zooming of plots. We present the OWEZ vertical wind speed data collected by the ultrasonic anemometer at the NE-116 m location. (Mean in black; mean ± standard deviation in blue; minimum and maximum in red.)
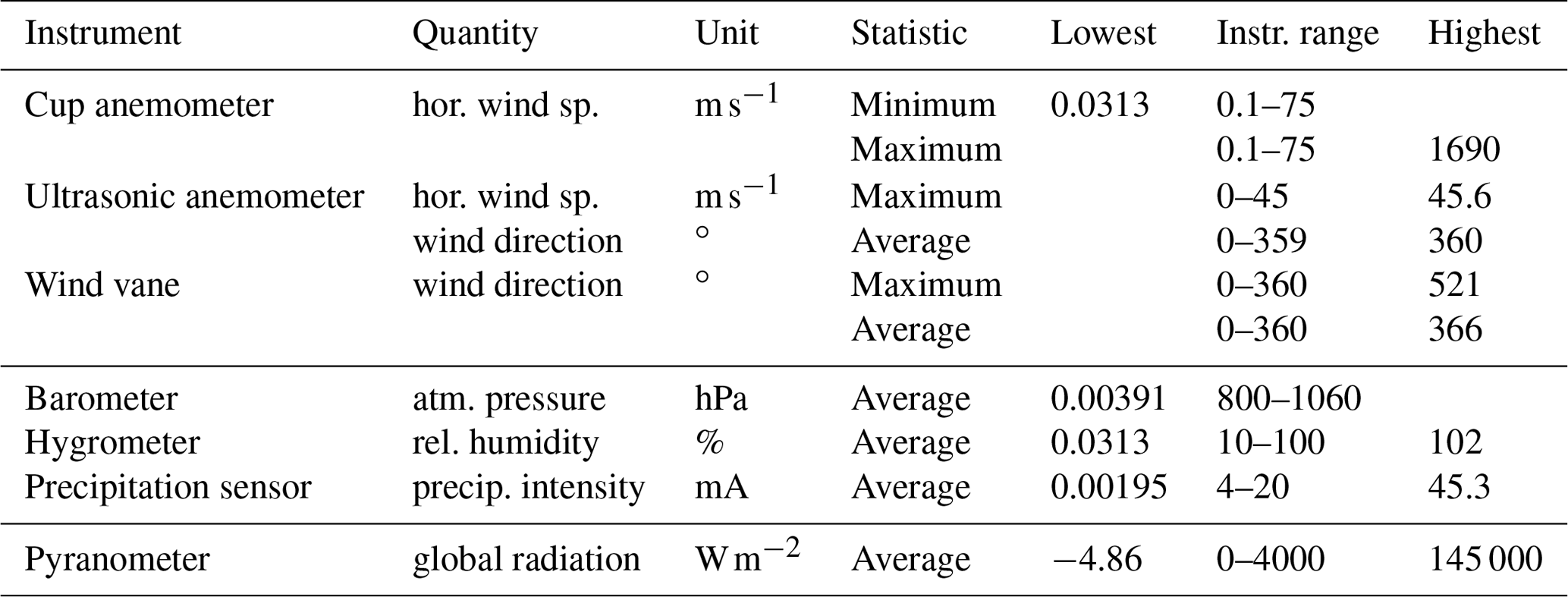
Table 2An overview of the (largest) range violations present in the FINO1 dataset. (Values rounded to three digits.)
More concretely, our procedure was as follows.
-
We performed interactive visual inspection of plots of the individual datasets, including zooming in on suspicious-looking parts. Figure 2 provides an example. The plots should be read as follows: the mean value is given by the “inner” full (black) line; mean values plus and minus 1 standard deviation are given by the “intermediate” dotted (blue) lines; minima and maxima are given by the “outer” dashed (red) lines. The plots in this figure are snapshots of an interactive visualization procedure: even though the lines overlap in the unzoomed left-hand plot, an anomalous extreme mean value is visible around the 2007–2008 year change. Zooming in a bit gives the middle plot, where the statistics start becoming visually separated and where the anomaly stands out even more. Zooming in further gives the right-hand plot, which shows that many missing values surround the anomaly, further suggesting that the values still present here may not be reliable. (We do not know why the surrounding values are missing.)
-
We ran automated checks for values outside the instrument's range for the series or for inconsistent sets of statistics' values. Let us clarify what inconsistent sets of statistics' values are. Statistic values imply bounds on the value of other statistics. If such a constraint is violated for some 10 min interval, the tuple of statistics (minimum , maximum , mean , standard deviation sx) for that interval is inconsistent. For example, it should be the case that ; violations of this constraint are present, e.g., in the FINO1 cup anemometer wind speed data. Less obvious constraints involving the sample standard deviation also exist. We used as the general upper bound for the standard deviation, given that the values lie in the interval (Shiffler and Harsha, 1980). (Here and can be replaced by range bounds in case the minimum and maximum statistics are not present in the dataset.) Any such inconsistency is a serious issue, as it indicates a deficiency somewhere in the procedures for calculating statistics and their post-processing.
As an example, the range violations in the FINO1 dataset gave the results listed in Table 2. Some range violations point to faulty data (e.g., cup anemometer–hor. wind sp.–max, where the value exceeds the bound by more than an order of magnitude), but others suggest a need for more elaborate uncertainty analysis (e.g., hygrometer–rel. humidity–avg., where the violating values probably correspond to the bounds) or more elaborate handling of the range bounds (e.g., wind vane–wind direction–max, where the upper bound could be increased; also see Appendix A2.1).
The code producing the results of Table 2 is publicly available (Quaeghebeur, 2020). The fact that our netCDF4 version of the dataset is (uniformly) structured and contains metadata allows the code to be generic, i.e., not variable-specific, and therefore compact.
-
We did checks of the occurring values, for quantities with a discrete number of possible values. One example is the synoptic code “max” values from the MMIJ precipitation monitor. The check showed the following values to be present.
Synoptic code values below 0 and above 99 do not exist (World Meteorological Organization, 2016, p. 356–358), so faulty data are present here. Only integer values are present here, but erroneous fractional values would also be detected. The code for performing this check is publicly available (Quaeghebeur, 2020).
-
We ran automated checks for outlier candidates. There can be both “classical” outliers, i.e., values outside the range typical for that series, and “dynamic” ones, i.e., subsequent value pairs whose difference (“rate of change”) lies outside the difference typical for that series's time variation. Both types of outliers can, but do not necessarily, correspond to faulty data.
In further manual analysis of outlier candidates, causes may be identified, providing feedback on the data collection and processing procedures. For example, in both the MMIJ and FINO1 datasets, we encountered sudden drops to the value zero for some series at regular time instances; this quite likely corresponds to foreseeable or detectable sensor resets of some kind.
There are many methods for outlier detection (Aggarwal, 2017). But, in this paper, we just wish to point out that there is a clear need for some form of outlier detection to be used in the creation of metocean 10 min statistics datasets. Namely, the datasets we analyzed would benefit enormously from even a basic analysis; we suspect this generalizes to other such datasets produced in the wind energy field. To make this need apparent, we present a set of plots in Figs. 3–6 that illustrates that indeed there are still outliers present in the datasets. We devised this type of plot as an alternative to lag-1 plots (which plot xk+1 versus xk), so that rate-of-change magnitudes can be read off directly.
These plots, of which examples are given in Figs. 3–6, should be read as follows. The horizontal x axis shows measurement value; the vertical y axis shows the absolute value of the mean of the differences with the preceding and next measurement values. Each dot corresponds to a measurement. Lines connect successive measurements. Only those measurements are shown with an x percentile outside [0.1,99.9] or a y percentile above 99, so the brunt of the measurements are not shown. (These bounds are somewhat arbitrary, but reasonable for the size of the datasets.) The y axis is linear until the 99th percentile and logarithmic above. To give an idea about the distribution of all the measurement points, so also the ones that are not shown, we add (blue) lines for specific fractiles: thick dashed for the median and thin dotted for . Thick full (red) lines are added as necessary to indicate range bounds.
In Fig. 3, there are some suspiciously high values, some even beyond the nominal measurement range of the instrument. This is also the case for the “Min” and “Mean” statistics, even if the probably isolated responsible data points are not visible. In Fig. 4, there are suspicious 0 % values and several values beyond 100 %. In Fig. 5, we see a cluster of data points at suspiciously low values and some impossibly fast 10 min pressure changes, a number of them more than 100 hPa. In Fig. 6, we see a quite large number of atypically high temperatures and some impossibly fast 10 min temperature changes, a couple of them of more than 30 ∘C.
Outlier plots for all data series are available in the Supplement for this paper. The code producing them is publicly available (Quaeghebeur, 2020).
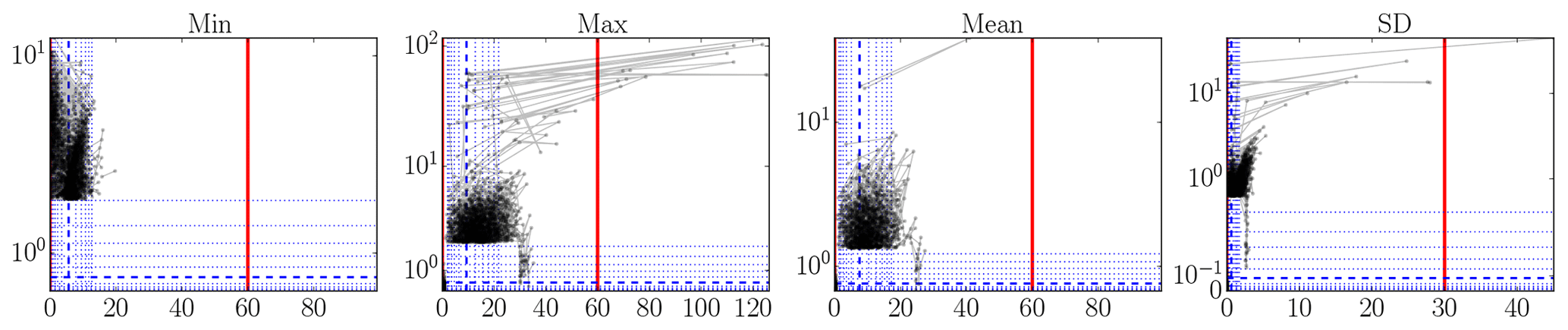
Figure 3Illustrative plots for visually identifying outliers (see text for an explanation): OWEZ 21 m NW ultrasonic anemometer horizontal wind speed data (m s−1).
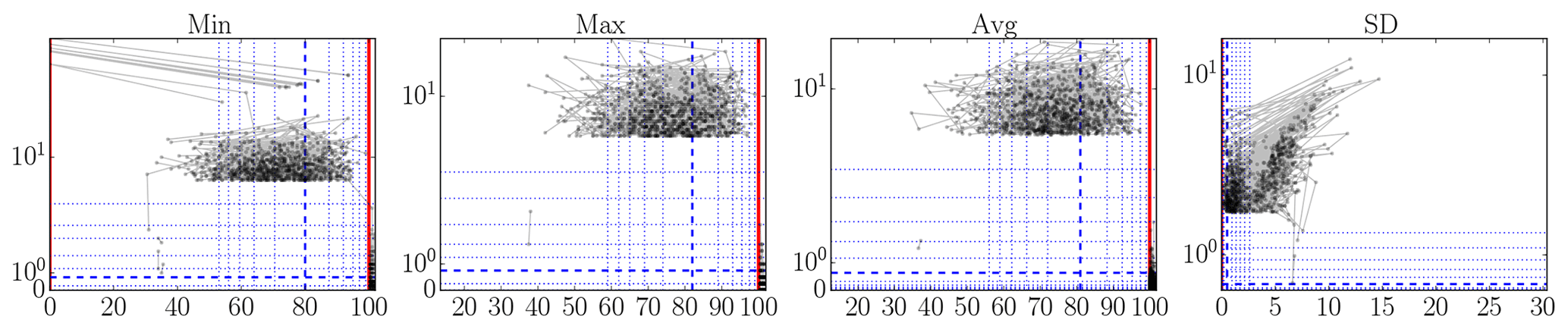
Figure 4Illustrative plots for visually identifying outliers (see text for an explanation): MMIJ 21 m relative humidity data (%).
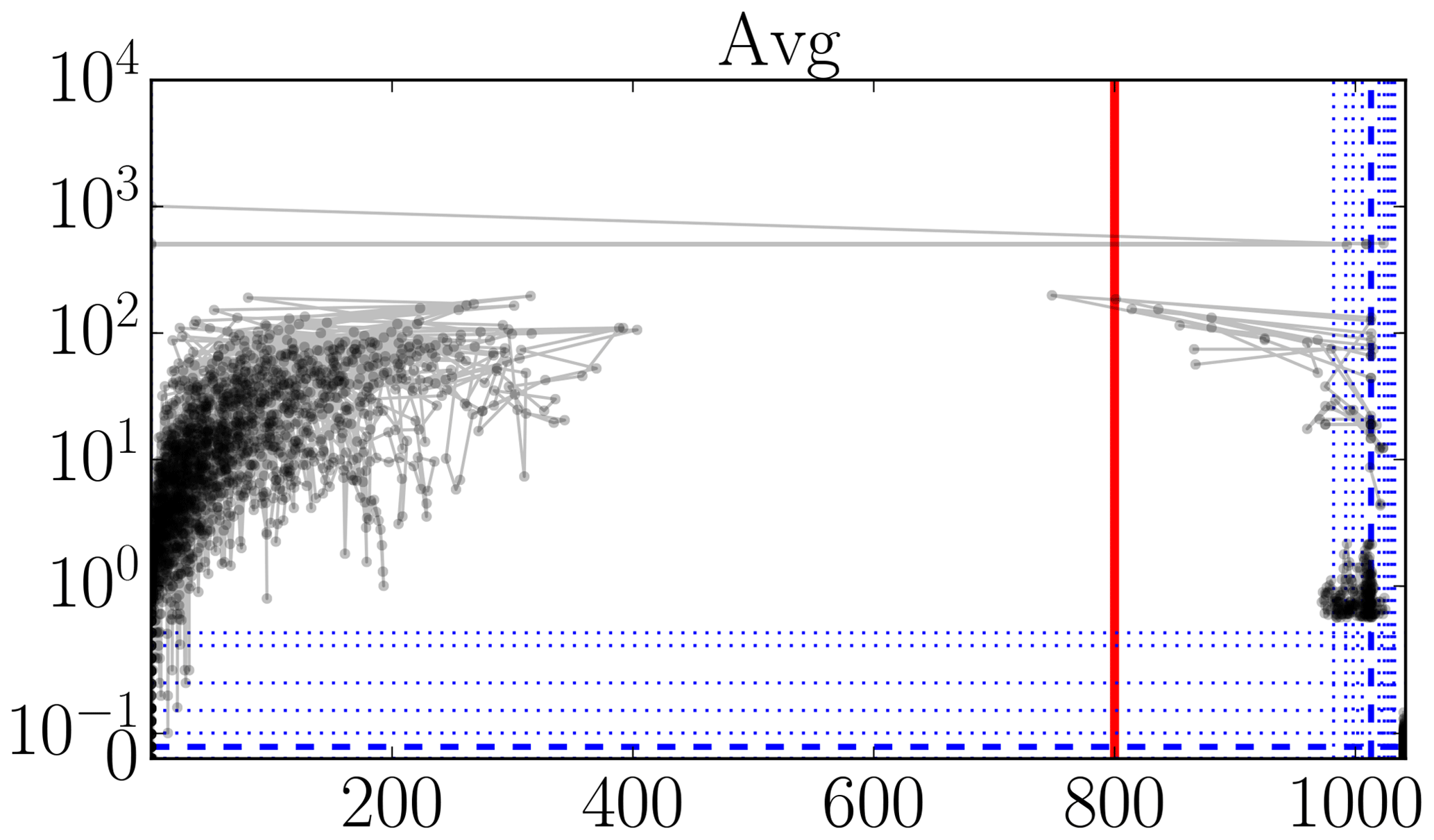
Figure 5Illustrative plots for visually identifying outliers (see text for an explanation): FINO1 21 m air pressure data (hPa).
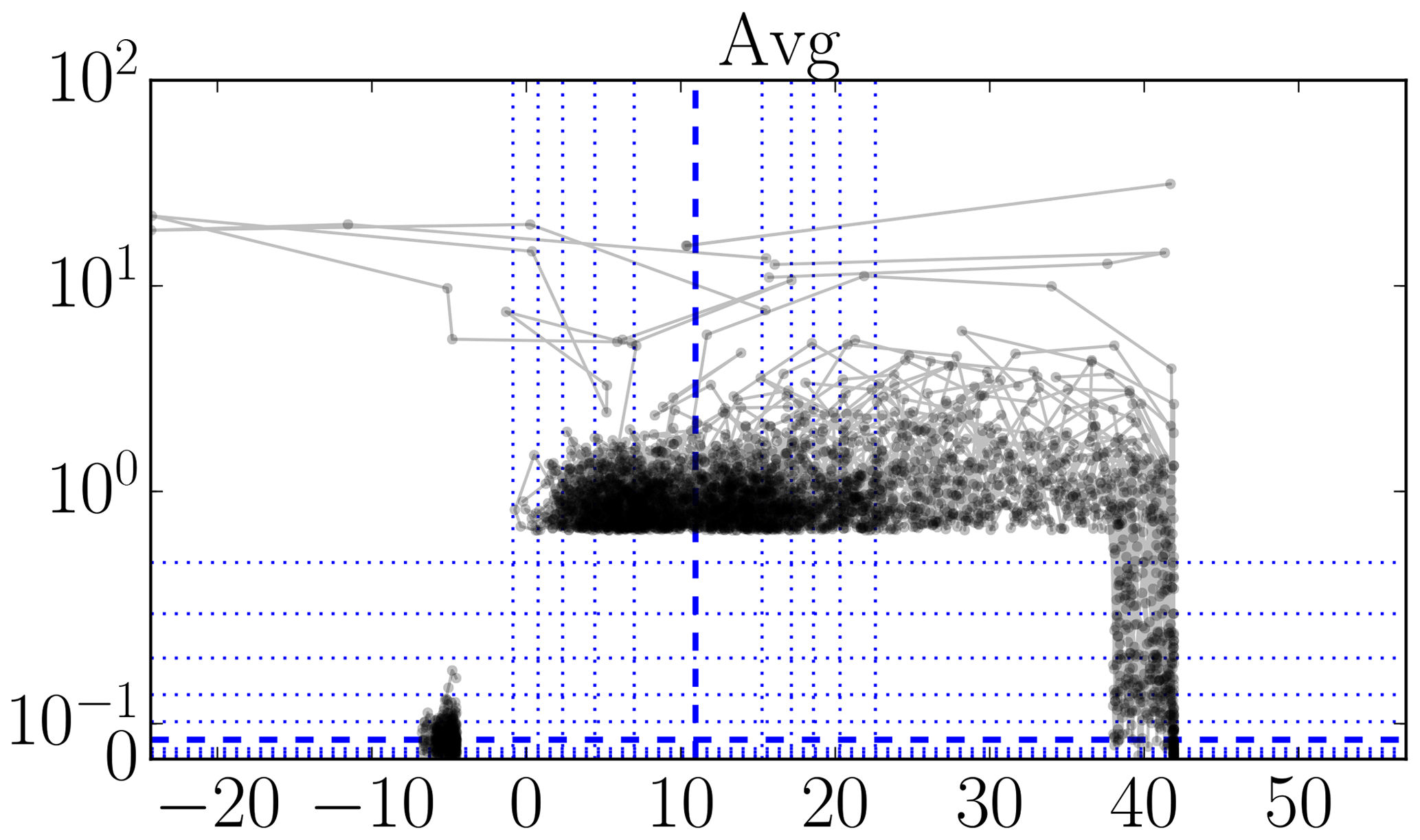
Figure 6Illustrative plots for visually identifying outliers (see text for an explanation): FINO1 72 m ambient temperature data (∘C).
Our analysis was generic in the sense that we did not make use of quantity-specific domain knowledge (e.g., empirical relationships between mean and maximum) or measurement-setup-specific knowledge (e.g., met mast influence on wind speed). In the context of wind resource assessment, Brower (2012) gives a description of a data validation procedure that does take into account such specifics. Meek and Hatfield (1994) proposed signal-specific rules for checking meteorological measurements for range violations, rate-of-change outliers, and no-observed-change occurrences.
For all of the issues presented in this section, the dataset producer is better placed to interpret them, given that they have information about the data acquisition and processing procedures that the user lacks. Therefore it is the dataset producer who would ideally identify such issues and fix them, if possible, or otherwise at least mask or flag them. Given, as illustrated, the relative simplicity of the required analyses, relatively little effort may be required for a substantial increase in dataset quality.
2.2.2 Documentation
As mentioned in Sect. 2.1, for each of the three datasets we investigated, documentation on the measurement setup, instruments, and quantities measured is available. Usually, this takes the form of a website, data manual, overview table, or a combination thereof. However, for purposes of interpretation and use of these datasets, some essential or potentially useful information is often missing.
We consider the information we listed in the overview Tables 1, A1, and A2 to be essential: instrument location, quantity measured, its unit, information about accuracy (e.g., by giving absolute and relative uncertainty)1, range, and, given our focus on statistics data, sampling frequency. For categorical data such as binary yes or no sensors (e.g., precipitation presence) or enumeration values (e.g., synoptic codes), range is of course replaced by a set of possible values and unit by a description of how to interpret those possible values.
How do the three datasets fare in terms of documentation?
- Timestamps
-
All data values are accompanied by timestamps spaced 10 min apart. However, for none of the three datasets is it mentioned whether this timestamp refers to the time of the first, last, or even some other sample. Knowing this is necessary for the precise combination of datasets. If we assume that the samples underlying the dataset start at the full hour, which corresponds to the raw data we have seen for OWEZ, we can deduce the convention used. Based on whether the first timestamp in a data file has “00” or “10” for its minutes value, we assume that OWEZ and MMIJ are first-sample based and FINO1 is last-sample based.
- Location
-
For all three datasets, the documentation about location was good to excellent: technical drawings of the mast with instrument locations or detailed data about orientation and height. (Pictures or video footage would of course further increase confidence in the accuracy of the drawings.) A small comment we can make here is that the location information in the series names used sometimes does not directly correspond to the actual situation. For example, in the MMIJ dataset a 46.5∘ angle offset of boom orientation relative to the (geographic) north needs to be accounted for and in the FINO1 dataset some height labels differed from the documented heights.
- Quantities and units
-
The description of the actual quantities measured and their units was in general also quite good. There were two clear exceptions. (i) The precipitation detector was completely omitted from the MMIJ documentation. (ii) Precipitation data from FINO1 at 23 m contained the concatenation of both presence (yes or no) and intensity data. Also, the interpretation of binary codes (e.g., does 0 correspond to yes or no?) was not explicitly given for any of the datasets, but had to be deduced from the data.
- Ranges
-
Ranges and sets of possible values were mostly left unmentioned in the documentation, except for those available in instrument data sheets included in the OWEZ and MMIJ data manuals. Making the data sheets of the instruments available in such a way turned out to be convenient, as tracking them down is, in our experience, not always possible.
- Accuracy1
-
Accuracy information was available in the FINO1 overview table and for those instruments for which the data sheet was included in the OWEZ and MMIJ data manuals. For the other signals, we had to rely on the information found in data sheets not available in the datasets' documentation or on their website. Entirely absent is a discussion of the impact on accuracy of all other aspects of the measurement setup (e.g., analog-to-digital conversion) and data processing (e.g., the application of calibration factors). Such a discussion would allow researchers using the datasets to get a more complete picture of the accuracy of the values in the datasets.
- Sampling frequency
-
The sampling frequencies were available in the documentation for MMIJ and FINO1, but not for OWEZ. This information is essential for the estimation of the uncertainty of the mean and standard deviation statistics (see Sect. 2.2.5).
- Instruments and their settings
-
We mentioned our use of data sheets a few times before. To find these when they are not included in the documentation, the exact instrument models need to be available. This was the case for all three datasets. However, this may not be enough: the measurement characteristics of some instruments (e.g., barometers) depend on specific settings, especially when they perform digital processing. These settings were never described. Furthermore, loggers are an essential piece of the measurement chain and therefore need to be documented as well. For MMIJ and FINO1 this is the case, but not for OWEZ.
- Data processing
-
Next to its relevance for assessing the accuracy of the values in the dataset, a good view of the data processing pipeline is important for other aspects as well.
-
When are data considered to be faulty and flagged in or omitted from the dataset accordingly? This is entirely missing for OWEZ and FINO1, but some information is given for MMIJ: if some values in a 10 min interval are missing, the corresponding statistics are marked as missing. How faulty data values are encoded is documented for OWEZ (as the value −999 999), but not for MMIJ and FINO1. For MMIJ, the convention used (the string “NaN”) seems to be used quite consistently, although some precipitation monitor outlier values might actually be other markers for faulty data. For FINO1, there are two main faulty data placeholder values easily identified from the datasets: −999.99 and −999. However, other values are also present, such as 0 and variants of the two main ones, such as 999, −999.9, and −1000.
-
How are the statistics calculated? This is never mentioned in the documentation. For most signals not much ambiguity can arise, as there is not much choice, being limited to a possible bias correction approach for the standard deviation. However, for directional data, it is very much pertinent which definition of mean and standard deviation have been used: arithmetic or directional mean, classical or circular standard deviation (see, e.g., Fisher, 1995).
-
Do the data processing steps to arrive at the statistics have any weaknesses, numerical or other? For example, in the FINO1 wind speed data, there appear max values that, suspiciously, are a factor of 10 or 100 times larger than the surrounding values. Leaving such things unexplained severely reduces the trust in the dataset.
-
It is clear from the above list that while already a good amount of information is available, quite a number of very useful pieces of information are missing. Many of these are available to the dataset producers, so again the quality of the datasets, now in terms of documentation, can be substantially improved with little effort relative to the whole of the measurement campaign.
Unmentioned as of yet is that essentially all the documentation for these datasets is provided in a way accessible to humans, but not in a machine-readable way. Much of the information described in the documentation can however be encoded as metadata in a standardized and machine-readable way. Metadata are discussed further in Sect. 3.1.
2.2.3 Statistic selection
As seen in the overview Sect. 2.1.1, 2.1.2, and 2.1.3, for all three datasets the statistics provided are essentially the same: minimum, maximum, mean, and standard deviation. Only for FINO1 are not all statistics included for all quantities. In this section, we are going to discuss these statistic selection choices, pointing out issues that arise from them.
The uniformity of the statistics provided is convenient when reading out the data, as it reduces the user's quantity-specific code. However, when the signal's values do not represent a (underlying) linear scale, providing the minimum, maximum, mean, and standard deviation does not make much sense; it may actually cause misinterpretation. This is usually the case for categorical signals, such as the MMIJ synoptic code signal. In such cases, other statistics must be chosen. For example, for binary quantities such as yes–no precipitation data, giving the relative frequency of just one of the two values captures all the information present in the typical set of four statistics.
As said, in the FINO1 dataset statistics are sometimes omitted, but mostly for other reasons. For quantities that are considered to be “slow-varying” (such as atmospheric pressure, ambient temperature, and relative humidity) only the mean has been recorded. However, next to the convenience of uniform sets of statistics, having multiple statistics for a measurement interval is useful for data quality assessment. (Possible storage and transfer constraints are of course valid reasons for limiting the number of statistics.) For directional quantities such as wind direction, the minimum and maximum were omitted because these are considered meaningless by the dataset producer.2 The OWEZ and MMIJ datasets show, however, that it is possible to give meaningful definitions of maximum and minimum for directional data. (See Appendix A2.1 for a concrete approach.) This can be valuable information, as it makes it possible to deduce, for example, the sector extent from which the wind has blown during a time interval.
2.2.4 Quality flags
Next to statistics, we saw in Sect. 2.1.3 that the FINO1 dataset also contains a categorical quality flag for each set of statistics. Such information is not present in the other two datasets.
Including such a flag makes it possible to also provide information about missingness, i.e., to indicate why one or more statistic values are missing at that time instant. Such information is often encoded using a bit field, i.e., a binary mapping from quality issues and missingness mechanisms to true (1) and false (0); this bit field can be recorded as a positive integer. For example, consider the following tuple of quality issues and missingness mechanisms: (“suspect value jumps”, “out-of-range values”, “unknown missingness mechanism”, “icing”, “instrument off-line”). Then the bit string “00000” (or integer 0) would denote a measurement interval without any (identified) issues and for example “010010” (or integer 18) would correspond to a measurement interval with both instrument icing and out-of-range values detected.
Of course other information next to missingness mechanisms can be included in the quality flag bit field, also for non-missing values, as is done for FINO1. For example, this can be used to indicate possibly faulty data (see Sect. 2.2.1) that have not been removed (made missing).
2.2.5 Value encoding and uncertainty propagation
In the overview Sect. 2.1.1, 2.1.2, and 2.1.3, for all three datasets, the values themselves are encoded as fixed-point values for MMIJ and FINO1 and as a binary floating point double for OWEZ. There is, however, more to be said about what exactly is encoded and which information can be reflected in the encoding. We do that here.
Signal values have a natural set they belong to. Relative humidity, for example, is a fraction, i.e., a value between zero and 1. Categorical signals take values in a predefined enumerated set. If for such signals values are given outside of this set, this is a source of confusion: the user may wonder whether they can just round erroneous values to the nearest enumerated one or treat them as faulty. For example, the MMIJ precipitation detector's precipitation presence signal contains values around the enumerated ones and its precipitation monitors' precipitation presence signals contains values far outside the range of enumerated values. Another case are continuous signals that are at one point expressed as current or voltage values: the end user will be less certain about the correct translation procedure to the correct units than the data processor. For example, the FINO1 precipitation intensity signal is expressed as a current instead of an accumulation speed.
In the OWEZ and FINO1 datasets it sometimes occurs that certain statistics are marked as faulty or missing, while nevertheless other statistics for the same signal at the same instance are available. From inspection of such data, it is clear that it can happen that the values of these other statistics seem reasonable or faulty. An explanation of why the data values are partly missing would preserve trust in the non-missing values. This requires a description of the processes creating such a situation (see Sect. 2.2.2), but could also include instance-specific information in a flag value (see Sect. 2.2.4).
The values stored in the dataset do not in general encode their accuracy. For the MMIJ and FINO1 datasets, values used a fixed-point format, but the number of decimal digits used is not directly related to the accuracy information available for the different quantities. This fact may be overlooked by users, resulting in possible misinterpretations.
To avoid misinterpretation, it is possible to add an estimate for a value's uncertainty, e.g., by rounding and specifying a corresponding number of significant digits. Accuracy information was only available for signal values (i.e., high-frequency samples), typically as absolute uncertainties εa and relative uncertainties εr. Below, we give expressions for propagating this information to the statistics, as these do not seem available in the literature, and we discuss further factors affecting the statistics' uncertainty. The nontrivial derivations of these expressions and a description of the underlying model for the measurement process can be found in Appendix A2.2. The most important assumption made in these derivations is that , where n is the number of samples per averaging interval.
Sample uncertainties can be propagated to the statistics of the n signal values xk per averaging interval, which is 10 min for the datasets discussed in this paper. For this, we essentially assume independence and normality of the corresponding uncertainties . Also, the uncertainty in the statistics due to the finite nature of the samples can be quantified based on the fact that the sum appearing in the calculation of the mean and standard deviation can be seen as a simple form of quadrature. Let and be the minimum and maximum values in the sample; let and be the sample mean and sample variance. We find the following expressions for the squared uncertainties of the statistics:
Here ; in case and are unavailable, can be used instead, where is the standard normal quantile for exceedance probability 1∕n. The uncertainty due to the finite sample size, the term , diminishes much faster as a function of n than the uncertainty due to the measurement noise, expressed by the other terms. In practice, this second term is therefore negligible unless εa and εr are taken to be zero because no information is available about them.
Next to having associated uncertainties, the sample statistics can also be biased estimators of the statistics for the underlying signal. It turns out that only the sample standard deviation sx is biased and that
would be a better estimate from this perspective.
To get a more concrete view of these uncertainties and bias, we provide average relative uncertainty and bias values for the MMIJ dataset in Table 3. (The code producing the results of this table is publicly available; Quaeghebeur, 2020.) The variation in the uncertainties and bias is substantial, so this table of averages does not provide a complete picture, but enough to draw some conclusions.
-
A fixed-point format does not have the flexibility to give the appropriate number of significant digits; usually either too many or too few are given.
-
While the uncertainty is usually rather small (up to a few percent), in some cases it is substantial (around 10 % or more).
-
The bias in the sample standard deviation can in general not be ignored. (For example, for ambient temperature, we see that the bias-corrected value is smaller than the uncertainty.)
What the impact of uncertainty and bias is depends on the application. (For example, turbulence intensity estimation is clearly affected by the bias in the wind speed sample standard deviation. Concretely for horizontal wind speed, e.g., an average reduction of turbulence intensity up to about 20 %.) But to be able to assess this impact, uncertainty and bias values must be available, making expressions such as the above essential.
Table 3Average relative uncertainties and bias in percent for quantities from the MMIJ dataset for which some (likely incomplete) uncertainty information is available. (See Table A1 for more information about the quantities. The values are given with two digits, but it is not implied that both are significant.)

s Correction for tower shadow by selective averaging of values at the same height.
v Virtual measurement, namely, derived from signals obtained with one or more actual instruments.
Before closing this section, it is important to stress that the expressions for propagated uncertainties and biases above are generic. Namely, their derivation does not depend on the specific quantity considered or instrument used. Detailed knowledge of the measuring instrument's properties may allow for better uncertainty estimates or additional uncertainty and bias terms. For example, for cup anemometers, it is known that there is a positive bias of 0.5 %–8 % in the mean wind speed but that this bias can be greatly reduced using wind direction variance estimates (Kristensen, 1999). Also, the IEC 61400-12-1 standard prescribes how the wind speed uncertainty should be calculated for calibrated cup anemometers (IEC, 2017, Appendix F), which may lead to high-quality estimates for εa and εr.
We split our discussion of dataset file formats into two parts. First, in Sect. 3.1, we give an overview of the formats that are currently used for the dissemination of the datasets studied and existing alternatives that we argue to be superior. Then, in Sect. 3.2, we take a closer look at the potential of these alternatives based on our practical experience with them.
3.1 A comparison of dataset file formats
We saw in Sect. 2.1, during our first look at the datasets we studied, that these were disseminated as a compressed set of Excel files for OWEZ, a compressed semicolon-separated-value file for MMIJ, and a compressed set of tab-separated-value files for FINO1. In the Excel files, the values are stored as 8 B binary floating point numbers. In the delimiter-separated-value files the values are specified in a fixed-point decimal text format, with five (MMIJ) and two (FINO1) fractional digits. All of these are essentially table-based formats, where columns correspond to series and rows correspond to values for a specific time instance. (This structure satisfies the requirements of “tidy data” according to Wickham (2014), apart from being split over multiple files.) Some metadata are included in two or more header lines, such as series identifiers and the unit.
We created binary file format versions of the datasets; in HDF5 format (The HDF Group, 2019a) for OWEZ and in netCDF4 format (Unidata, 2018) for MMIJ and FINO1. Both formats are platform-independent. Files in netCDF4 format are actually HDF5 files, but adhering to the netCDF data model (Rew et al., 2006). The use of a different data model is reflected in the application programming interfaces (APIs) available for HDF5 and netCDF4. A number of HDF5's technical features are not supported by the netCDF data model, which on the other hand provides additional semantic features, most notably, shared dimensions and coordinate variables. The netCDF4 format and its predecessors are popular for the storage of Earth science datasets, including metocean ones. These formats allow the data to be placed into multidimensional arrays, called “variables”, in a hierarchical file system-like group structure. Arbitrary key-value metadata attributes can be attached to both groups and variables. The variables support various common data types, such as 1, 2, 4, and 8 B integers; 2, 4, and 8 B binary IEEE floating point numbers (Cowlishaw, 2008); and character strings. Also, custom enumerations, variable-length arrays, and compound types can be defined, e.g., a combination of four floats and an integer. Furthermore, variables can be compressed transparently, i.e., without the user having to manually perform decompression before use.
Let us give a brief evaluation of support in software tools for the different file formats. Even if the delimiter-separated-value files are not really standardized (however, see Lindner, 1993; Shafranovich, 2005), support for them is near universal. Software tools usually include options to deal with the particulars of the actual encoding (delimiter, quoting, headers, etc.), but this does require manual discovery of these specifics. These text-based formats can in principle be read and modified in a text editor, but these are usually not designed to deal with large files, so this is actually impractical for all but the smallest datasets. The Excel “xls” format, even though proprietary, has broad reading support. Support for HDF5 and netCDF4 formats in software tools is very extensive (The HDF Group, 2019b; Unidata, 2019b). This, in addition to their feature set, is also a reason for us choosing to use them; they appear to be the most future-proof of the many binary formats in existence. We used Python modules to work with all these formats (McKinney et al., 2019; Colette, 2018; Unidata, 2019a).
Next let us consider the impact of a format being text-based or binary-based. Text-based formats in principle give a lot of freedom in choosing the format in which values are represented, but usually this is done in a single fixed-point format. To use the data, the values' representations need to be parsed into the standard binary number formats used by computers, namely floats and integers of various kinds. Binary file formats use binary number formats directly, which are faster to load into memory and more space-efficient.3 Because of their standardized nature, they can include other binary-specific features, such as transparent compression and checksums (data integrity codes).
Now let us look at the metadata. HDF5 and netCDF4 are considered self-describing formats, as they allow arbitrary metadata to be included next to the data. These data are easy to access, also programmatically. Table-based data files typically include one or two header lines of metadata (sometimes more), but there is no universal convention about what can be found there. So making use of information included in this way always requires user intervention. There are initiatives to create metadata inclusion standards for delimiter-separated-value formats, but these have not gained significant adoption and are aimed at either web-based material (Tennison et al., 2015) or small datasets (Riede et al., 2010), or they are very recent proposals (Walsh and Pollock, 2019).
Section 2.2.2 mentioned that the documentation available for the datasets we investigated is not machine-readable. It can be made so by providing it as metadata. Such metadata can be used to facilitate analyses and uses of the data. For example, if a tool has access to the range and units associated with series of values, air pressure, and temperature, say, then it can automatically determine those for derived series, such as air density. Examples of metadata standards for datasets are the “CF Conventions” (Eaton et al., 2017), ISO 19115-1 (ISO/TC 211, 2014), and the recently developed “Metadata for wind energy Research and Development” (Sempreviva et al., 2017; Vasiljevic and Gancarski, 2019). It is encouraged in the Earth science community to not just add arbitrary metadata, but also include at least standard attributes from the “CF Conventions” (Eaton et al., 2017) and follow the “Attribute Convention for Data Discovery” (Earth Science Information Partners, 2015). These facilitate reuse and discovery and also make it possible, for example, for software to enhance the presentation of the dataset elements (see, e.g., Hoyer et al., 2018). They also allow for adding further useful metadata, such as provenance information, e.g., in the form of an ISO Lineage (ISO/TC 211, 2019). These conventions are aimed at netCDF files, but can to a large degree be applied to HDF5 files as well. Of course the metadata to be included as recommended by these conventions can also be specified for table-based formats, but not in the same self-describing way.
3.2 Practical experiences with binary formats
We already mentioned in Sect. 2.2.1 that we created binary HDF5 and netCDF4 file versions of the datasets we studied. In this section, we first, in Sect. 3.2.1, report on the process and its results. Then, in Sect. 3.2.2, we discuss the limitations of these formats, including limitations of software support.
3.2.1 The transformation process
Transforming the supplied data files was done by writing a specific script for each case. The general setup is similar for each script.
-
One needs to import the supplied datasets into in-memory data structures that can be manipulated by the scripting language. An important part of this step is the identification of missing data or data marked as faulty and encoding them appropriately. Storing them as the “not a number” binary floating point value is the common approach we followed. Using a Boolean mask separate from the dataset itself is an alternative that can also be used in case the data stored do not consist of floating point values.
-
One must decide on and create a structure for the file, to organize the data and make them conveniently accessible. We used a hierarchical structure for this, grouping first by device (class) and then by quantity. For instrument locations, we tried two approaches:
-
adding the locations as groups in the hierarchy, below the “quantity” groups (done for OWEZ);
-
collecting the data for all locations in a multidimensional array with additional axes next to the time axis, e.g., for height and boom direction (done for MMIJ and FINO1).
For the different statistics (minimum, maximum, mean, and standard deviation), we tried three approaches:
-
adding the statistics series as separate variables in the hierarchy (done for all three);
-
keeping the statistics together in a compound data structure, essentially a tuple of values, where each value is accessed by (statistic) name; such compound values then formed the elements of the multidimensional arrays (done for MMIJ and FINO1);
-
adding the statistics as an extra axis to the multidimensional array (done as well for MMIJ).
-
-
One must collect and compose the metadata for the dataset, the devices, and the quantities. Then one must add these as attributes in the file. The latter is almost trivial to do once the former time-consuming task is completed.
-
One must choose an encoding and the storage parameters for the data and write them out to the file. We chose to store the values as 4 B binary floating point numbers, compress them using the standard “Deflate” algorithm, and add error detection using “Fletcher-32” checksums. Furthermore, we used the information available about the accuracy of the values to round to the least significant binary digit. This is a lossy transformation that, however, does not lose significant information, but further improves compression.
Let us finish this section with some remarks.
-
During the transformation process, we could load the datasets studied entirely into memory. This is convenient, but not necessary, as the process of reading the supplied datasets can be done in a piece-wise fashion.
-
The size of the files resulting from the transformation we made was one-eighth of the supplied files' size or smaller and one-half their compressed size or smaller. (More precisely, the sizes of the uncompressed (compressed) supplied files versus the sizes of our HDF5 or netCDF4 versions are as follows: OWEZ: 1 GB (400 MB) vs. 65 MB; MMIJ: 500 MB (120 MB) vs. 55 MB; FINO1: 800 MB (120 MB) vs. 50 MB.)
-
Tools exist to facilitate the transformation process, most notably the online service Rosetta (Unidata, 2013), which generates netCDF files satisfying the CF Conventions.
-
Templates to facilitate the creation of netCDF files satisfying the CF Conventions and the Attribute Conventions for Data Discovery are available (NOAA National Centers for Environmental Information, 2015). These do not make use of hierarchical grouping, but can to a large degree be used within each group.
3.2.2 Limitations of binary formats tested
When creating the transformed dataset files, we tested many of the features available in the HDF5 and netCDF4 formats. Not all of these features turned out to be as useful as initially expected or have sufficient software support. We here discuss features for which we encountered issues, to help others make an informed choice when considering their use.
- Compound data structures
-
Compound data structures are essentially tuples of values, where each component value is accessed by its name. These allow for a tight grouping of related data, for example to group all the statistics for a given signal for a given measuring interval, to attach a quality flag, or to group the components of a vector (e.g., the wind velocity). However, metadata cannot be attached to the structure's components, and to read any one component the whole structure is loaded in memory, multiplying the memory requirements. Furthermore, support for creating these structures for use in netCDF4 files using Python was buggy and support for reading compound value data is currently far from universal; for example, it is not included in MATLAB's netCDF interface. Also, documentation of their use is currently limited.
- 2 B floating point numbers
-
HDF5 allows the storage of 2 B (16-bit) floating point numbers, which is more space-efficient if the precision is sufficient. The support in the core HDF5 library turned out to be buggy and support was non-existent, e.g., in MATLAB.
- Scale-offset filters
-
Another approach for efficiently storing floating point values x is to transform them to integer values k of shorter bit length, namely choosing series-specific scale and offset parameters α and β such that x is equal to αk+β within required precision. HDF5 has a built-in filter to do this, but it does not preserve special floating point values like NaNs used for representing missing values. The CF Conventions (Eaton et al., 2017) often used in netCDF files also describe a metadata-based approach, but not all software automatically applies the inverse transformation, so it is not transparent to the user.
- Dimensions
-
When creating variables, the netCDF4 format requires using defined “dimensions” (e.g., time and height). These can be shared between variables and associated with “coordinate variables” (e.g., arrays with concrete time values and instrument heights). There is also a similar concept of “dimension scale” in HDF5, but it is not as convenient.
- Unicode
-
In principle both HDF5 and netCDF4 support Unicode text for group, variable, and attribute names and for attribute values. Software support for Unicode text in attribute values is not universal, however; notably, MATLAB does not support this yet for netCDF4.
- String values
-
Both HDF5 and netCDF4 support variable-length strings as variable values. This can for example be useful for coordinate variables, such as when instrument position is designated by “left” and “right”. However, again MATLAB does not support this yet for netCDF4.
Based on our analysis of the three datasets and on our work transforming them into binary file formats, we have the following recommendations for the three main stakeholders. (We also briefly indicate their role in the shared responsibility for creating high-quality, well documented, and usable datasets.)
- Project owner
-
(Through the “scope of work” part of the contract with the dataset producer, this party can specify requirements for the dataset format, quality, and documentation, so that it meets the needs of the considered dataset users.)
-
Require the dataset producer to provide the datasets in a standardized binary format.
-
Agree with the dataset producers about a concrete level of quality control.
-
Require the datasets to be accompanied by (explicitly specified) extensive metadata and documentation, including accuracy and quality information.
-
- Dataset producers
-
(Next to being responsible for producing the dataset, this party can inform the project owner about the possibilities for dataset creation and the dataset users about efficient dataset use.)
-
Expand the automated checks performed on the signals the dataset series are based on, to efficiently remove avoidable issues that are currently still present (Sect. 2.2.1).
-
Make the documentation of the dataset and its creation process more comprehensive (see Sect. 2.2.2). This is best done by attaching metadata right next to the data. External documentation such as data manuals and websites, if still needed, can be semiautomatically generated from metadata that are stored in a structured way.
-
Use clear version identification in dataset files, to avoid confusion when updated or extended datasets are released.
-
Provide datasets in a binary format that allows for a structured combination of data and metadata (see Sect. 3.2). Based on our experience, we currently advise, for metocean measurement statistics datasets, using the netCDF4 format, with
-
metadata added according to the Attribute Conventions for Dataset Discovery and CF Conventions (see Sect. 3.1);
-
metadata describing absolute and relative sample uncertainty (see Sect. 2.2.5);
-
coordinate variables for all dimensions of the data variables;
-
each statistic series as a separate variable, so not using compound data structures or expanding the multidimensional array;
-
values binary-rounded according to the available uncertainties (see Sect. 2.2.5), which do not preclude inclusion of “ancillary” variables for the uncertainty values themselves;
-
sample standard deviations corrected for bias (see Sect. 2.2.5) or inclusion of an ancillary variable for the bias (modifying the values themselves may be seen as too invasive);
-
variables compressed transparently, so not using a metadata-based scale-offset filter.
Its better support for dimensions and coordinate variables is what makes the netCDF4 format currently more attractive than the plain HDF5 format.
-
-
Add a quality flag variable for each signal (see Sect. 2.2.4).
-
- Dataset users
-
(This party can communicate its needs and provide feedback to the project owner and dataset producers.)
-
Invest in learning to work with formats like HDF5 or netCDF4, as this will allow them to work more efficiently with datasets (see Sect. 3).
-
Provide feedback to the dataset producers about issues encountered and dataset features that would have added value for research (our experience in this regard is positive).
-
And of course do not trust the data blindly and perform some checks in the vein of those we discussed in Sect. 2.2.1.
-
The questions of our study were as follows. (i) Are these issues commonly shared in metocean measurement datasets? (ii) How can the issues that are present be addressed?
The answer to the first question is “yes, but not uniformly”. The analysis of three datasets with statistics of metocean signals aimed at wind energy applications presented in Sect. 2.2 showed that indeed there are shared issues, such as the presence of unmarked faulty data (outliers, most clearly), incomplete documentation (signal accuracy, most generally), and value encoding (lack of uncertainty information, most importantly). Some issues are not shared, and one dataset can actually be seen as an example of good practice in some aspects (the quality flags included in the FINO1 dataset, most concretely).
An abstract answer to the second question is “by the dataset producers, in a straightforward way, with limited effort”.
-
The techniques we used to bring faulty data to light are straightforward to implement, which supports our claim that they can be detected and fixed with relatively little effort.
-
Concerning documentation, in our quest for creating a good overview of the datasets, we collected information from various sources to supplement the documentation provided; this is a time-consuming task. Much of the information that we had to search for is available to the dataset producers, so the effort for them is smaller. Given that one cannot expect all dataset users to perform data quality analyses and information collection efforts themselves, it would be beneficial if the project owners explicitly make this a duty of the dataset producers. This will make their datasets more useful and therefore more valuable.
-
As noted above, a specific issue with the datasets was the limited information about and quantification of the uncertainty of the dataset values. The expressions for uncertainties and bias we derived provide a straightforward quantification of the statistics' uncertainties and bias based on the information that is typically available, absolute and relative uncertainties for the sample values. These expressions can be used by users if needed by their application. The dataset producers can also apply them and use the uncertainty values found to improve their dataset, e.g., by rounding the dataset values (reducing the size requirements) or by including the uncertainty values as ancillary variables.
-
In support of our analysis of the datasets, we created versions in a binary format. In comparison to the tabular formats in which the datasets are made available, such binary formats are more convenient for users, as they make the data available in a much more structured format and as they are self-describing when documentation is added as metadata. The description of our effort, experiences, and feature evaluation provides a high-level guide and suggested best practices to dataset producers who wish to also improve their datasets in this way.
In summary, this paper shows why and how metocean measurement datasets for wind energy applications can be improved in various, useful ways, with relatively little effort. This effort can be seen by the project owner as necessary for getting the most value out of the raw data collected. Such a well-documented dataset with uncertainty and quality information included creates the possibility for consciously making possibly different choices (trade-offs) when setting up future measurement campaigns.
A1 A first look at the datasets
A1.1 MMIJ – measuring mast IJmuiden
In the context of a Dutch governmental research program, a met mast was built in the Dutch part of the North Sea with the aim to gather metocean data with a frequency and quality needed for the planning and development of offshore wind farms in the Dutch North Sea. Its location is 52∘50′53.4′′ N, 3∘26′8.4′′ E (WGS 84), which is 82 km off the Dutch coast near the province North Holland. The location is indicated in Fig. 1. The mast was ready for operation in 2011 and was decommissioned by 2017. Data are available for the period November 2011–March 2016. Multiple datasets can be obtained; we restricted attention to the one for meteorological signals. The instruments used and quantities measured and some of their characteristics are listed in Table A1.
Table A1An overview of the instruments and their locations on the MMIJ met mast (height in meters above the Lowest Astronomical Tide), the quantity measured, the measurement uncertainty, the measurement ranges, and the sampling frequencies.
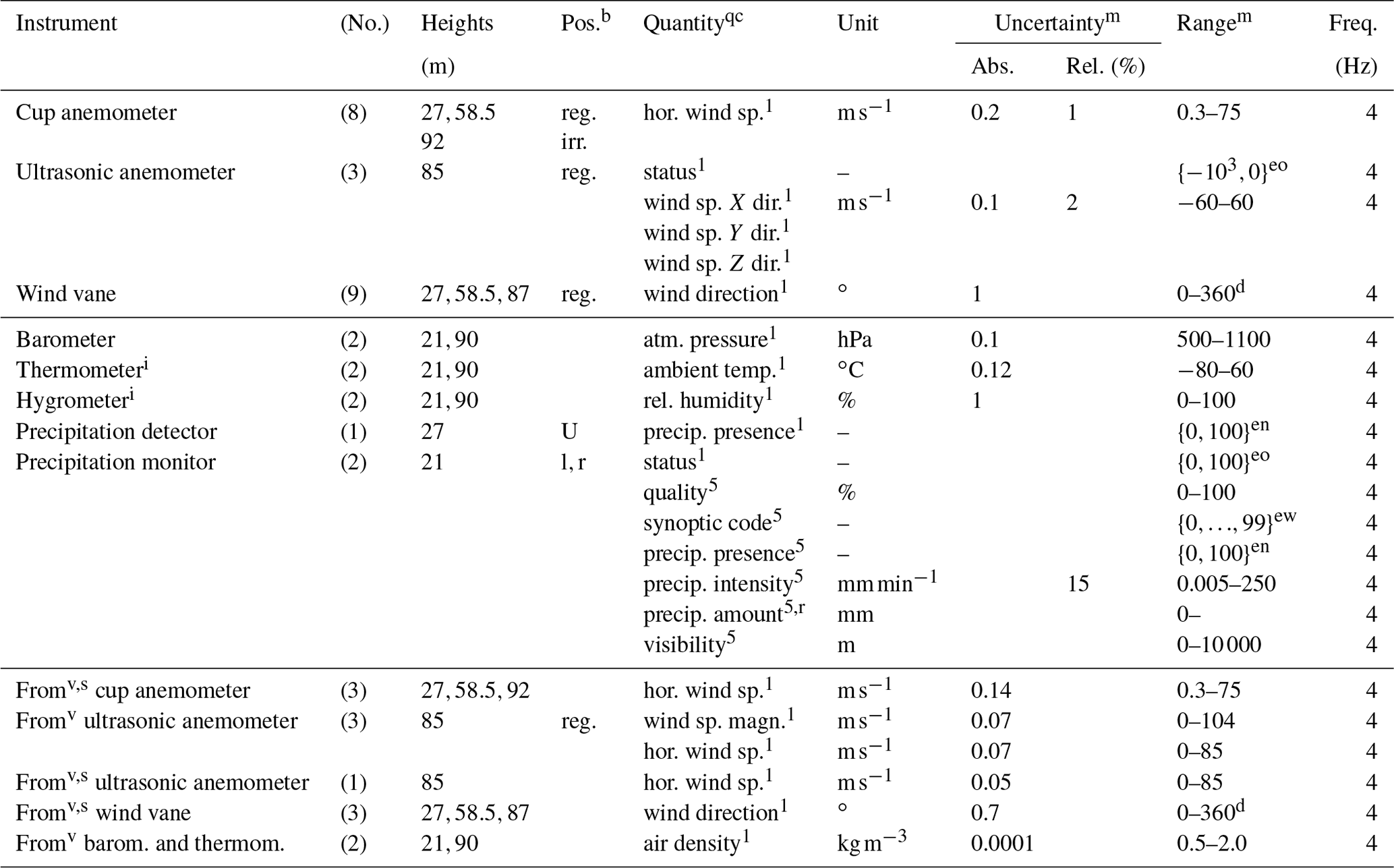
b For instruments on booms, positions are boom orientations (∘), with (geographic) north at 46.5∘; “reg.” corresponds to and “irr.” to {180,300}. For those not on booms other identifiers are used, if known.
d Means lie between 0∘ and 360∘; minima and maxima can be outside of that interval so that .
en No, yes.
eo “0” is OK; non-zero is not OK.
ew Using synoptic “present weather” codes defined by the World Meteorological Organization (2016, p. 356–358).
i Thermometer and hygrometer are contained in a single package.
m Missing values are unknown.
qc Quality code: “1” is “ISO 17025 approved, in accordance with IEC61400-12”; “5” is “no or unknown calibration”.
r Between sensor resets.
s Correction for tower shadow by selective averaging of values at the same height.
v Virtual measurement; namely, derived from signals obtained with one or more actual instruments.
The MMIJ datasets can be obtained by registering, which is free, and filling in a request form on the website of the Energy research Centre of the Netherlands (ECN, 2019).4 The meteorological statistics dataset can be downloaded via an e-mailed link as a single compressed semicolon-separated-value (csv) file. The total size is a good 500 MB, or about 120 MB compressed. This represents data points for 229 248 10 min intervals. The data in the csv file are structured as follows:
-
one date–time column (
YYYY-MM-DD hh:mm); -
65 sets of four columns each: one for each of the four real-valued statistics, “min”, “max”, “avg”, and “std”, with each set corresponding to a specific measured quantity and location on the mast.
The statistics' values are encoded in a decimal fixed-point format with five fractional digits (x...x.xxxxx).
Information about the dataset, the met mast, and its context is available through the same website. In particular, there is an instrumentation report (Werkhoven and Verhoef, 2012). Some information about the instruments used and in particular the measurement uncertainty had to be looked up in specification sheets. Further clarifications were obtained through personal communication with people involved in the project (see Acknowledgements).
A1.2 FINO1 – research platform in the North Sea and the Baltic Sea Nr. 1
In the context of the German governmental research program FINO (“Forschungsplattformen in Nord- und Ostsee”) started in 2002, three measuring stations with met masts were built: two in the German part of the North Sea and one in the Baltic Sea. The aim is to support technological developments for and study the effect of offshore wind farms. We have looked at data from the first mast erected, FINO1, which became operational in 2003. Its location is 54∘0′53.5′′ N, 6∘35′15.5′′ E (WGS 84), 45 km north of the island of Borkum, near the site where the offshore wind farm “Alpha Ventus” was built in 2009–2010. The location is indicated in Fig. 1. Data from 2004 onward are available; measurements are still ongoing. Multiple datasets can be obtained; again we restricted attention to the one for meteorological signals. The instruments used and quantities measured and some of their characteristics are listed in Table A2.
Table A2An overview of the instruments and their locations on the FINO1 met mast (height in meters above the Lowest Astronomical Tide), the quantity measured, the measurement uncertainty, the measurement ranges, and the sampling frequencies.
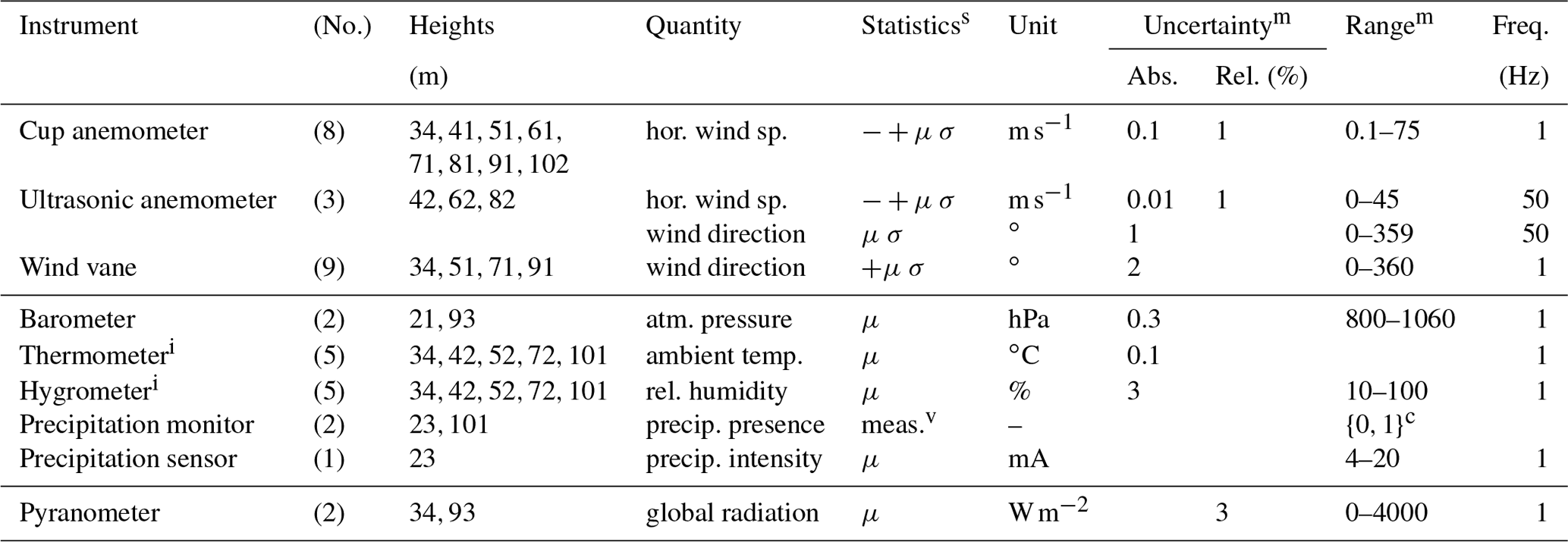
c No, yes.
m Missing values are unknown.
i Thermometer and hygrometer are contained in a single package.
s Statistics included (with column name): “−” is minimum (“Minimum”), “+” is maximum (“Maximum”), “μ” is mean (“Value”), “σ” is standard deviation (“Deviation”).
v The measurement is given (in the “Value” column in the dataset file), as there is essentially one measurement per 10 min.
The FINO1 datasets can be obtained after requesting access (BSH, 2019a), which is free for academic research, but not so for commercial purposes; re-dissemination is not allowed. Credentials are then provided to login to the download website (BSH, 2019a), where one can select the desired signals and time period. The resulting dataset is delivered as a compressed set of tab-separated-value (dat) files, one for each selected quantity–height combination. We selected the meteorological statistics data for the years 2004–2016. The total size is a good 800 MB, or about 120 MB compressed. This represents data points for 683 856 10 min intervals. The data in each dat file are structured as follows:
-
one date–time column (
YYYY-MM-DD hh:mm:ss); -
four statistics columns, “Value”, “Minimum”, “Maximum”, and “Deviation”;
-
one quality column (“0” is raw, “1” is doubtful quality, “2” is quality controlled).
The statistics' values are encoded in a decimal fixed-point format with up to two fractional digits (x...x.xx).
Information about the dataset, the met mast, and its context are available through the platform's websites (FINO 1, 2019; BSH, 2019b). A detailed overview table regarding the mast's instrumentation (DEWI, 2015) is available upon request by e-mail. Some information about the instruments used and in particular the measurement ranges had to be looked up in specification sheets. Further clarifications were obtained through personal communication with people involved in the project (see Acknowledgements).
Others have looked at the FINO1 data before. For example, an initial data analysis was presented after 5 years of operation (Beeken et al., 2009) and detailed studies have been performed on the wind speed data gathered (Westerhellweg et al., 2012; Stepek et al., 2015).
A1.3 FAIRness analysis
There is currently a movement in the academic community to try and make datasets FAIR: findable, accessible, interoperable, and reusable (Wilkinson et al., 2016). This appendix provides a brief analysis of the FAIRness of the three datasets that were investigated. It first looks at the current status, then moves to what role the recommendations of this paper play in changing that status, and finally evaluates the role of the non-user stakeholders. Our analysis is based on the checklist “How FAIR is your data?” of Jones and Grootveld (2017).
We look at each of the FAIRness principles.
- Findable
-
None of the datasets has a persistent identifier assigned to them. While metadata for each dataset are available online, they are not present in a searchable resource for any of the datasets, but are less conveniently in manuals or on a custom website. So none of the datasets are really findable (according to the FAIRness criteria).
- Accessible
-
For all of the datasets, the protocol by which the data can be retrieved follows a recognized standard; namely, it can be downloaded from a website. Furthermore, even if obtaining the data requires authorization as for MMIJ and FINO1, the available metadata are accessible without it. So, setting aside the lack of a persistent identifier, all the datasets are quite accessible (according to the FAIRness criteria).
- Interoperable
-
All of the datasets are provided in a commonly understood format, although the format for OWEZ (old, proprietary Excel format) is not open. The metadata provided do not follow any standard, and neither are controlled vocabularies used. Also, no qualified references or links to other (meta)data are provided. Given the above, all the datasets are only interoperable in a very basic way (according to the FAIRness criteria).
- Reusable
-
The (meta)data are fairly accurate and reasonably well described for all three datasets. Only FINO1 has a fairly clear (but restrictive) license. For all datasets, the provenance is clear. While collected for wind energy applications, the datasets contain Earth science data; the metadata standards relevant in that domain are not met. Based on the above, the datasets are somewhat reusable (according to the FAIRness criteria).
This paper's recommendations argue for the data to be made available in a standardized binary format with metadata included. It also promotes more extensive quality checks. Such transformed datasets would raise the level of interoperability and reusability, mostly because of the improved handling of metadata.
The dataset producers can furthermore make sure the datasets are assigned a persistent identifier pointing to a location in a data repository, where they are stored under a clear license. They could also make the metadata collected for inclusion in the binary dataset file available there. These efforts would raise the level of findability, accessibility, and reusability. In line with what was mentioned in our recommendations (Sect. 4), the project owner can specify the FAIRness criteria as requirements, to ensure that this is actually done.
A2 Dataset issues
A2.1 Maximum and minimum for directional data
We here give a proposal for definitions of maximum and minimum for directional data. We assume the sampling frequency is high enough to make direction changes larger than 180∘ for successive samples practically impossible.
Transform the direction sequence from 0 to 360∘ to the real line so that “360∘ jumps” are removed; e.g., the sequence 356, 358, 1, and 4∘ would become 356, 358, 361, and 364∘. Call the minimum and maximum of this transformed sequence χ and ξ; so and in our example. If the direction has changed at least one full rotation for the given sequence. Let μ be the (vector) mean, expressed within 0–360∘; so in our example. Now choose k such that with minimal; k=0 in our example. Then and are the sought for minimum and maximum.
A2.2 Statistic value uncertainty
The statistics present in the dataset are derived from n measurements xk uniformly sampled over a length-T interval, where T=600 s for the datasets we consider. To get a view on the uncertainty of the statistics, we model the process generating the measurements as follows: There is an underlying signal y with samples yk=y(tk). On measurement, noise is added, so that for all . The noise is assumed to consist of independent absolute and relative zero-mean Gaussian components (Cramér, 1946, chap. 17), i.e., with zr,k and za,k samples from independent standard normal distributions, so that the component's standard deviations are εa and εryk.
We first consider the contribution of sampling and then the contribution of the noise to the uncertainty of the statistics.
Uncertainty due to sampling
The “ideal” statistic values are defined in terms of the continuous-time signal:
The “noiseless” sample statistics values are
where for the sample variance , we did not apply the usual bias correction because n is assumed sufficiently large.
As we assume is done in the datasets, we take . So we are applying the “left-hand rule” numerical integration method (see, e.g., Tucker, 1997) to get estimates for and for . A corresponding error estimate is where f is equal to and , respectively. An estimate for the sum of derivatives is obtained by assuming y is linear, i.e., and . Similarly, for uncertainty estimates of the maximum and minimum statistics, we assume that the signal continues to linearly increase (decrease) for half a sample step beyond the maximum (minimum) sample.
To get concrete values, we replace the noiseless statistics with the actual noisy ones. This results in the following expressions:
where the uncertainty for the standard deviation sy was derived from the one for the variance by applying a first-order Taylor approximation of the square root. In case the minimum and maximum statistics are not available, but the sample standard deviation is, one could use the crude estimates and , where is the standard normal quantile for exceedance probability 1∕n.
A2.3 Uncertainty due to measurement noise
We use the following random variables to model the process that adds noise to the measurements: Xk for the measurements and Ek for the noise, with auxiliary standard normal variables Za,k and Zr,k, so that with . Here, the basic random variables Za,k and Zr,k are assumed to be independent from each other and all other random variables Za,ℓ, Zr,ℓ, ℓ≠k.
Some further notation: 𝔼 is the expectation operator. Var and Cov are the variance and covariance operators, respectively, defined for any random variables V and W by and . Furthermore, we let , , , with , and .
Recall that standard normal variables Z are completely determined by their expectation 𝔼(Z)=0 and variance . Also, the expectation of any odd power is zero: (Cramér, 1946, Eq. 17.2.3).
For the sample minimum and maximum we assume that the measurement noise does not substantially influence the order statistics, so and . (Otherwise this noise introduces bias in the estimate and an extra term in the variance (see Cramér, 1946, Eq. 28.6.16).) This implies
because
where for the variance the first equality follows from independence of the variables Za,k and Zr,k.
For the sample mean we can deduce that
because
because it holds that (Cramér, 1946, Eq. 15.4.4).
For the sample standard deviation sX, we use the first-order Taylor expansion of the square root with varying around :
So first-order approximations of the expectation and variance are
So we see that we actually need to calculate and , the expectation and variance of the sample variance.
Let us first write this sample variance in terms of our model variables:
Then
because
Furthermore
The last term of this expression is zero because all terms of its expansion contain odd powers of independent standard normal random variables. We do not perform the tedious calculation of the first term, as it essentially expresses the uncertainty of the measurement noise, which has been left unmodeled. Therefore we ignore this term, which means we consider a lower bound:
where in the last step the first and last terms' calculation is analogous to the one of above. It holds that and because we have no estimate for and , we use the Gaussian case, i.e., we assume and (Johnson et al., 1994, chap. 13). This gives
Going back to the sample standard deviation in Eq. (A7), using Eq. (A8), and assuming n≫1 and , we get
where for the last approximation we assumed that the measurement noise's contribution to the sample standard deviation is negligible ().5 In any case, in general the bias in sx as an estimator of sy dwarfs the estimate of the uncertainty due to the measurement noise. Even the uncertainty in the bias (the unmodeled uncertainty of the measurement noise) may overwhelm . These considerations lead us to conclude that the lower bound we give is conservative in general and that the real uncertainty can be substantially larger.
To get concrete values, we replace , , , and appearing in the expressions for the uncertainties by their estimates. We also deal with the corner case . This results in the following estimates for the expectations and uncertainty, again assuming :
A2.4 Combined uncertainty
To arrive at a total uncertainty, we combine them using the combination rule for independent uncertainties from classical error propagation (Taylor, 1997):
Here we use x instead of y in the left-hand side subscripts because outside of this appendix there is no need to refer to the underlying model we use.
Code used during the research is publicly available via GitHub and Zenodo (https://doi.org/10.5281/zenodo.3611120, Quaeghebeur, 2020). This bundle also includes the metadata included in the transformed datasets as human-readable and machine-readable YAML files.
We are not allowed to make the transformed FINO1 dataset available. It is not yet clear whether we will obtain permission to make the transformed OWEZ and MMIJ datasets available. If we do, these will be put on a publicly available data repository, referenced in an updated version of the bundle (Quaeghebeur, 2020).
The supplement related to this article is available online at: https://doi.org/10.5194/wes-5-285-2020-supplement.
EQ performed the brunt of the work and wrote the paper. MBZ provided essential feedback on almost all aspects of the work in regular discussions and so made sure errors were weeded out or avoided from the start. He also did revision work on the paper.
The authors declare that they have no conflict of interest.
We thank Marc de Hoop (Mierij Meteo Systems) and Sicco Kamminga (Nortek) for providing useful information about various OWEZ instruments and Peter Eecen (ECN) for providing additional information about the measurement setup. In the context of our investigation of the MMIJ dataset, extensive communication with people of ECN took place; we thank Hans Verhoef, Arno van der Werff, and Ingmar Alting for their time and effort and Johan Peeringa and Clym Stock-Williams for facilitating this communication.
Regarding FINO1, we thank Olaf Outzen (BSH: Bundesamt für Seeschifffahrt und Hydrographie), Markus Kreklau (BSH), and Richard Fruehmann (UL International GmbH – DEWI) for providing instrumentation information and for their replies to inquiries.
We thank two reviewers of an earlier version of this paper for their useful feedback, suggestions, and pointers. These have improved its focus and coverage. We also thank the Wind Energy Science reviewers Rémi Gandoin, Nikola Vasiljevic, and Hans Verhoef for their many valuable comments that have led to clear improvements, such as making available separate metadata files, introducing the project owner as a stakeholder, and considering the FAIR data principles.
This research is part of the Dutch EUROS program, which is supported by NWO domain Applied and Engineering Sciences and partly funded by the Dutch Ministry of Economic Affairs.
This paper was edited by Andrea Hahmann and reviewed by Hans Verhoef, Rémi Gandoin, and Nikola Vasiljevic.
Aggarwal, C. C.: Outlier analysis, 2 edn., Springer, Cham, Switzerland, https://doi.org/10.1007/978-3-319-47578-3, 2017. a
Beeken, A., Neumann, T., and Westerhellweg, A.: Five years of operation of the first offshore wind research platform in the German Bight – FINO1, Tech. rep., DEWI GmbH, available at: https://www.dewi.de/dewi/fileadmin/pdf/publications/Publikations/5_Beeken.pdf, last access: 25 November 2009. a
Brower, M. C., ed.: Data validation, chap. 9, pp. 117–129, John Wiley & Sons, Inc., Hoboken, New Jersey, https://doi.org/10.1002/9781118249864.ch9, 2012. a
BSH: FINO – Plot und Download, available at: http://fino.bsh.de/ (last access: 15 October 2019), 2019a. a, b
BSH: FINO, available at: https://www.bsh.de/DE/THEMEN/Beobachtungssysteme/Messnetz-MARNET/FINO/fino_node.html (last access: 15 October 2019), 2019b. a
Colette, A.: HDF5 for Python (version 2.9.0), available at: http://www.h5py.org/ (last access: 15 October 2019), 2018. a
Cowlishaw, M., ed.: Standard for Floating-Point Arithmetic, IEEE Std 754-2008, IEEE, Piscataway, NJ, USA, https://doi.org/10.1109/IEEESTD.2008.4610935, 2008. a
Cramér, H.: Mathematical Methods of Statistics, Princeton University Press, Princeton, New Jersey, USA, 1946. a, b, c, d
Curvers, A.: Surrounding obstacles influencing the OWEZ meteo mast measurements (version 2), Tech. Rep. ECN-WindMemo-07-041, ECN, available at: https://www.noordzeewind.nl/nl_nl/kennis/meteogegevens/_jcr_content/par/iconlist/iconlistsection_1245724476/link.stream/1554383869782/bca17955510aad4a2be63909cf037499351150de/owez-r-181-t0-undisturbed-wind.pdf (last access: 15 October 2019), 2007. a
DEWI: FINO1 – Meta Data, Tech. rep., UL International GmbH – DEWI, Wilhelmshaven, Germany, 2015. a
Earth Science Information Partners: Attribute convention for data discovery (version 1.3), available at: http://wiki.esipfed.org/index.php/Attribute_Convention_for_Data_Discovery_1-3 (last access: 20 May 2019), 2015. a
Eaton, B., Gregory, J., Drach, B., Taylor, K., Hankin, S., Blower, J., Caron, J., Signell, R., Bentley, P., Rappa, G., Höck, H., Pamment, A., Juckes, M., and Raspaud, M.: CF Conventions (version 1.7), available at: http://cfconventions.org/ (last access: 15 October 2019), 2017. a, b, c
ECN: Wind op Zee: Meteomast IJmuiden, available at: https://www.windopzee.net/meteomast-ijmuiden-mmij/ (last access: 15 October 2019), 2019. a
Eecen, P. J. and Branlard, E.: The OWEZ Meteorological Mast: Analysis of mast-top displacements, Tech. Rep. ECN-E–08-067, ECN, available at: https://www.ecn.nl/publicaties/ECN-E--08-067 (last access: 15 October 2019), 2008. a
FINO 1: Forschungsplattformen in Nord- und Ostsee Nr.1, available at: http://www.fino1.de/en/ (last access: 15 October 2019), 2019. a
Fisher, N. I.: Statistical analysis of circular data, Cambridge University Press, Cambridge (UK), https://doi.org/10.1017/CBO9780511564345, 1995. a
Folk, M., Heber, G., Koziol, Q., Pourmal, E., and Robinson, D.: An overview of the HDF5 technology suite and its applications, in: Proceedings of the EDBT/ICDT 2011 Workshop on Array Databases, pp. 36–47, ACM, Association for Computing Machinery New York, NY, United States, https://doi.org/10.1145/1966895.1966900, 2011.
Hoyer, S. and Hamman, J.: xarray: N-D labeled arrays and datasets in Python, J. Open Res. Softw., 5, 10, https://doi.org/10.5334/jors.148, 2017.
Hoyer, S., Hamman, J., Fitzgerald, C., Maussion, F., Kleeman, A., Kluyver, T., Roos, M., Fujii, K., Munroe, J., Hatfield-Dodds, Z., Cherian, D., crusaderky, Wolfram, P. J., Bell, R., Abernathey, R., Markel, Bovy, B., Clark, S., Helmus, J. J., Cable, P., Noel, V., Kanmae, T., Rocklin, M., Miles, A., Sinclair, S., and May, R.: pydata/xarray (version 0.10.8), https://doi.org/10.5281/zenodo.1314707, Hoyer and Hamman (2017) give an overview of this software library, 2018. a
IEC: IEC 61400-12-1:2017 – Wind energy generation systems – Part 12-1: Power performance measurements of electricity producing wind turbines, International Electrotechnical Commission, Geneva, Switzerland, 2.0 edn., 2017. a
ISO/TC 211: ISO 19115-1:2014: Geographic information – Metadata – Part 1: Fundamentals, ISO, available at: https://www.iso.org/standard/53798.html (last access: 15 October 2019), 2014. a
ISO/TC 211: ISO 19115-2:2019, ISO, 2 edn., available at: https://www.iso.org/standard/67039.html (last access: 15 October 2019), 2019. a
Johnson, N. L., Kotz, S., and Balakrishnan, N.: Continuous Univariate Distributions, vol. 1, 2nd edn., Wiley and Sons, New York, 1994. a
Joint Committee for Guides in Metrology: International vocabulary of metrology – Basic and general concepts and associated terms (VIM), 200, 3 edn., 2008 version with minor corrections, BIPM in Sèvres, France, 2012. a
Jones, S. and Grootveld, M.: How FAIR are your data?, https://doi.org/10.5281/zenodo.3405141, 2017. a
Kouwenhoven, H. J.: User manual data files meteorological mast NoordzeeWind (version 2.0), NZW-16-S-4-R03, available at: https://www.noordzeewind.nl/nl_nl/kennis/meteogegevens/_jcr_content/par/iconlist/iconlistsection/link.stream/1554383874387/2f65120cc6dbeb967cfa34e08f95a95304e22e39/r03-manual-data-files-meteo-mast-noordzeewind.pdf (last access: 15 October 2019), 2007. a
Kristensen, L.: The perennial cup anemometer, Wind Energy, 2, 59–75, https://doi.org/10.1002/(SICI)1099-1824(199901/03)2:1<59::AID-WE18>3.0.CO;2-R, 1999. a
Lindner, P.: Definition of tab-separated-values (tsv), available at: https://www.iana.org/assignments/media-types/text/tab-separated-values (last access: 15 October 2019), 1993. a
Matula, D. W.: In-and-out conversions, Commun. ACM, 11, 47–50, https://doi.org/10.1145/362851.362887, 1968. a
McKinney, W.: Data structures for statistical computing in Python, in: Proceedings of the 9th Python in Science Conference, edited by: van der Walt, S., Millman, J., available at: http://conference.scipy.org/proceedings/scipy2010/ (last access: February 2020), pp. 51–56, 2010.
McKinney, W. et al.: pandas (version 0.24.2), available at: http://pandas.pydata.org/ (last access: 15 October 2019), McKinney (2010) gives an overview of this software library, 2019. a
Meek, D. W. and Hatfield, J. L.: Data quality checking for single station meteorological databases, Agr. Forest Meteorol., 69, 85–109, https://doi.org/10.1016/0168-1923(94)90083-3, 1994. a
NOAA National Centers for Environmental Information: NCEI NetCDF Templates (version 2.0), available at: https://www.nodc.noaa.gov/data/formats/netcdf/v2.0/ (last access: 15 October 2019), 2015. a
NoordzeeWind: NoordzeeWind: Reports and data, available at: https://www.noordzeewind.nl/nl_nl/kennis/meteogegevens.html (last access: 15 October 2019), 2019. a
Quaeghebeur, E.: equaeghe/met-data-scripts: Version 0.4.0, https://doi.org/10.5281/zenodo.3611120, 2020. a, b, c, d, e, f, g
Rew, R. K., Hartnett, E. J., and Caron, J.: NetCDF-4: software implementing an enhanced data model for the geosciences, in: Proceedings of the 22nd International Conference on Interactive Information Processing Systems for Meteorology, Oceanography, and Hydrology, available at: https://ams.confex.com/ams/Annual2006/techprogram/paper_104931.htm (last access: 15 October 2019), 2006. a
Riede, M., Schueppel, R., Sylvester-Hvid, K. O., Kühne, M., Röttger, M. C., Zimmermann, K., and Liehr, A. W.: On the communication of scientific data: The Full-Metadata Format, Comput. Phys. Commun., 181, 651–662, https://doi.org/10.1016/j.cpc.2009.11.014, 2010. a
Sempreviva, A. M., Vesth, A., Bak, C., Verelst, D. R., Giebel, G., Kjartansson Danielsen, H., Pilgaard Mikkelsen, L., Andersson, M., Vasiljevic, N., Barth, S., Sanz, R. J., Gancarski, P., Reigstad, T. I., Bolstad, H. C., Wagenaar, J. W., and Hermans, K. W.: Taxonomy and metadata for wind energy, Res. Dev., https://doi.org/10.5281/zenodo.1199488, 2017. a
Shafranovich, Y.: Common format and MIME type for comma-separated values (CSV) files (RFC 4180), available at: https://tools.ietf.org/html/rfc4180 (last access: 15 October 2019), 2005. a
Shiffler, R. E. and Harsha, P. D.: Upper and lower bounds for the sample standard deviation, Teach. Stat., 2, 84–86, https://doi.org/10.1111/j.1467-9639.1980.tb00398.x, 1980. a
Stepek, A., Savenije, M., van den Brink, H. W., and Wijnant, I. L.: Validation of KNW atlas with publicly available mast observations, Tech. Rep. 352, KNMI, available at: http://bibliotheek.knmi.nl/knmipubTR/TR352.pdf (last access: 15 October 2019), 2015. a
Taylor, J. R.: An introduction to error analysis, 2nd edn., University Science Books, Sausalito, California, 1997. a
Tennison, J., Kellogg, G., and Herman, I.: Model for tabular data and metadata on the web, available at: https://www.w3.org/TR/2015/REC-tabular-data-model-20151217/ (last access: 15 October 2019), 2015. a
The HDF Group: Hierarchical Data Format, version 5 (version 1.10.5), available at: http://www.hdfgroup.org/HDF5/ (last access: 15 October 2019), Folk et al. (2011) gives an overview of this file format, 2019a. a
The HDF Group: Software ecosystem, available at: https://www.hdfgroup.org/software-ecosystem/ (last access: 15 October 2019), 2019b. a
Tucker, T. W.: Rethinking rigor in calculus: The role of the mean value theorem, Am. Math. Mon., 104, 231–240, https://doi.org/10.2307/2974788, 1997. a
Unidata: Rosetta (version 0.1), https://doi.org/10.5065/D6N878N2, 2013. a
Unidata: Network Common Data Form (netCDF, version 4.6.1), https://doi.org/10.5065/D6H70CW6, 2018. a
Unidata: NetCDF4-Python (version 1.5.1.2), http://unidata.github.io/netcdf4-python/, last access: 15 October 2019a. a
Unidata: Software for manipulating or displaying NetCDF data, https://www.unidata.ucar.edu/software/netcdf/software.html, last access: 15 October 2019, 2019b. a
Vasiljevic, N. and Gancarski, P.: Variables dictionary for wind energy, https://github.com/wind-energy/variables-dictionary, last access: 26 November 2019. a
Wagenaar, J. W. and Eecen, P. J.: 3D Turbulence at the Offshore Wind Farm Egmond aan Zee, Tech. Rep. ECN-E–10-075, ECN, https://www.ecn.nl/publicaties/ECN-E--10-075, last access: 15 October 2019, 2010a. a
Wagenaar, J. W. and Eecen, P. J.: Current Profiles at the Offshore Wind Farm Egmond aan Zee, Tech. Rep. ECN-E–10-076, ECN, https://www.ecn.nl/publicaties/ECN-E--10-076, last access: 15 October 2019, 2010b. a
Walsh, P. and Pollock, R.: Data Package, available at: http://frictionlessdata.io/data-packages (last access: 15 October 2019), 2019. a
Werkhoven, E. J. and Verhoef, J. P.: Meteorological mast IJmuiden: Abstract of instrumentation report, Tech. Rep. ECN-Wind Memo-12-010, ECN, https://www.windopzee.net/fileadmin/windopzee/user/ECN-Wind_Memo-12-010_Abstract_of_Instrumentatierapport_Meetmast_IJmuiden.pdf, last access: 15 October 2019, 2012. a
Westerhellweg, A., Neumann, T., and Riedel, V.: FINO1 Mast Correction, DEWI Magazin, p. 60–66, https://aws-dewi.ul.com/dewi-magazine-issue-40-2-2012/ (last access: February 2020), 2012. a
Wickham, H.: Tidy Data, J. Stat. Softw., 59, 1–23, https://doi.org/10.18637/jss.v059.i10, 2014. a
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.-W., da Santos, L. B. S., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Dumon, O., Edmunds, S., Evelo, C. T., Finkers, R., Gonzalez-Beltran, A., Gray, A. J., Groth, P., Goble, C., Grethe, J. S., Heringa, J., 't Hoen, P. A., Hooft, R., Kuhn, T., Kok, R., Kok, J., Lusher, S. J., Martone, M. E., Mons, A., Packer, A. L., Persson, B., Rocca-Serra, P., Roos, M., van Schaik, R., Sansone, S.-A., Schultes, E., Sengstag, T., Slater, T., Strawn, G., Swertz, M. A., Thompson, M., van der Lei, J., van Mulligen, E., Velterop, J., Waagmeester, A., Wittenburg, P., Wolstencroft, K., Zhao, J., and Mons, B.: The FAIR Guiding Principles for scientific data management and stewardship, Sci. Data, 3, 160018, https://doi.org/10.1038/sdata.2016.18, 2016. a, b
World Meteorological Organization: Manual on Codes, updated 2011 edn., available at: https://library.wmo.int/opac/index.php?lvl=notice_display&id=13617 (last access: 15 October 2019), 2016. a, b
We follow the Joint Committee for Guides in Metrology (2012) in our usage of “(measurement) accuracy” and “(measurement) uncertainty”. Namely, the former refers to a qualitative description of the “closeness of agreement between a measured quantity value and a true quantity value of a measurand” and the latter to a quantitative measure, i.e., a “non-negative parameter characterizing the dispersion of the quantity values being attributed to a measurand, based on the information used”. These terms cover both systematic and random aspects.
Personal communication on 27 June 2017 with Richard Fruehmann (see Acknowledgements).
In text files, every decimal digit costs 8 bits (1 B) to store, so a length-n number requires 8n bits. In binary formats, a more efficient encoding is used (numbers as bit strings), requiring m bits. To round-trip from decimal to binary and back, is sufficient (Matula, 1968). This picture does not change substantively if sign and magnitude are taken into account. In practice a 32-bit binary format is used for storing values, which uses 23 bits for representing the significand, sufficient for six decimal significant digits; 1 bit is used for the sign and 8 for the exponent.
Since the work reported on in this paper was carried out, ECN has become part of TNO, the Netherlands Organisation for applied scientific research. Its name will change in the coming period.