the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 16 Mar 2022
| 16 Mar 2022
Model updating of a wind turbine blade finite element Timoshenko beam model with invertible neural networks
Pablo Noever-Castelos
David Melcher
Claudio Balzani
Digitalization, especially in the form of a digital twin, is fast becoming a key instrument for the monitoring of a product's life cycle from manufacturing to operation and maintenance and has recently been applied to wind turbine blades. Here, model updating plays an important role for digital twins, in the form of adjusting the model to best replicate the corresponding real-world counterpart. However, classical updating methods are generally limited to a reduced parameter space due to low computational efficiency. Moreover, these approaches most likely lack a probabilistic evaluation of the result.
The purpose of this paper is to extend a previous feasibility study to a finite element Timoshenko beam model of a full blade for which the model updating process is conducted through the novel approach with invertible neural networks (INNs). This type of artificial neural network is trained to represent an inversion of the physical model, which in general is complex and non-linear. During the updating process, the inverse model is evaluated based on the target model's modal responses. It then returns the posterior prediction for the input parameters. In advance, a global sensitivity study will reduce the parameter space to a significant subset on which the updating process will focus.
The finally trained INN excellently predicts the input parameters' posterior distributions of the proposed generic updating problem. Moreover, intrinsic model ambiguities, such as material densities of two closely located laminates, are correctly captured. A robustness analysis with noisy response reveals a few sensitive parameters, though most can still be recovered with equal accuracy. And, finally, after the resimulation analysis with the updated model, the modal response perfectly matches the target values. Thus, we successfully confirmed that INNs offer an extraordinary capability for structural model updating of even more complex and larger models of wind turbine blades.
- Article
(8173 KB) - Full-text XML
- BibTeX
- EndNote





Wind turbine blades are enormous composite structures exposed to extreme and harsh environmental conditions. Due to these circumstances, structural health or condition monitoring plays a critical role in reliably ensuring the endurance of the rotor blade. However, this raises the need for an accurate model representation of the structure as built. In this context, the digital twin is emerging as a powerful instrument (Grieves, 2019) for these monitoring systems during operational time, though it can already be involved in early stages of manufacturing (Sayer et al., 2020). The concept of model updating is central to achieving a digital product twin, for example, by updating the preliminary blade design based on sensor responses from blade characterization tests. This process of model updating ensures that the current stage of the digital twin represents the blade as built.
1.1 Model updating of wind turbine blades
Model updating has grown in importance in light of digitalization of the wind turbine blades; however, it has only been marginally explored in the literature. Similarly to other structural dynamic model updating applications (Sehgal and Kumar, 2016), the publications on rotor blade model updating typically follow metaheuristic optimization techniques and define the objective function based on the modal assurance criterion (MAC), which represents a common metric for the quantitative comparison of modal shapes (Pastor et al., 2012). Other related modal metrics can be found in Allemang (2003). The most recent publications, such as Hofmeister et al. (2019) and Bruns et al. (2019), apply classical metaheuristic optimization algorithms to update the model parameters and localize damage in a generic problem with a finite element beam blade model. These publications evaluate a global pattern search and compare it to evolutionary, particle swarm, and genetic optimization algorithms. The objective function is based upon the natural frequencies and the MAC value. Furthermore, the MAC and the coordinate modal assurance criterion (COMAC) are applied in the model updating process of a finite element shell model of a rotor blade conducted by Knebusch et al. (2020). That study aims to update the blade model of a built blade along with high-fidelity modal measurements and a gradient-based optimization approach. Another approach presented by Schröder et al. (2018) uses a two-stage metaheuristic optimization to detect damage and ice accretion on a rotor blade. A global optimization with a simulated quenching algorithm is followed by a local method (sequential quadratic programming) to minimize the objective function, consisting of natural frequencies and mode shapes. Omenzetter and Turnbull (2018) implemented metaheuristic optimization methods (fireflies and virus optimization) to detect damage in a finite element beam model of a blade and compare the performance to a simplified beam experiment. Other publications cover simplified model updating procedures of low-level wind turbine blade models (Velazquez and Swartz, 2015; Liu et al., 2012; Lin et al., 2018). While most of the referred contributions focus on the field of damage detection, the model updating conducted by Luczak et al. (2014) highlights the impact of a flexible support structure of the test setup of modern blades, which was also revealed by Knebusch et al. (2020).
1.2 Drawbacks of current updating approaches
Most of these publications encounter three major problems:
-
Due to the aforementioned computational effort, the studies have been restricted to simple models.
-
They typically lack an efficient probabilistic approach to evaluate the uncertainty in the results.
-
All approaches only address one particular state of the blade at a defined condition and not a generalized inverse model.
The aforementioned approaches can be classified as deterministic and thus lead to results which are not necessarily the global optima. Therefore, these methodologies may require the process to be run several times to ensure result validity (Schröder et al., 2018; Omenzetter and Turnbull, 2018). This is especially problematic since metaheuristic optimization algorithms are computationally expensive due to their iterative model evaluation (Chopard and Tomassini, 2018). As a reference, Bruns et al. (2019) performed 500 iterations for two updating parameters and 1500 iterations for five updating parameters, while in Omenzetter and Turnbull (2018) the firefly optimization of two updating parameters required 157 iterations until convergence and the virus optimization required 5000 iterations. Newer model updating techniques involve probabilistic approaches such as a sensitivity-based method (Augustyn et al., 2020) or Bayesian optimization (Marwala et al., 2016). The latter is based on sampling techniques such as Markov chain Monte Carlo methods to cover the complete parameter space. However, these approaches typically require even more model evaluations as stated in Patelli et al. (2017). There, a relatively simple model of a 3-degree-of-freedom (DOF) mass-spring system demanded 12 000 samples for the Bayesian solution, which was approximately 10 times higher than for the sensitivity-based method. Iterations are always model dependent, but to give a reference for real-time consumption, the model generator used in this publication (Noever-Castelos et al., 2021) takes on average approx. 80 s on a single-core device for one iteration, i.e., model creation. And finally, from the model updating we obtain one solution of input parameters for a particular set of model response parameters. However, if the model response changes, the whole optimization process has to be repeated. While in most applications a solution for a particular model is sufficient, an inverted model, which maps model responses to input parameters, can be beneficial, e.g., in quality management during serial production. This reveals a niche for an efficient method to invert the physical model, enabling a fast evaluation of the model states at any time.
1.3 Model updating via invertible neural networks
This research framework is based on Noever-Castelos et al. (2021), a feasibility study on a first structural level of wind turbine blades. The research performs a model updating with conditional invertible neural networks (cINNs) (Ardizzone et al., 2019b) for four selected cross-sections of a wind turbine blade. Noever-Castelos et al. (2021) consider a set of material and layup parameters as updateable inputs and take cross-sectional structural beam properties, such as stiffness and mass matrix, as model outputs to define the objective values. A sensitivity analysis following a one-at-a-time approach identified a parameter subspace selection of 19 significant input parameters for the updating process. The specific objective of this current investigation in contrast to the aforementioned publication (Noever-Castelos et al., 2021) is to
-
extend the feasibility study and methodology to a complete three-dimensional finite element Timoshenko beam model of a wind turbine blade as applied in real-world problems, instead of analyzing isolated cross-sections;
-
introduce parameter splines for the input variation along the blade;
-
use modal blade shapes and frequencies as the model response;
-
replace the sensitivity analysis for the parameter subspace selection by the global variance-based Sobol' method (Sobol', 1993), which takes interactions of input parameters into account;
-
implement a preprocessing feed-forward neural network for the cINN conditions;
-
analyze the potential of replacing or neglecting the sensitivity analysis by training the cINN on the full parameter space.
However, this investigation is still designed to reveal the feasibility with respect to a complex full three-dimensional Timoshenko beam model, before applying the method to a high dimensional real-world and non-generic problem.
1.4 Outline
This study will follow the outline of Noever-Castelos et al. (2021). The first section after the Introduction presents the sensitivity analysis procedure and discusses the physical model built in MoCA (Model Creation and Analysis Tool for Wind Turbine Rotor Blades) (Noever-Castelos et al., 2022) and BECAS (BEam Cross section Analysis Software) (Blasques and Stolpe, 2012). The chosen architecture of the cINN is explained in Sect. 3. Section 4 covers the discussion of results, with a general analysis of the updating results in Sect. 4.1. Section 4.2 reveals intrinsic model ambiguities before the model robustness to noisy model responses is examined in Sect. 4.3. A resimulation analysis to ensure high updating quality is performed in Sect. 4.4. Section 4.5 presents a method to replace the computationally expensive sensitivity analysis. This is then all followed by the conclusion in Sect. 5.
Typically a physical model consists of several input parameters defining the model behavior. The model is then evaluated, or simulations are performed, which yield a model response. However, not all input parameters equally contribute to the particular model response. A sensitivity analysis helps to identify the most significant input parameters. It is an underestimated powerful tool to reduce the model dimensions without losing significant information. Especially for model updating purposes this can make a huge difference in performance. This section will discuss the applied sensitivity method as well as the applied model and parameter subspace selection.

Figure 1Exemplary finite element beam with reduced number of elements and exemplary cross-sectional illustration. The detail shows a cross-sectional BECAS output (Blasques and Stolpe, 2012) as used in the feasibility study (Noever-Castelos et al., 2021).
2.1 Sobol' sensitivity method
Noever-Castelos et al. (2021) performed a sensitivity analysis to reflect how input distributions influence the output distribution's variance and mean value in order to identify relevant input and output features for the model updating process with the invertible neural network. There, a one-at-a-time approach is used, where values vary individually and their impact on the output is analyzed. In contrast to Noever-Castelos et al. (2021), this contribution will make use of a variance-based approach, called the Sobol' method, or Sobol' index (Sobol', 1993, 2001). This method is widely used in research and is used here, as it also applies globally to non-linear models and analyzes the influence of input parameter interaction on the model response. For a multivariate function y=f(x1, …, xn), Sobol' derived the first-order Sobol' index Si for the variable xi as follows:
This is a measure of to what extent the impact of varying xi will have on the output y. On the basis of a random sampling of the parameters x, 𝔼(y|xi) represents the expectation E of all y values for a constant value of xi. It can be understood as an average of y corresponding to a slice of the xi domain in the parameter space. V[𝔼(y|xi)] is then the variance of all expectations over the range of values of xi, i.e., slices of the xi domain (Saltelli et al., 2008). This variance is finally related to the overall variance of y. The first-order Sobol' index range is . Higher-order Sobol' indices can also be extracted, see Saltelli et al. (2008), which measure the sensitivity of parameter interactions. For instance the second-order Sobol' index shows the joint effect of two parameters on the output, whereas third indices express the joint effect of three parameter interactions and so on. Although these indices can give a significant insight into the model, such as existing collinearities, the number of indices grows geometrically with the number of parameters, which quickly makes the computation intractable. However, the total Sobol' index gathers the total sensitivity for a parameter including the first-order and all higher-order interactions. According to Saltelli et al. (2008) the total index is calculated as follows:
where describes the variance of all expectations over the range where xi is not included. If the model is purely additive for a particular parameter, the corresponding total Sobol' index should be equal to the first-order index. While the total index does not provide the information about which interaction is significant, it does identify if any interaction exists, with the benefit that it is computed alongside the first-order Sobol' index without any significant additional computational effort.
For a multivariate function with multiple outputs (y1, …, ym)=f(x1, …, xn), Eqs. (1) and (2) can be expressed, respectively, as
2.2 Rotor blade finite element beam model
The necessary model generation and variation are performed with the model creator MoCA (Noever-Castelos et al., 2022) and its interface to BECAS (Blasques and Stolpe, 2012) to create cross-sectional beam properties, which are assembled into a finite element beam (FE beam) and evaluated in ANSYS Mechanical (ANSYS Inc., 2021a). We will be performing the analysis on the DemoBlade of the SmartBlades2 project (SmartBlades2, 2016–2020). Figure 1 depicts a coarse version of the FE beam used in this study. In contrast to this simplified visualization in Fig. 1, the applied FE beam model is built of 50 three-dimensional linear beam elements (BEAM188) (ANSYS Inc., 2021a) with higher mesh density to the root and tip sections of the blade, where greater geometrical and material changes are expected. Thus, the finite element model consists of 51 nodes (NFE). The input parameter selection of Noever-Castelos et al. (2021) was slightly expanded to cover more material properties, which will be discussed in detail later. The input parameter selection spans a space with a maximum dimension of for each cross-section, though varying these for each of the 50 cross-sections would result in 𝔻tot=1650 parameters. Assuming a smooth variation in each parameter over the radius, Akima splines (Akima, 1970) were introduced to represent the parameter variation along the blade. An exemplary spline is depicted in Fig. 2. The spline is built based upon five equidistant nodes that may vary in the y direction within the given variation range of the parameter. The number of spline nodes can be chosen arbitrarily; however, a high number increases the computational costs (more updating parameters) and can lead to collinear behavior if the nodes are too near, whereas a low number reduces the flexibility to adapt to short-distance changes. For this study the number were chosen based on experience as a trade-off between computational costs and a sufficient approximation of a global parameter variation.

Table 1 summarizes all the investigated input parameters xi and corresponding properties. Moreover, Table 1 lists the number of spline nodes with their respective normalized radial range and variance limits for each property. In this feasibility study, we consider the most significant independent elastic properties for each material – the density ρ, Young's modulus E11, the shear modulus G12, and Poisson's ratio ν12 – which may be varied over all five nodes in a range of ±10 %. Here, we have neglected all thickness-related elastic constants, i.e., parameters including the index/direction 3 and E22, as these parameters offer no significant contribution to the stiffness terms of the beam cross-sectional properties according to Hodges (2006) and Noever-Castelos et al. (2021). Since foam is modeled as an isotropic material, only two independent elastic properties E and G and the density ρ are considered. In addition to the material properties, the division points are also varied. These subdivide the shell in the cross-sectional direction into different sections with a constant material layup or define sub-component positions such as the web or adhesive (Noever-Castelos et al., 2022). The division point parameters P are allowed to vary on the three mid-nodes by the given absolute range. The root and tip nodes cannot be varied due to model generation issues within MoCA; thus the variance for node N0 and N4 will be kept at zero, similarly to in Fig. 2. All applied variations are approximately twice the permitted manufacturing tolerances (Noever-Castelos et al., 2021) in order to assure some flexibility of the inverse model. Summing up all parameters and nodes, the problem spans a parameter space of dim(x)=153. The sensitivity study is conducted based on the Python package “SALib” (Herman and Usher, 2017) and a random sampling dimension of samples. SALib uses the quasi-random sampling with a low-discrepancy sequence technique from Saltelli et al. (2008) for the sensitivity analysis. To compute the Sobol' index, the algorithms require a variation in each input feature individually for each of the n samples, which results in a total sample size of to compute the first-order and total Sobol' indices. The sensitivity study as well as the updating process is based on the modal beam response y, as described in Gundlach and Govers (2019), in a free–free and a clamped scenario, which are comparable to an elastic suspension of the blade and a fixation of its root to a test rig, respectively. In each case, the first 10 eigenmodes are extracted, excluding the rigid body motion modes in the free–free scenario. For all 10 mode shapes of each configuration (free–free and clamped), the natural frequency and the three deflections and three rotations of each finite element beam node NFE are saved. These are collected in a response matrix with columns. Throughout this paper, input parameters and model responses will also be referred to as input and output features or conditions, respectively.
Table 1Input feature list analyzed in this study. Each feature and property builds a distribution spline based on the given number of equidistant nodes within the given normalized radial range of the blade. Each node value may then vary in the listed variance range.
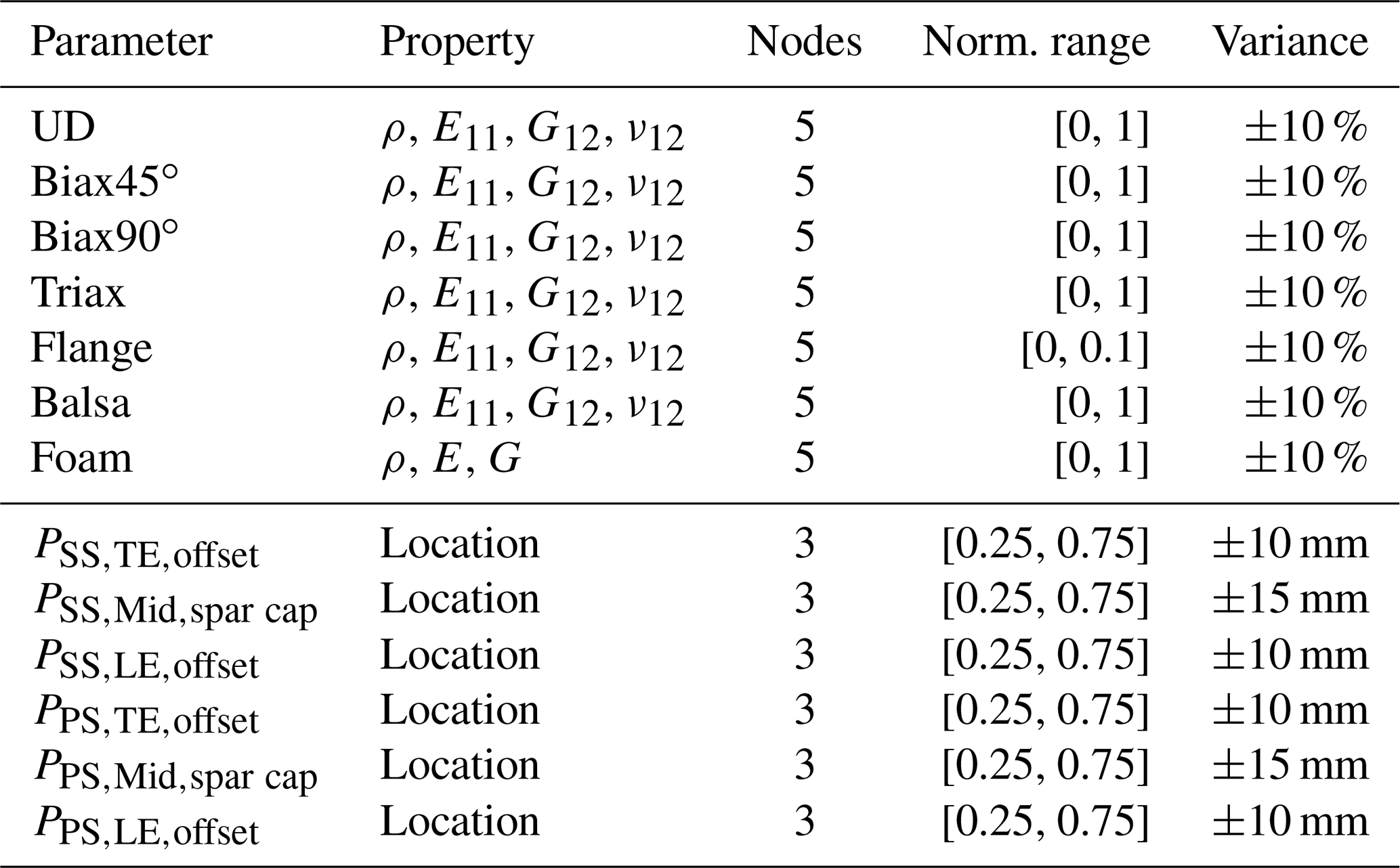
UD: uni-directional layer; Biax45∘: biaxial layer with −45, +45∘; Biax90∘: biaxial layer with 0, 90∘; Triax: triaxial layer with −45, 0, 45∘; SS: suction side; PS: pressure side; TE: trailing edge; LE: leading edge.
2.3 Feature subspace selection with Sobol' indices
After computing the first-order and total Sobol' index Sij and STij, respectively, for each input feature xi and output feature yi at every NFE position, we obtain a matrix of size , i.e., . For the subspace selection we follow two selection methods:
-
by computing the maximum-appearing first-order Sobol' index of each input feature and comparing it to a threshold;
-
by performing singular value decomposition (SVD) on the total Sobol' sensitivity matrix to identify the most relevant contributions and mapping these back onto the input feature with a QR factorization with column pivoting (Chakroborty and Saha, 2010; Olufsen and Ottesen, 2013).
The selected subspaces are merged into a final subspace, which is applied for the model updating process.
For the first selection method the sensitivity matrix containing the first-order Sobol' index is condensed into a single maximum value Smax,i for each input feature xi. Therefore, it is reduced to identify relevant input features y by computing the maximum value along the other non-corresponding dimensions, i.e., dimensions 2 and 3. Subsequently, an arbitrary threshold Sthld is defined to reject all features with a lower maximum index Smax,i. By this, we aim to consider only features which have a significant impact during at least one event at one location, thus containing enough information for the updating process. Based on experience, we have chosen Sthld=0.1.
The second method follows a combination of SVD and QR factorization on the sensitivity matrix of the total Sobol' index according to Chakroborty and Saha (2010) for a given set of n input parameters x. Here each mode shape is analyzed individually. Therefore, the sensitivity matrix is divided and reshaped; the first dimension, i.e., the 6 DOFs plus frequency, and second dimension, i.e., the node positions NFE, are flattened, while the third dimension, i.e., input features, is kept yielding an (m×n) matrix. Given this individual total Sobol' sensitivity matrix ST for each mode shape, the singular value decomposition according to Golub and van Loan (2013) is
U and V denote the left and right singular vector matrices, each column corresponding to the singular values in with . According to Chakroborty and Saha (2010), the criterion percentage of energy explained by the singular values is used to identify the g most relevant features. The percentage of energy Pex is calculated as the normalized cumulative sum of the singular values:
The number of relevant singular values g is equal to the highest number g complying with Pex≤99 %. The rest of the singular values, p−g, only contribute to 1 % of the total energy and are therefore insignificant for the result.
A subsequent QR factorization with column pivoting (Golub and van Loan, 2013) is used according to Olufsen and Ottesen (2013) and Chakroborty and Saha (2010) to extract the order of the original input vector x, by sorting the columns of the left singular vector matrix V of size n×n in order of maximum Euclidean norm in successive orthogonal directions:
Here, Q is a matrix with orthonormal columns, R is an upper triangular matrix, and P is the permutation matrix. In this particular case of a square matrix V, all matrices are of the same dimension as V. The permutation matrix P is finally applied to the input parameter vector x to re-sort the vector according to sensitivity significance:
The sorted input vector xs is than reduced to the first g entries, representing the most significant parameters for the analyzed mode shape following the criterion explained above. After computing all xs values for each mode shape, they are all merged into a final set of input parameters determined to be relevant for at least one mode shape. With this SVD-QR method applied to the total Sobol' indices matrix, the authors tried to identify parameters that are significant either on their own or in interaction with others. However, the significance is not measured as the maximum value on one occasion, such as in the first method, but rather contributes substantially on average over a complete mode shape.
Both methods lead to the 49 selected features depicted in Table 2 with their respective Smax values and a checkmark showing the selection by the SVD-QR method.
Table 2Selected feature list from sensitivity study with the features' respective maximum first-order Sobol' indices Smax,i (values shown in bold meet the given threshold Sthld=0.1) and the selection mark for the SVD-QR method.

When analyzing the rejections, it has to be noted that all structural properties are condensed to cross-sectional beam properties. That means, for example, Biax45∘ as a face layer of the shear web is typically located near the elastic and gravitational center of the cross-sections and thus does not contribute in excess to the mass inertia according to the Steiner theorem or to the overall bending stiffness (Gross et al., 2012). Consequently, a variation in ρBiax45 and E11,Biax45 will not significantly impact the modal response of the beam model. However, its shear modulus G12,Biax45 does have an impact when dealing with the shear forces from flap-wise loading. Regarding foam and balsa as sandwich core materials, the stiffness contribution to the sandwich panels is approximately 1 % compared to the GFRP (glass-fiber-reinforced plastic) face sheets, and this makes their variations neglectable, while the mass contributions depending on the layup can reach up to 66 %–100 %, which is why a few of the density spline nodes are kept. Summarizing the sensitivity analysis reduced the input feature space to dim(xsel)=45, approximately 30 % of dim(x). The output features were all kept according to the feature selection approach. However, a reduced set of radial positions can be applicable as the intrinsic information might be repeated in neighboring NFE. This repeated information does not necessarily improve the updating results but reduces the computational performance. Therefore, the output of each third node is selected, ending up with a radial output dimension of . Thus, the final dimension for the model updating process of the input feature space is and of the output feature space is .
Before proceeding to the model updating process, it is necessary to define the invertible neural network architecture. Similarly to Noever-Castelos et al. (2021), this work will build on conditional invertible neural networks (cINNs) (Ardizzone et al., 2019b) implemented in FrEIA – the Framework for Easily Invertible Architectures (Visual Learning Lab Heidelberg, 2021). A basic cINN consists of a sequence of conditional coupling blocks (CCs), as shown in Fig. 3. Each of these represents affine transformations that can easily be inverted. The embedded sub-networks s1, t1, s2, and t2 embody the trainable functions of this type of artificial neural network.
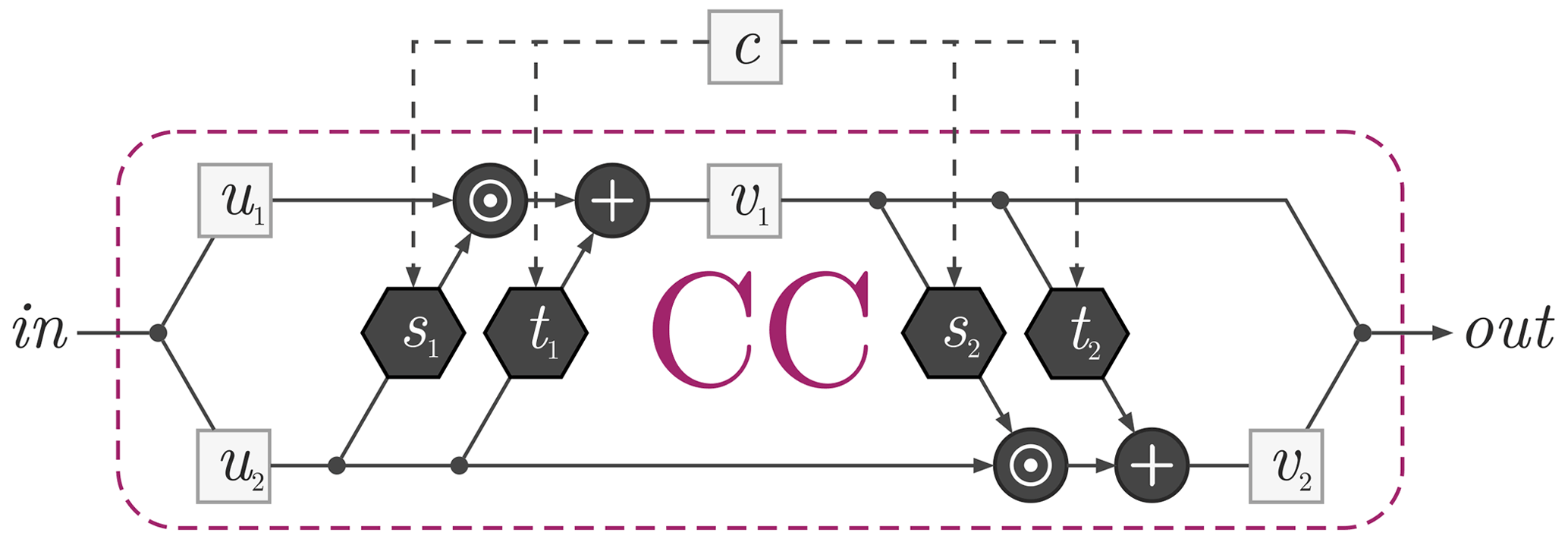
Figure 3The conditional coupling blocks (CCs) with their embedded sub-network s1, t1, s2, and t2. This CC architecture can easily be inverted (Ardizzone et al., 2019b).
These sub-networks stack the conditions c and the input slice u2 or v1 and transform them for further processing. The stacking necessarily requires similar spacial dimensions of c and u2 or v1, respectively. For a further brief introduction to cINNs with a topic-related application, please refer to Noever-Castelos et al. (2021). A more in-depth explanation can also be found in Ardizzone et al. (2019b, 2018).
After an extensive hyperparameter study, the presented investigation applies the network depicted in Fig. 4. Hyperparameters describe the network or architecture parameters of artificial neural networks, like the number of layers or perceptrons. It consists of a cINN (blue) with a sequence of 15 CCs, grouped into clusters of 3. This cINN transforms between the beam input x and the latent space z. However, unlike the underlying feasibility study of Noever-Castelos et al. (2021), an additional feed-forward network is implemented, referred to as a conditional network (orange). The idea is to preprocess the raw conditions c, i.e., beam responses, before passing them to the sub-networks in the CCs. It is trained in conjunction with the cINN to extract relevant feature information optimally for each stage. The conditional network architecture is inspired by Ardizzone et al. (2019b) and should extract higher-level features of c to feed into the sequential CCs, which, according to Ardizzone et al. (2019b), should relieve the sub-networks from having to relearn these higher-level features each time again. With a conditional beam response c of shape , the conditional network applies 1D convolutions (conv 1D) to process the data, which gradually increase in size to progressively extract higher-level features, which are fed into the different clusters of the cINN.
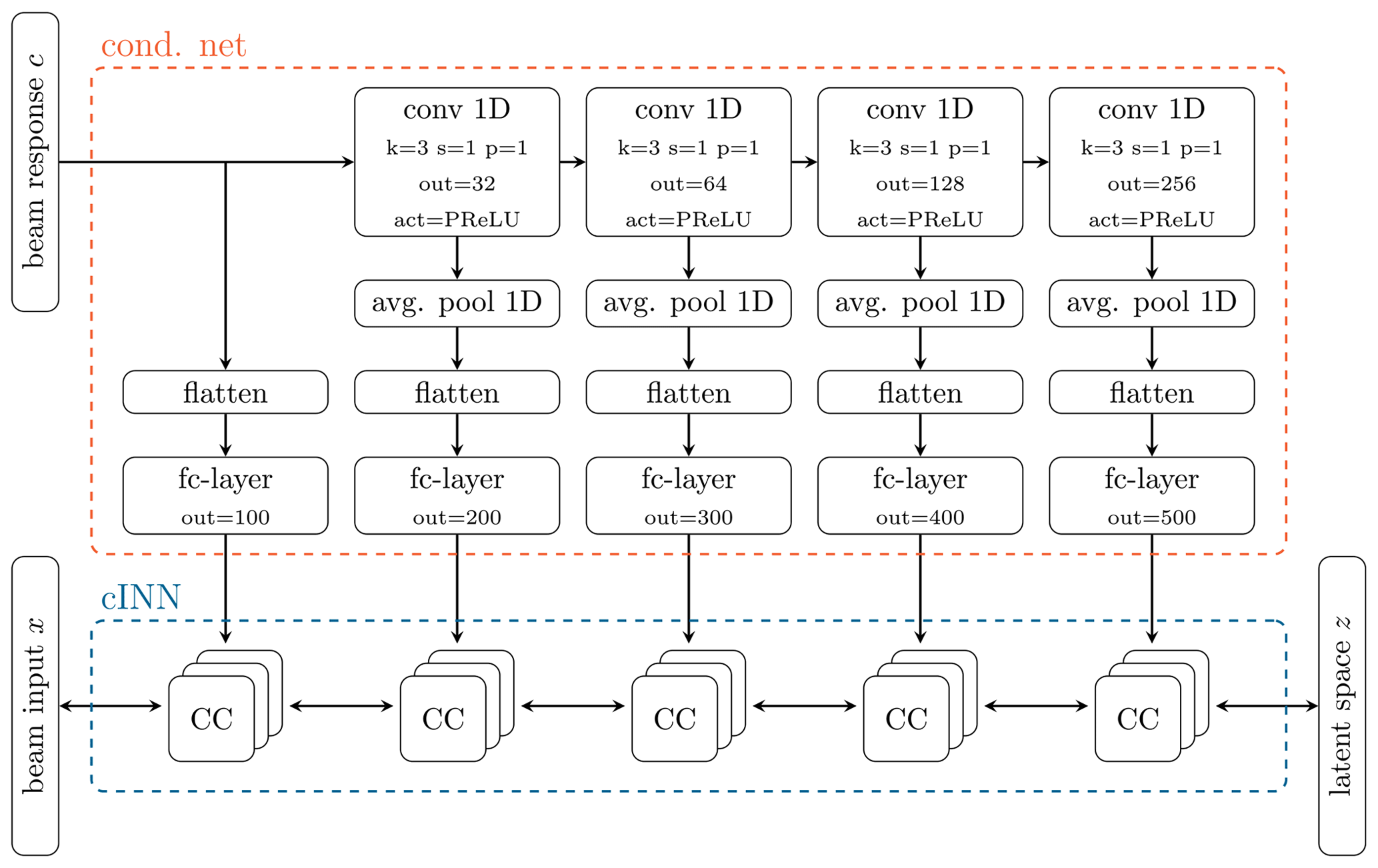
Figure 4Conditional invertible neural networks (cINNs, in blue frame) with sequentially connected conditional coupling blocks (CCs). The conditional feed-forward network (cond. net, in orange frame) preprocesses the condition y with 1D convolutional layers and PReLU (parametric rectified linear unit) activations. Average 1D pooling is performed on the output before it is flattened and reduced in dimensions with a fully connected layer (fc-layer) to be then fed into the sub-networks of the CCs. The convolutions gradually increase in size in order to progressively extract higher-level features from the condition c.
In general, the beam input would also be available in a 2D shape (property × spline nodes), though the feature selection of the sensitivity analysis reduced the splines irregularly. Thus, a 2D shape cannot be maintained anymore, as not all splines have the same number of nodes. Therefore, the selected beam input x for the updating process going into the cINN is flattened to a vector and is not present in a 2D shape, as for example the beam response c. A consequence is that the sub-networks cannot make use of convolutional layers but have to include feed-forward layers. However, this will not have any significant impact on the result. As mentioned before, the conditions and input features are stacked in the sub-networks, which thus need a similar spacial shape. Consequently, the conditional network has to flatten the shape to a vector for each output in order to agree with the input shape in the sub-networks. Before flattening the output, the conditional network activates the convolutional layer output with a parametric rectified linear unit (PReLU) (He et al., 2015) and halves the dimension with an average 1D pooling layer (Chollet, 2018) (avg. pool 1D). After flattening, the dimension is additionally reduced with a fully connected layer (fc-layer) to subsequently relieve the sub-network's computation.
Within the cINN, the CCs are clustered into groups, which are then each fed by the progressively processed conditions c. All sub-networks have one hidden fc-layer, followed by a batch normalization to improve generalization and a PReLU (Chollet, 2018) activation layer, as depicted in Fig. 5. As previously explained the conditional network processes the conditions c and has five outputs at different stages of the processing. Each of these outputs is fed into a cluster of three CCs. The configuration for each cluster and the corresponding hyperparameters for the conditional network, cINN, and sub-networks are summarized in Table 3.
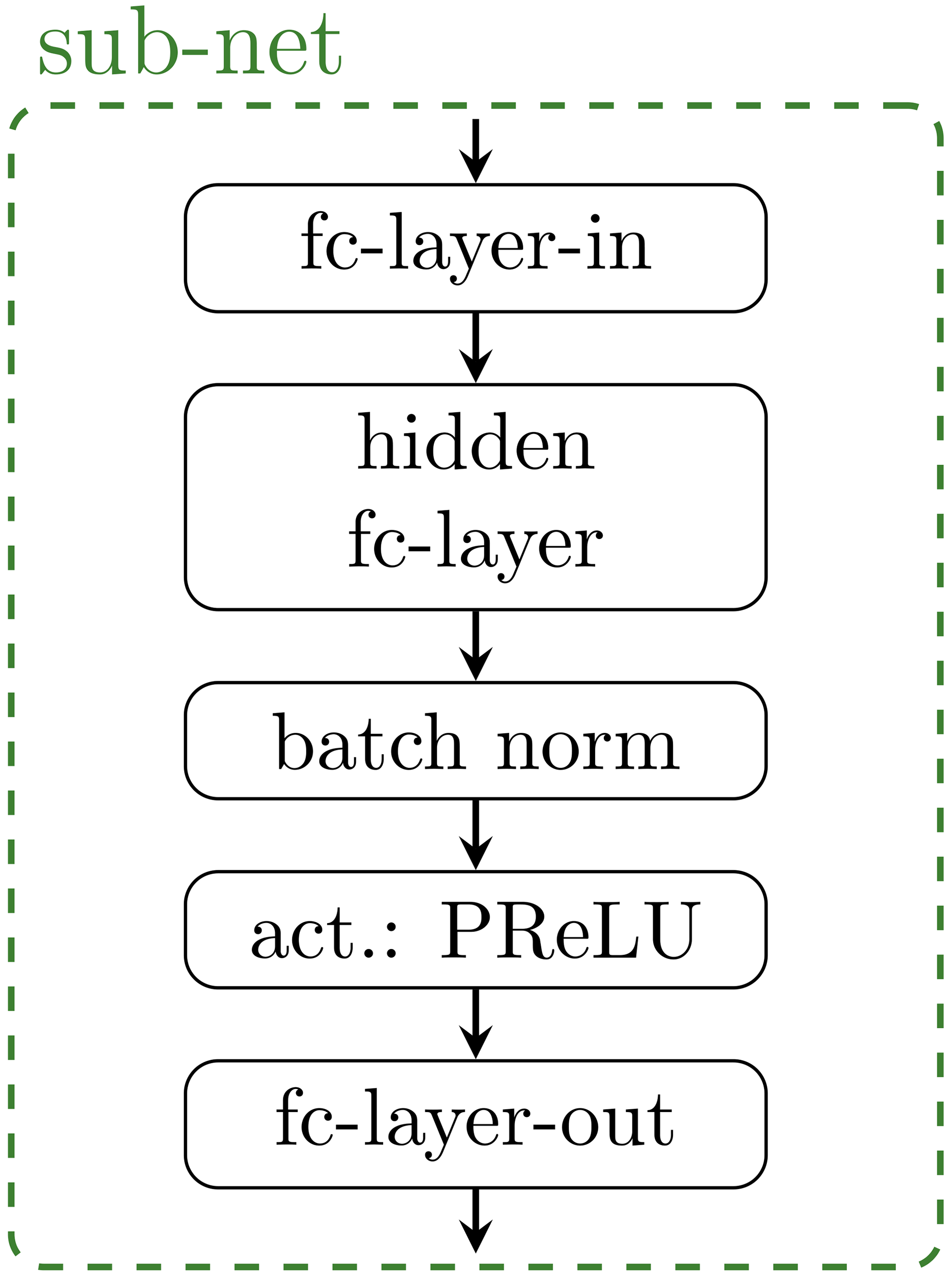
Figure 5Sub-network with one hidden fully connected layer (fc-layer), batch normalization, and a PReLU activation layer. Each conditional coupling block (CC) has such a sub-network embedded.
Table 3Hyperparameter set of the complete network, including conditional network, conditional invertible neural networks (cINNs), and sub-network. The cINN is divided into five clusters, for which the hyperparameters are listed separately. In Cluster 1, the conditions are directly fed into the conditional coupling blocks (CCs), without a prior convolutional layer (see Fig. 4).

The training is performed with an AdaGrad optimizer (Duchi et al., 2011) and an initial learning rate of 0.3, which is gradually decreased throughout the training process. The optimization minimizes the negative logarithmic likelihood (NLL) given in Eq. (9) in order to match the model's posterior prediction of px(x|y) with the true posterior of the inverse problem (Noever-Castelos et al., 2021).
Having selected the significant features with the sensitivity analysis and defined the cINN architecture, we will now move on to the model updating process and its evaluation. Therefore, the workflow of the cINN if briefly explained along with the schematic view of the transformations performed by the cINN in Fig. 6. The presented cINN in Sect. 3 is trained and tested with sample sets of input features x and their corresponding conditions c in the form of the modal beam responses as described in Sect. 2. The concept and training of the cINN are based on Bayes' theorem to infer a posterior distribution px(x|c) from a set of conditions c. Therefore, the cINN learns the conditioned transformation from the posterior distribution px(x|c) onto the latent distribution pz(z), as depicted in Fig. 6. This mapping can be achieved through maximum likelihood training. The training is performed over 150 epochs, i.e., training iterations, with a samples size of 30 000 training samples in order to minimize the negative log likelihood ℒNLL (given in Eq. 9). For a more detailed description of the inherent method of cINNs please refer to Noever-Castelos et al. (2022) or Ardizzone et al. (2019a). Additionally a sample set of 5000 test samples, which have not been seen by the cINN during its training, are used for validating and testing the cINN after the training. All input features are always sampled randomly and independently but at the same time in order to span the complete parameter space. However, only features selected by the sensitivity study (see Table 2) are passed on to the cINN as the other parameters are identified to be less relevant.
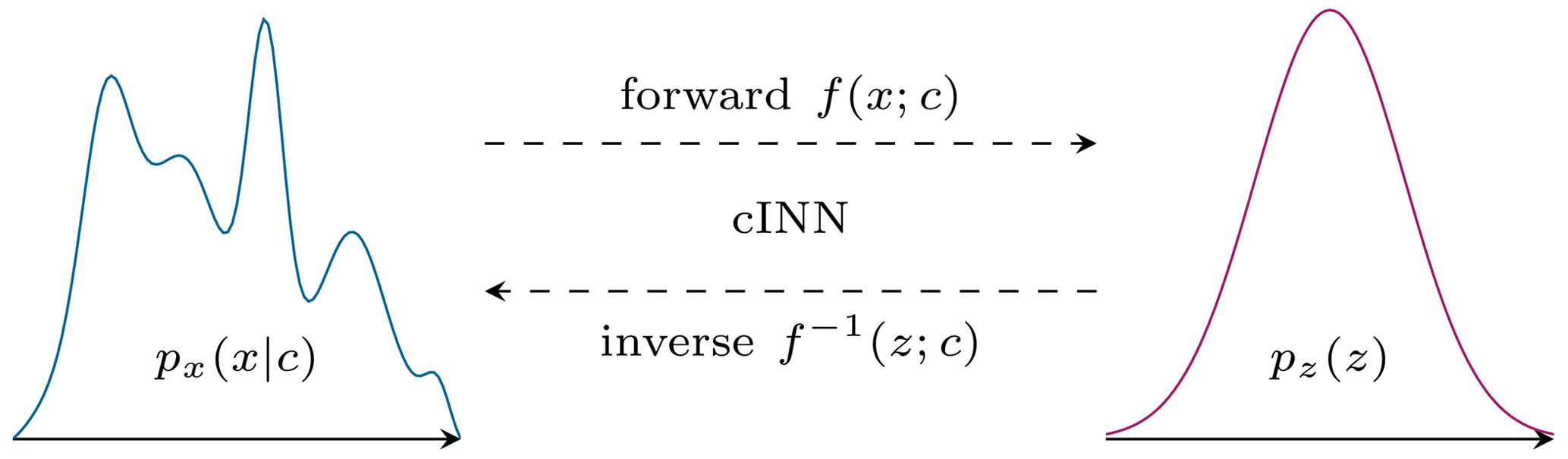
Figure 6Schematic view of the transformation between the input features x and the latent space z for a given condition c performed by the conditional invertible neural network (Noever-Castelos et al., 2021).
As the cINN is trained to map the input features x into a normally distributed latent space pz(z), during the inverse evaluation the process is reversed: the latent space is sampled from a Gaussian normal distribution (e.g., 50–100 samples), which the cINN then transforms along with the beam response as condition c to the posterior prediction of the input features. This prediction results in a distribution for each input feature px(x|y) as depicted in Fig. 6. In order to generalize the data for the training process and make them more comparable for the evaluation, all input features and conditions are standardized to zero mean and a standard deviation of 1 over the complete training set. The necessary scaling factors are additionally saved in the cINN to transform back and forth any input features or conditions used in the cINN besides the training process. Consequently, all features and conditions during the evaluation of the cINN are related to the complete training set's mean and standard deviation. Generally, the posterior predictions are also depicted with respect to their ground truth, i.e., target value of the sample, to align multiple samples for enhanced comparison.
This section first analyses the overall updating results of the model. The identified inference ambiguities are then highlighted and discussed before the model is checked against its robustness to noisy conditions cnoisy. Based on the predicted posterior distribution of the input features p(x|y), a resimulation analysis is performed where the updated parameters are used to feed the physical model and calculate the beam response in order to check the quality of the updating and sensitivity analysis results. Finally, a method for avoiding the computational intensive sensitivity analysis is presented.
4.1 General analysis of the updating results
In the first instance the posterior distributions have to be examined. Figure 7 shows as an example the predicted posterior distribution of four different input features as a histogram and fitted Gaussian distribution. The ground truth on the x axis represents the real value used to generate the sample, while the distribution is obtained from the cINN. For the further analysis, the type of distribution must be known in advance for it to be possible to apply the correct metric, e.g., mean or median. In this case of a Gaussian distribution, the mean is the most significant value and will thus be applied in this study to reduce the posterior prediction distribution to a single value accompanied by the standard deviation as a measure of uncertainty.
By shifting the former x axis from Fig. 7 onto the y axis and reducing the distributions to their mean and standard deviation, as stated before, we obtain the graphs depicted in Fig. 8 for the same exemplary sample but with all updated parameters. Most values range close to their ground truth value and with a narrow distribution, which is desired. For some input features, e.g., , the prediction is less accurate. However, the overall posterior prediction in this example is very good, as approx. 70 % of the predictions are within a range of ±0.05 (standardized scale) of the ground truth.
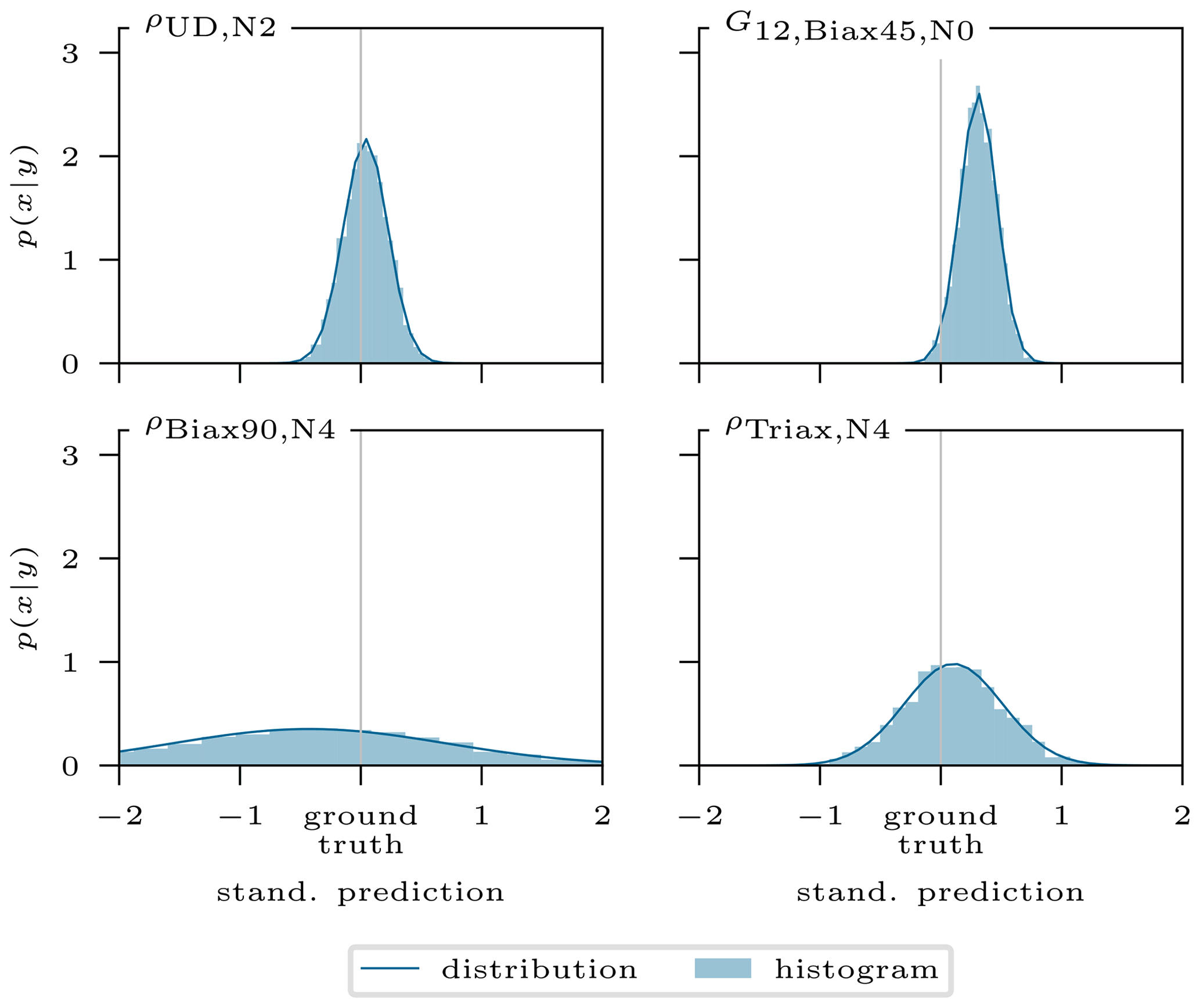
Figure 7Conditional invertible neural network's standardized posterior prediction distributions p(x|y) for four input features of one example. Plotted as a histogram and fitted Gaussian distribution.
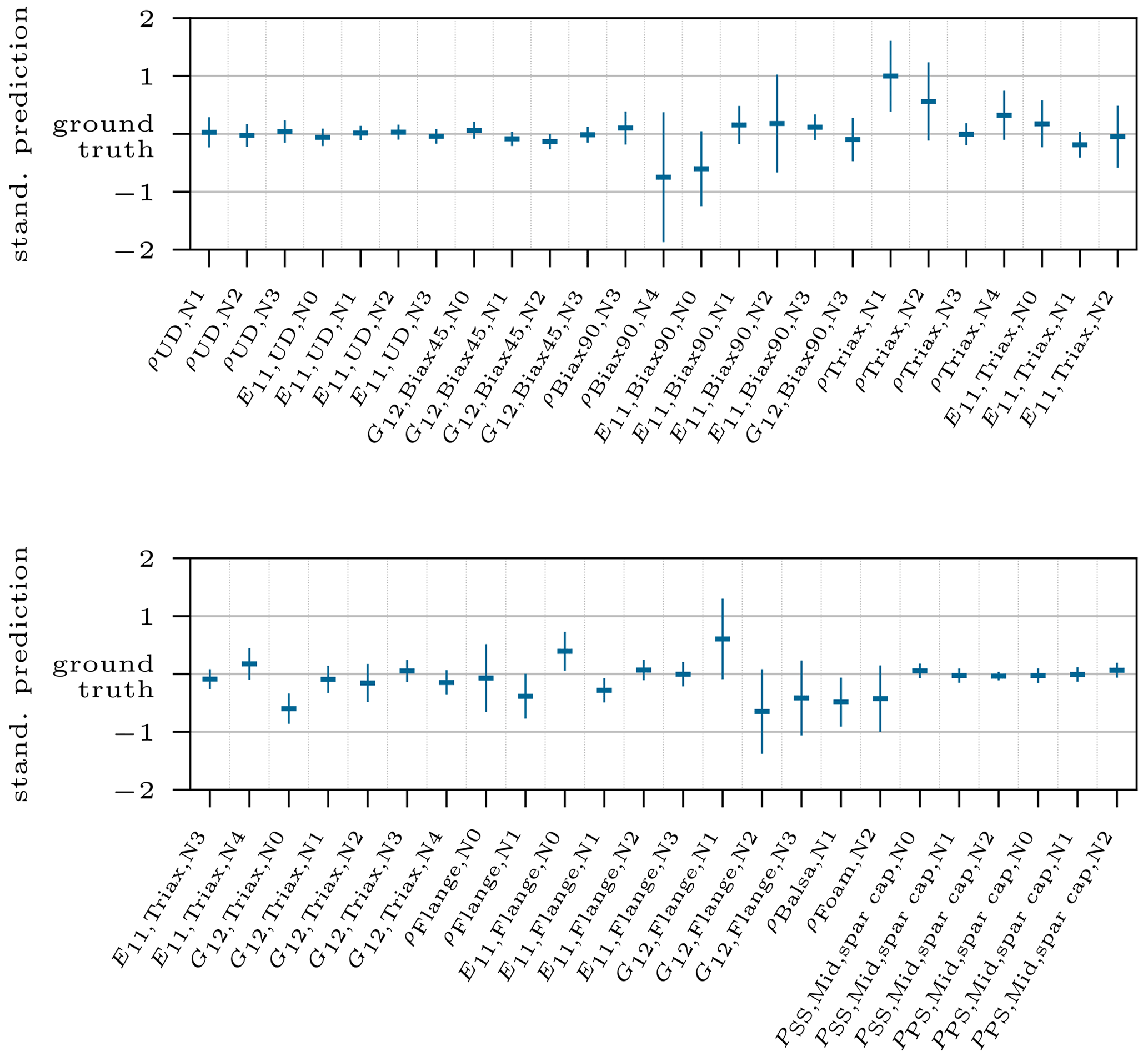
Figure 8The two graphs show the standardized posterior prediction for all updated input features related to the target value with 1σ standard deviation as error; thus the mean value marks the distance to the target value, i.e., ground truth.
After having checked the results in detail for one exemplary sample, Fig. 9 shows the prediction result of all selected input features for the 5000 test samples. The graphs scatter the standardized mean posterior predictions against their corresponding target value from the sample set. Thus, the ideal case would correlate to an exact line with a slope m=1 and an interception b=0. Each graph is equipped with the coefficient of determination R2 and shows a corresponding regression line with slope m. Approximately 70 % of the selected features reach a very satisfying linear correlation with R2>0.9 while showing a slope m of approx. 0.9 or higher. For the rest of the discussion we will be sticking with the R2 value for the accuracy, as the slope accuracy correlates with the R2 value.

Figure 9Standardized mean of posterior prediction of the updated inputs over the corresponding target standardized value for the 5000 test samples. The coefficient of determination and a corresponding linear regression line are shown. The corresponding parameter description of the features can be found in Table 2.
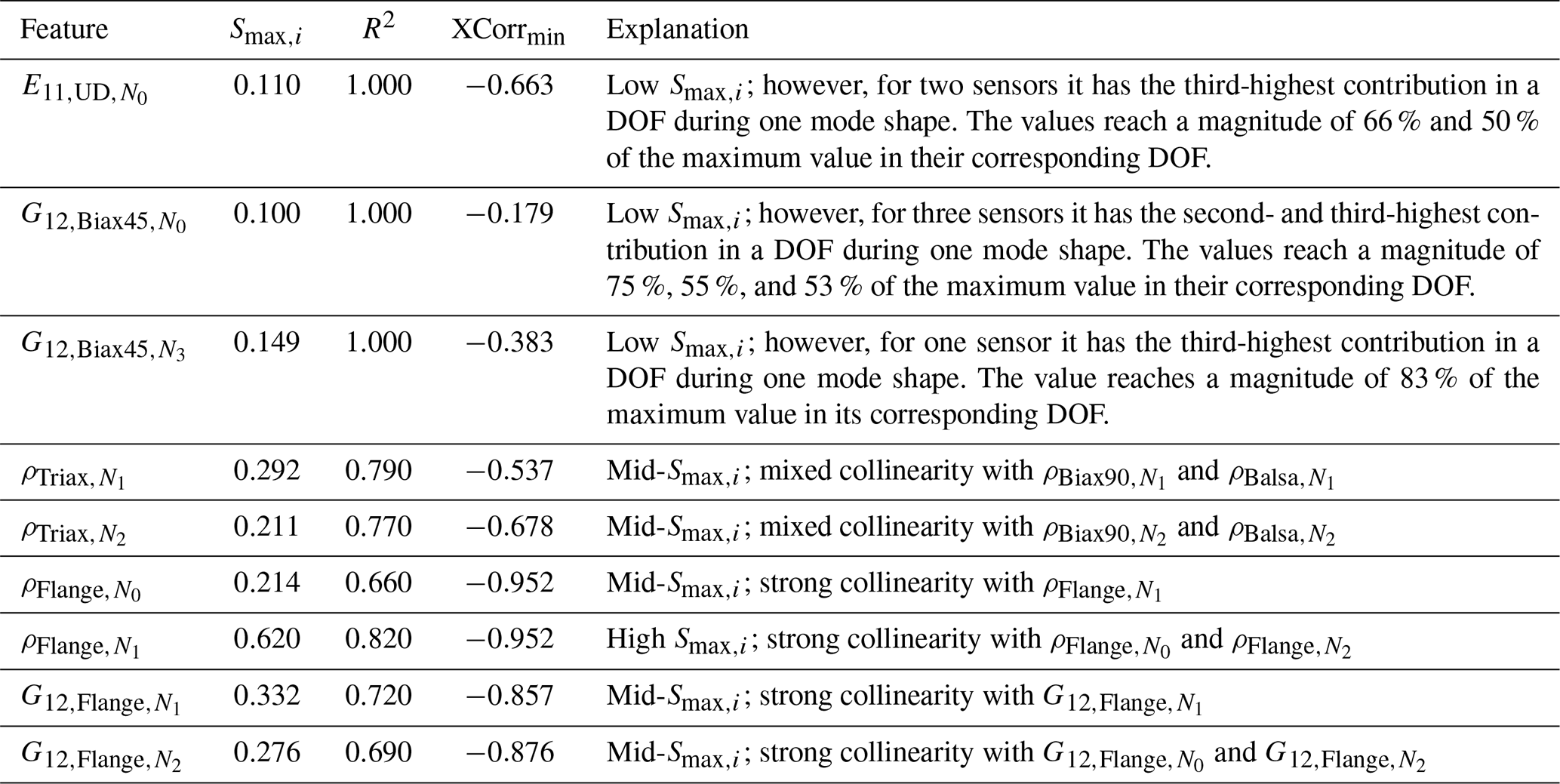
In the following we will create the link between the sensitivity results to enhance comprehension and explain possible discrepancies. In general a high sensitivity of leads to a high prediction accuracy (R2>0.9). A second major metric to fully understand the prediction accuracy is the cross-correlation of the input features, which reveals collinearities within the physical model. These present a problem for the inversion of the model as the output response of the physical model is ambiguous and can be traced back to different combinations of input features. However, this will be addressed in Sect. 4.2. Input features that do not have any substantial cross-correlation but high Smax,i reach prediction accuracies of R2≈1.0, e.g., all spar cap position points PMid,sc or Young's modulus of the UD material E11,UD. For instance, has one of the highest sensitivity index values, , but a comparably poor prediction accuracy of R2=0.82. This fact is due to a strong collinearity with the input features and . In contrast, the feature has a low sensitivity but an excellent prediction accuracy of R2=1.0. The reason for this is that this feature does not show any collinearity to other features. Although the Smax,i is low, according to the first-order Sobol' index matrix it has at three nodes NFE the second- and third-highest contribution of all input features for a particular mode shape and DOF, reaching a magnitude of 50 %–75 % of the maximum value for that DOF. That shows the powerful capability of the cINN to learn the mapping of an input feature to only very few output features out of the complete response data. Table 4 completes this list of examples with the most striking discrepancies of the sensitivity index and prediction accuracy of the input features. Hence, the sensitivity analysis is a good indication to detect a significant parameter subspace for the model updating, though high sensitivities do not directly promise highly accurate inverse prediction.
Table 4Most striking discrepancies of the sensitivity and prediction accuracy of input features.
4.2 Intrinsic model ambiguities
Ambiguities can originate from different sources, such as little significant responses or modeling issues (Ardizzone et al., 2019a). Noever-Castelos et al. (2021) revealed some intrinsic model ambiguities of counteracting density values of the Biax90∘ and Triax layer in the blade cross-section. This was also handled by the cINN in this study, although it was only checked for the two spline nodes N3 and N4 as these coincide in the feature selection. The results are depicted in Fig. 10, showing the standardized mean posterior prediction for the 5000 test samples related to their ground truth and the linear regression as well as the corresponding slope m in the label. While the mean posterior predictions at node N3 were detected rather accurately (see Fig. 8), i.e., representing a circular area in Fig. 10, the values of node N4 spread more and correlate to the plotted regression line.
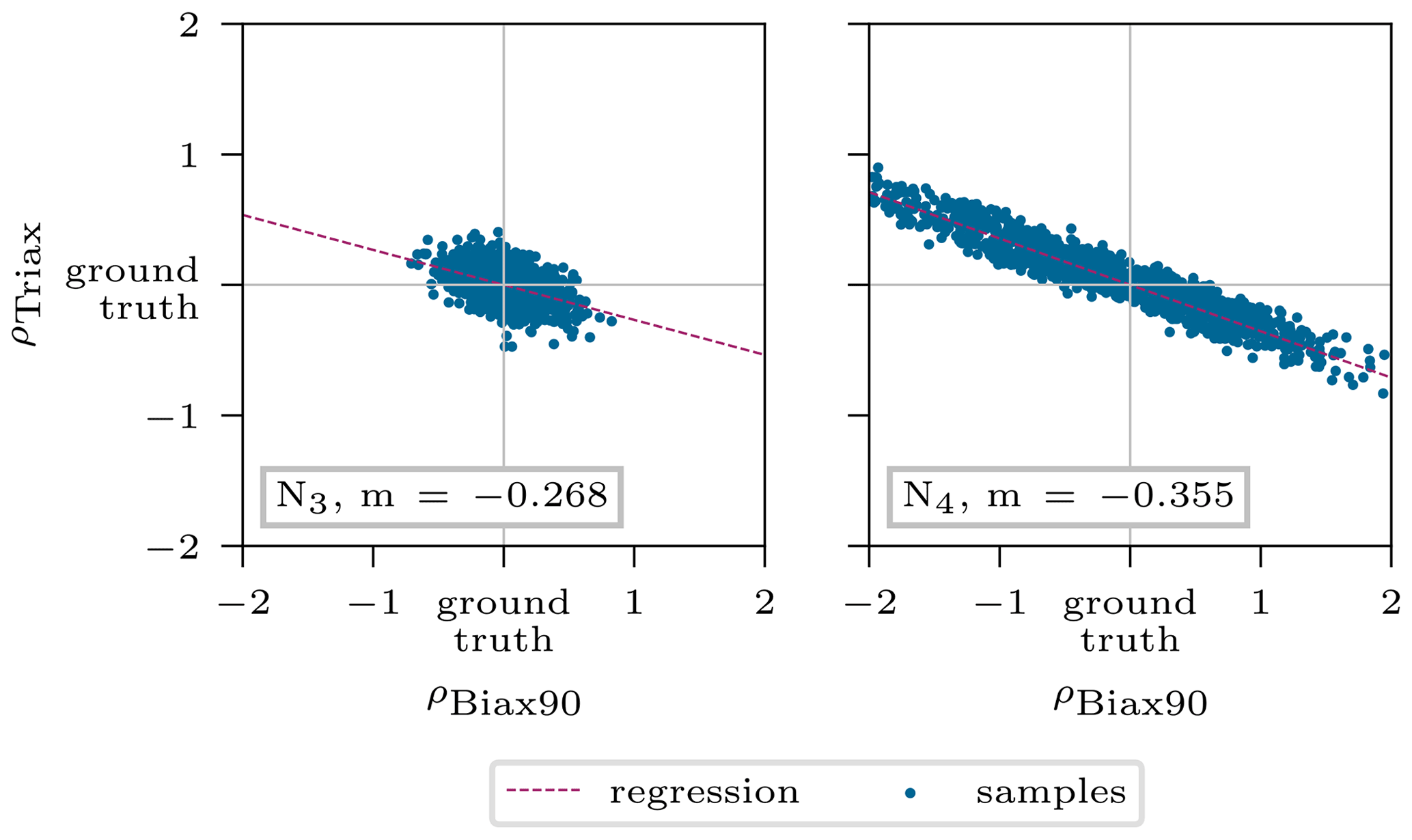
Figure 10Interaction of density ρBiax90 and ρTriax describing the intrinsic model ambiguities. The depicted values correspond to the standardized mean posterior prediction for the 5000 test samples.
In addition to the density, another ambiguity was detected in Young's modulus E11 of both these materials, shown in Fig. 11 for the nodes N0−3. Here, the correlation of the mean posterior predictions is reasonably well described by the calculated regression lines. Finally, the last correlation was found for the shear modulus between the same materials (Fig. 12).
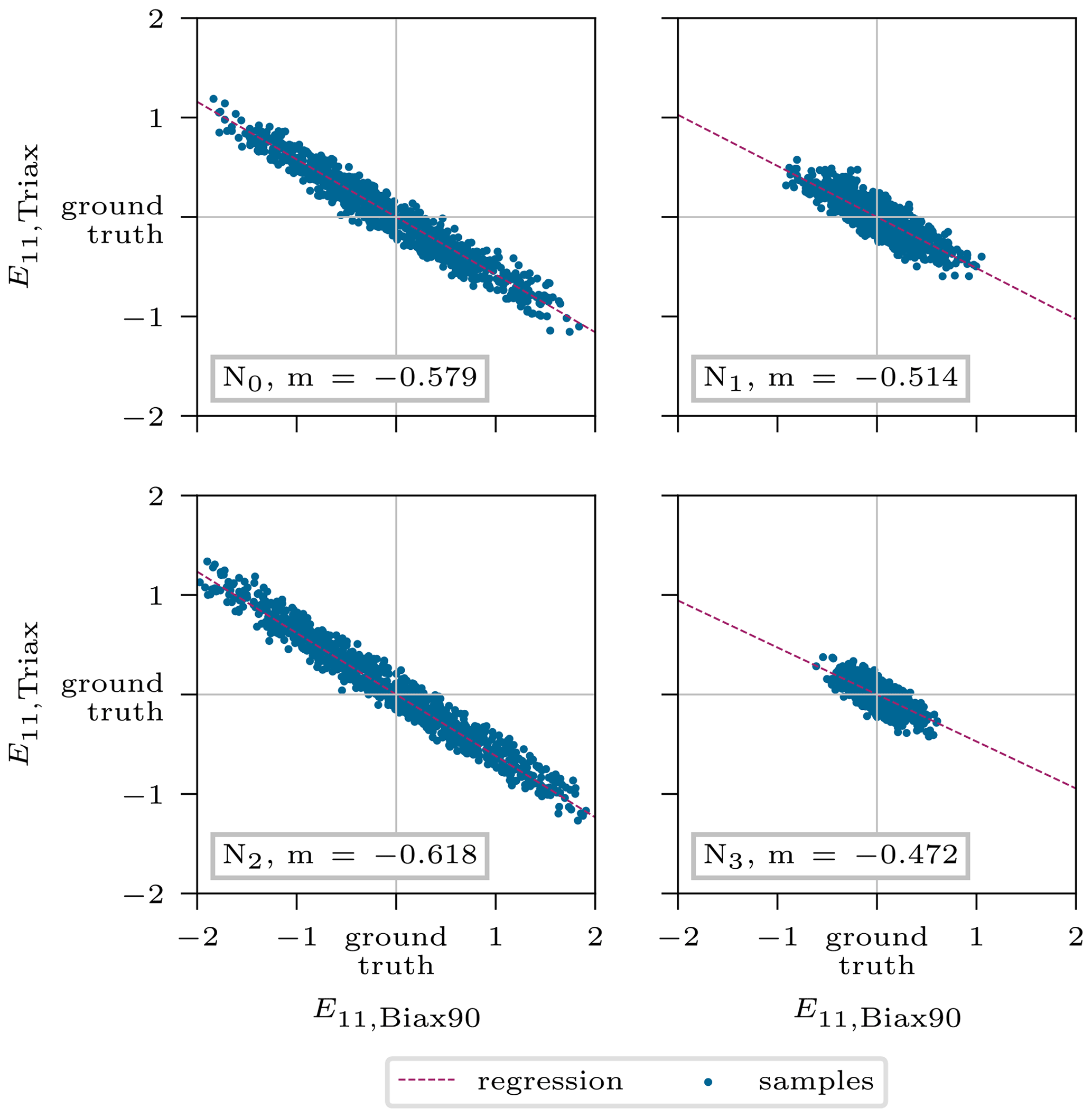
Figure 11Interaction of stiffness E11,Biax90 and E11,Triax describing the intrinsic model ambiguities. The depicted values correspond to the standardized mean posterior prediction for the 5000 test samples.
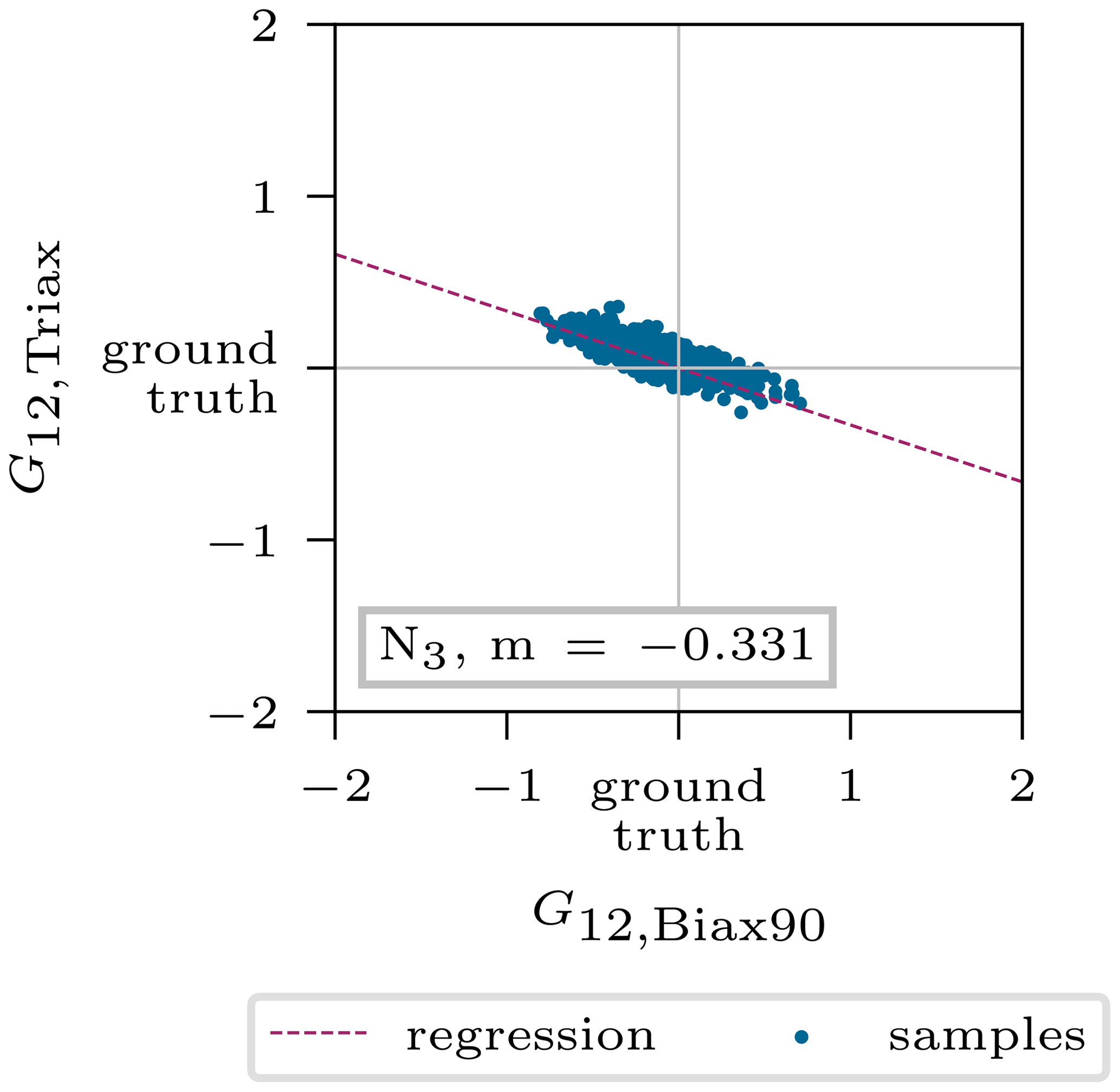
Figure 12Interaction of shear stiffness G12,Biax90 and G12,Triax describing the intrinsic model ambiguities. The depicted values correspond to the standardized mean posterior prediction for the 5000 test samples.
All ambiguities rely on the same fact that the Biax90∘ and Triax layers appear subsequently in the stacking of the sandwich panels of the blade shell. The stacking is schematically illustrated in Fig. 13 with a detailed view of the shell, showing the stacking in an exploded view. Together, these layers build the symmetric inner and outer face sheets of the shell, with a layer thickness of tBiax90=0.651 mm and tTriax=0.922 mm, the same density kg m−3 Young's modulus N mm−2, and N mm−2, and shear modulus N mm−2 and N mm−2.
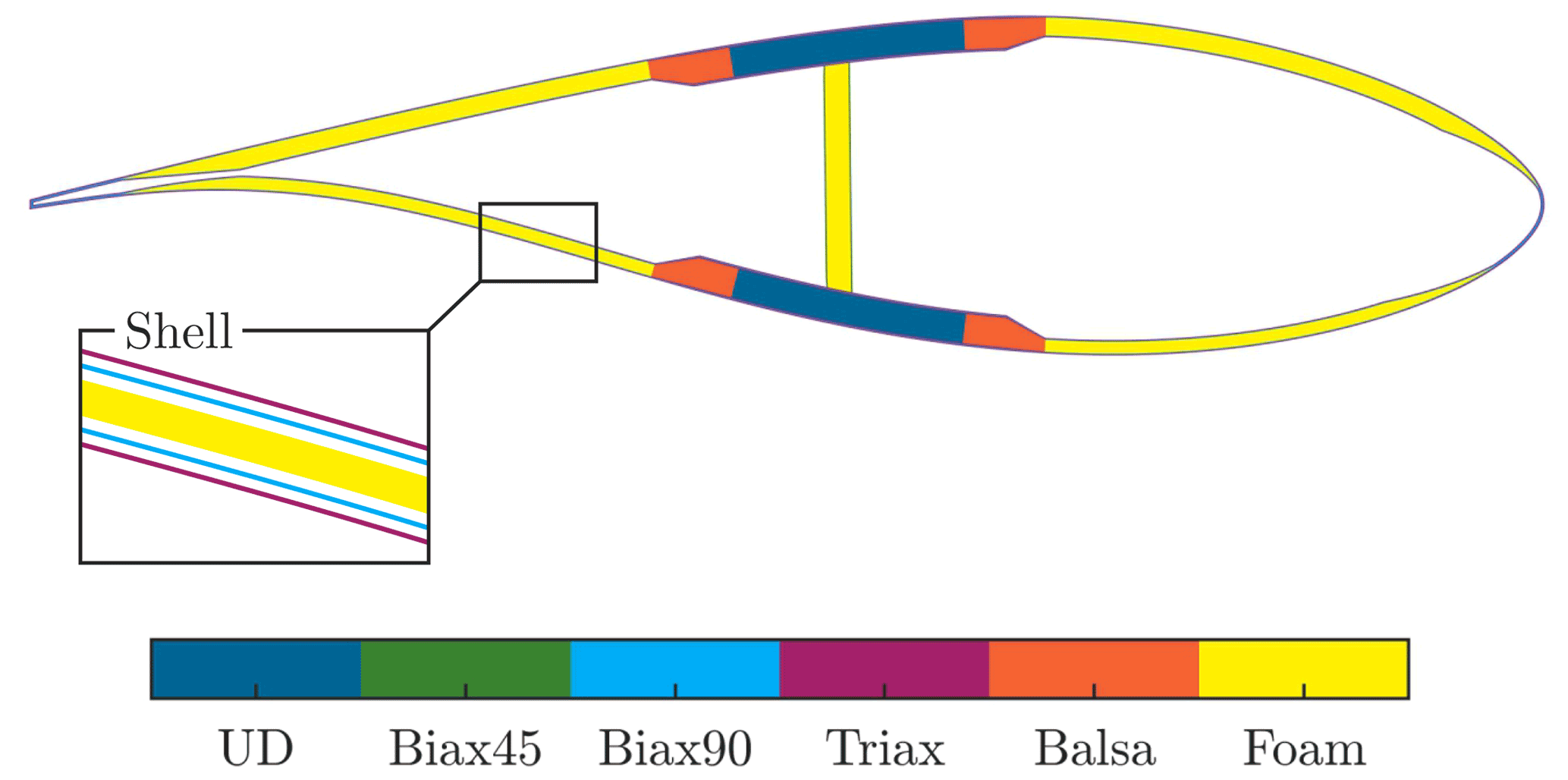
Figure 13Schematic blade cross-sectional view at a radial position of r=12 m with a detailed explosion drawing of the shell.
The contributions of the properties to the model behavior must be analyzed for it to be possible to understand these ambiguities further. As described in Sect. 2, a finite element beam model is composed of beam elements containing cross-sectional properties (Blasques and Stolpe, 2012). These basically consist of mass and stiffness terms, which can be directly linked to ρ and E11 or G12, respectively (Hodges, 2006). The upcoming deductions follow classical mechanics theories found for example in Gross et al. (2012). First, considering the mass contribution, we stick with the simplified example of the center of gravity:
where xj represents the center of gravity of each component and mi the corresponding mass. Due to the very thin thickness of both layers and the overall cross-sectional dimension being about 103 greater for both materials, it can be assumed that xj=xs. And by expecting that the cINN correctly predicts the total mass mtot, Eq. (10) yields
And this obviously leads to the summation of all individual masses to the total mass, where k represents the number of layers. This of course holds for higher-order moments of mass due to the given proximity of both layers. Thus, a ratio between both materials can be expressed:
A similar behavior is also found for the stiffness. This is explained in a simplified example for the flexural rigidity of a beam in Eq. (14), which extends with the Steiner theorem to Eq. (15).
Assuming the layers have a rectangular shape, the area moment of inertia is , though the width w of the layer is large and the thickness t is 10−3 smaller, and thus this term vanishes. With that, Eq. (15) reduces to Eq. (16). As stated before, xs can be assumed to be constant, and the same holds for the width wi as in the cross-sectional direction both material layers cover the complete circumference of the blade. This results in the proportionality in Eq. (17):
Similarly to the total mass mtot, we expect the cINN to predict the global accurately, and, consequently, we can establish the following ratio for the stiffness:
Analog derivations can be made for the shear modulus, which ends up in the following ratio:
Figure 14 shows the number of each layer for the respective material along the blade, which corresponds to both the inner and outer face sheet of the shell. The corresponding spline nodes positions are also depicted. Table 5 shows the ratios according to Eqs. (13), (18), and (19) of the different possible stacking options in Fig. 14.
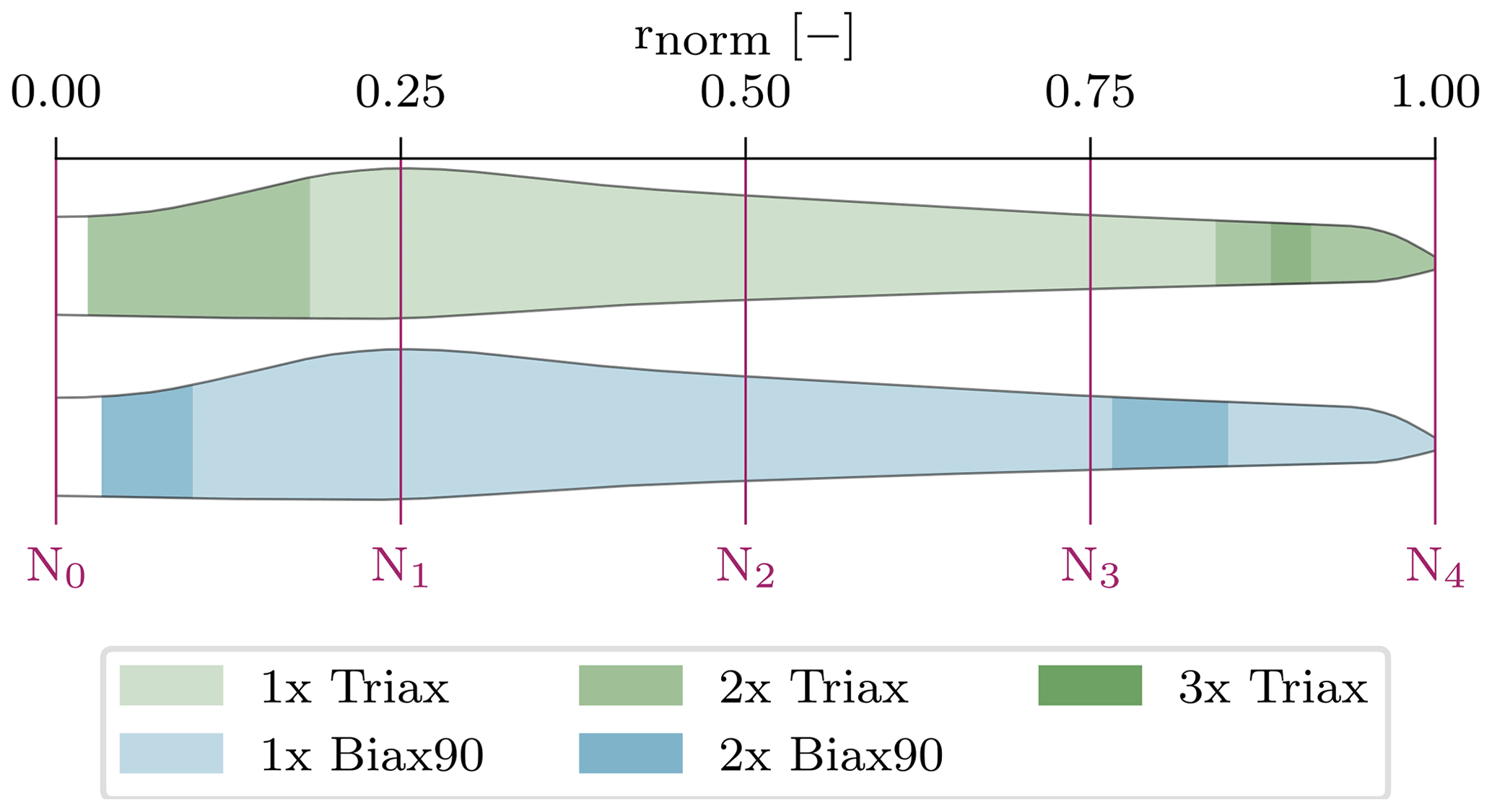
Figure 14Layup of the sandwich laminate face sheets of the blade shell, consisting of Triax and Biax90∘. The inner and outer face sheets are symmetric.
Looking back to the identified ambiguities in Fig. 10 of the density at node N4, the linear regression shows a slope of . Assuming each spline node contributes to the variance of half of the space to the left and right of it, the given slope agrees extremely well with the ratio of kBiax90=1 and kTriax=2. This corresponds to the stacking shown near the node N4 in Fig. 14. Due to the poor linear regression of node N3 in Fig. 10, the slope is not reliable; thus no conclusion can be drawn.
Table 5Ratio between Biax90∘ and Triax layers for density and stiffness contribution, considering different layer constellations.
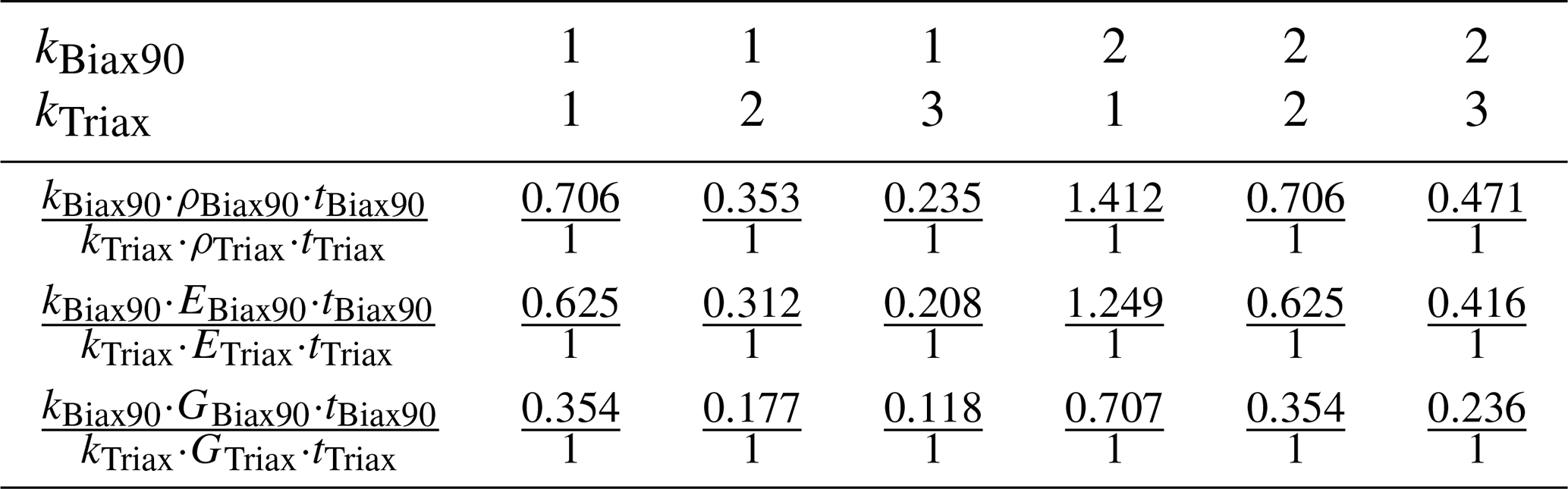
However, the counteracting Young's moduli in Fig. 11 can be very accurately captured by the ratios for most spline nodes. Starting with node N2 (Fig. 11, bottom left), which is clearly affected by only one layer to the left and right of it (see Fig. 14), the line slope matches the value in Table 5 (kBiax90=1; kTriax=1) of 0.625. Node N0 has a slope of , which agrees well with the value corresponding to kBiax90=2 and kTriax=2 but tends towards kBiax90=1 and kTriax=2, which is also in the scope of this node according to the layup in Fig. 14. Similar behavior is found for node N1. Node N3 does not fully agree with this argumentation, though the point scatters less and the regression line might not be accurate enough. The same holds for the shear modulus in Fig. 12.
As assumed in the derivation of the ratios, we can state that the cINN should correctly predict the total mass and the stiffness contributions in a global manner but suffers from an intrinsic model ambiguity affected by the counteracting densities ρ, Young's moduli E11, and shear moduli G12 of the neighboring materials Biax90∘ and Triax. However, it offers posterior predictions for these features but with a wide distribution expressing the uncertainty in the cINN based on the given ambiguity. Merging both materials to a face sheet material following laminate theory would avoid these ambiguities and improve the prediction qualities for the overall laminate. It is assumed that, based on the relatively low layer thickness, the infusion and therefore the fiber volume fraction of both layers are very similar, so this approach should be valid.
4.3 Model robustness
So far the analysis of this feasibility study was conducted on the exact test sample data; i.e., for a given input sample the corresponding exact output sample is generated with the tool chain MoCA + BECAS + ANSYS. In future studies, this presented method should be applied to real measured data of a blade, and these normally suffer from measurement uncertainties. It is thus important to analyze the model robustness with respect to a measurement error in the output features. Therefore, an error of 5 % as normally distributed random noise is applied to the clean output response of each sample, which is then used as a condition to infer the posterior prediction of the input features. The results are shown in Fig. A1 in the Appendix, comparing the noisy (orange) and the clean (blue) mean posterior predictions against their corresponding targets for all 5000 test samples. The graphs show some features that are sensitive to noise, such as and . As visually confirmed in Fig. A1, the other features do not show a wider spread (orange) than the original values (blue) and therefore do not suffer from any accuracy loss. Additionally, tests were performed resuming the training of the cINN with noisy conditions in order to improve the prediction quality, though no benefit was identified.
4.4 Resimulation analysis
A resimulation analysis aims to utilize the posterior predictions of the cINN based on the original response to resimulate/recalculate the response with the physical model in order to compare it to the original response used to perform the prediction. For all samples, the correct input features and their corresponding response features are known, which we will be referring to as targets. The target response is used as a condition for the cINN to infer the posterior prediction of the selected input features. From these inferred input features we can create new input splines for each input, as depicted exemplarily in Fig. 15. However, the prediction is not a discrete value but a Gaussian distribution as we have seen before in Sect. 4.1. Additionally, there are nodes that the sensitivity analysis excluded from the updating process; these may take every value within their variation range as they were sampled uniformly. Hence, for each input feature we obtain a range of possible splines as Fig. 15 illustrates. Here, the orange spline represents the target variance of the input parameter and the dark blue area represents the expected value, i.e., the mean prediction from the updated nodes. In the case of the first spline for ρUD, nodes N0 and N4 were excluded from the updating process and can thus take any value in the range of ±10 % as we do not have any prediction for them. As such the blue area covers all possible splines a user would take as the result from the model updating process. However, the purpose of this first evaluation of the resimulation analysis is to examine if sampling splines from the given distributions will all lead to appropriate results. Therefore, the 1σ uncertainty displayed in light blue shows the standard deviation of the predicted nodes. In this first analysis, we sample from a uniform distribution for the non-updated nodes (dark blue range) and from a normal distribution for the updated nodes (light blue) to create a spline. This will be done 1000 times for the same given target response of the selected single test sample. Subsequently, these 1000 sets of input splines are then used to create the model and calculate its modal response. For the sake of completeness, Table A2 gathers the identified mode shapes of both configurations. The resultant mode shapes of the free–free and the clamped configurations are then compared to the target response with the help of the modal assurance criterion (MAC) (Allemang, 2003).
The MAC is the scalar product of two normalized vectors, each representing all the model's degrees of freedom of a particular mode shape. It is basically an orthogonality check: equal mode shapes reach a value of MAC=1, and a value of MAC>0.8 is already assumed to show good coherence (Pastor et al., 2012). For a multiple number of modes, a MAC matrix summarizes all MAC values of all mode shapes compared against each other.
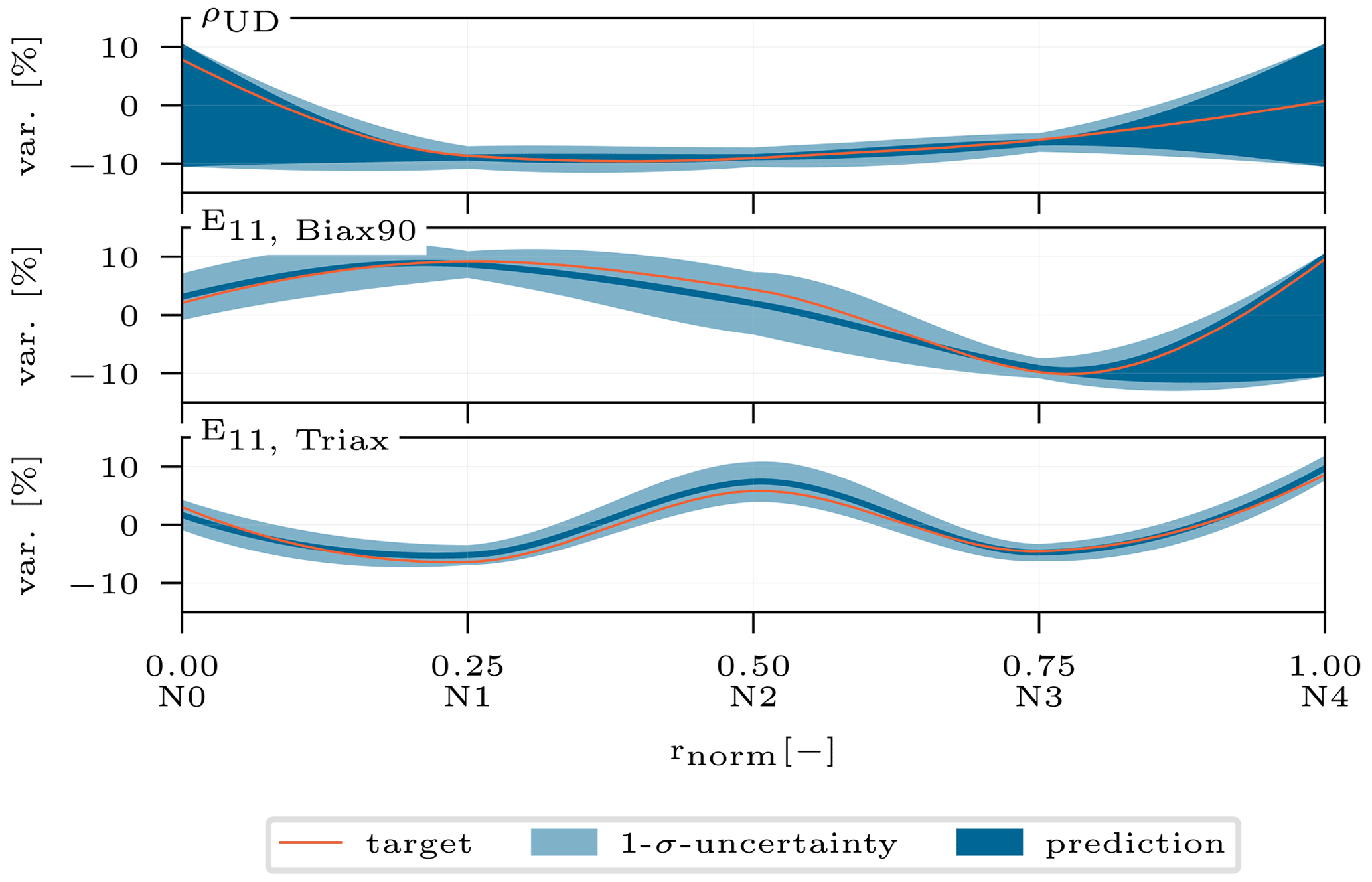
Figure 15Exemplary inferred spline prediction range for ρUD, E11,Biax90, and E11,Triax. The graphs depict the target spline in orange, the mean prediction in dark blue, and the 1σ uncertainty in light blue, for the updated spline nodes.
In our use case, the MAC matrix is computed individually for all responses of the previously generated 1000 samples against the target response. For the free–free configuration, Fig. 16 illustrates the mean value of the MAC matrix over all samples in the top graph. The corresponding standard deviation is depicted below. The main diagonal ideally takes values of MACij=1, as the same mode shape of the sample and the target is compared. Additionally, the matrix should be symmetric, as the comparison of MACij=MACji represents the same two mode shapes. Figure 16 confirms this ideal symmetric matrix structure for the resimulated samples, with mean values in the diagonal and extremely low standard deviations of σMAC<0.003. For the clamped configuration, the values on the diagonal are also strikingly close to 1 (; σMAC<0.005) and the overall matrix appears symmetric. In this way, sampling from the distribution predicted by the cINN for each selected input feature and arbitrarily choosing a value for the non-updated values yield an exact coherence of target and computed mode shapes.
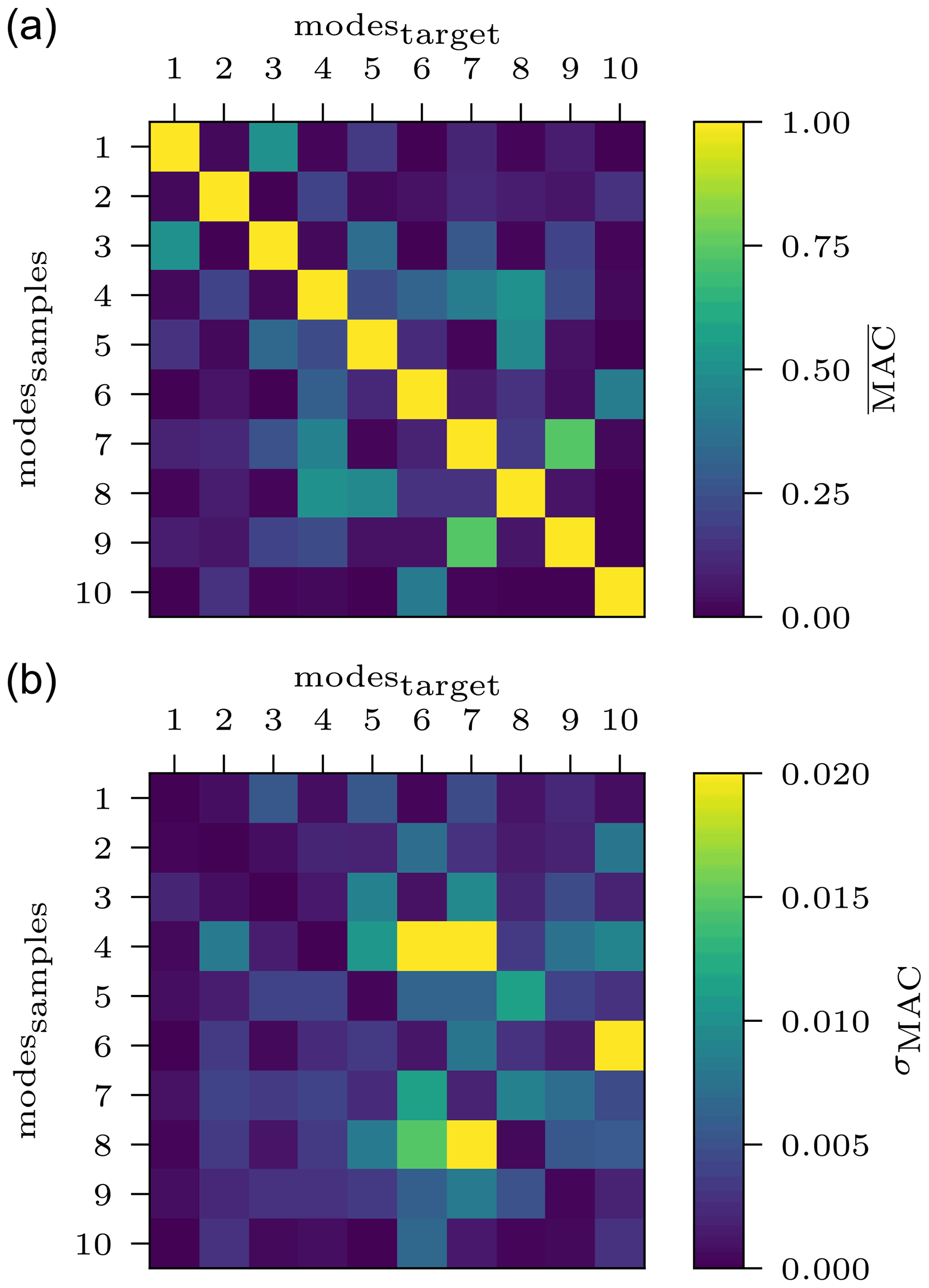
Figure 16Mean values (a) and standard deviations (b) of the MAC matrix for the free–free modal configuration based on 1000 spline samples inferred for one target response.
After having analyzed a single target sample, the resimulation is expanded to more samples to show the cINN's general performance. Therefore, posterior predictions for the 5000 test samples of the test set are inferred with the cINN. Contrary to the resimulation case before, only one input is generated for each of the samples by choosing the mean value of the prediction and, in the case of excluded variables, a node value of zero (i.e., no variation). That represents a typical choice a user would make, based on predicted posterior distributions. Figure 17 depicts the mean (horizontal marker) and max and min values (bar) of the diagonal entries of the MAC matrices, which are computed for all samples and both configurations, to compare the resimulated model and its respective target response. Again, all mean values are close to 1 (90 % with a ), so an overall excellent updating performance can be stated. Single predictions lead to worse results, as depicted by the minimum value (4.3 % of all have a MAC≤0.98), especially for the higher-order modes, though the MAC value of less than 0.8 is only obtained for the 10th eigenmode of the free–free configuration.
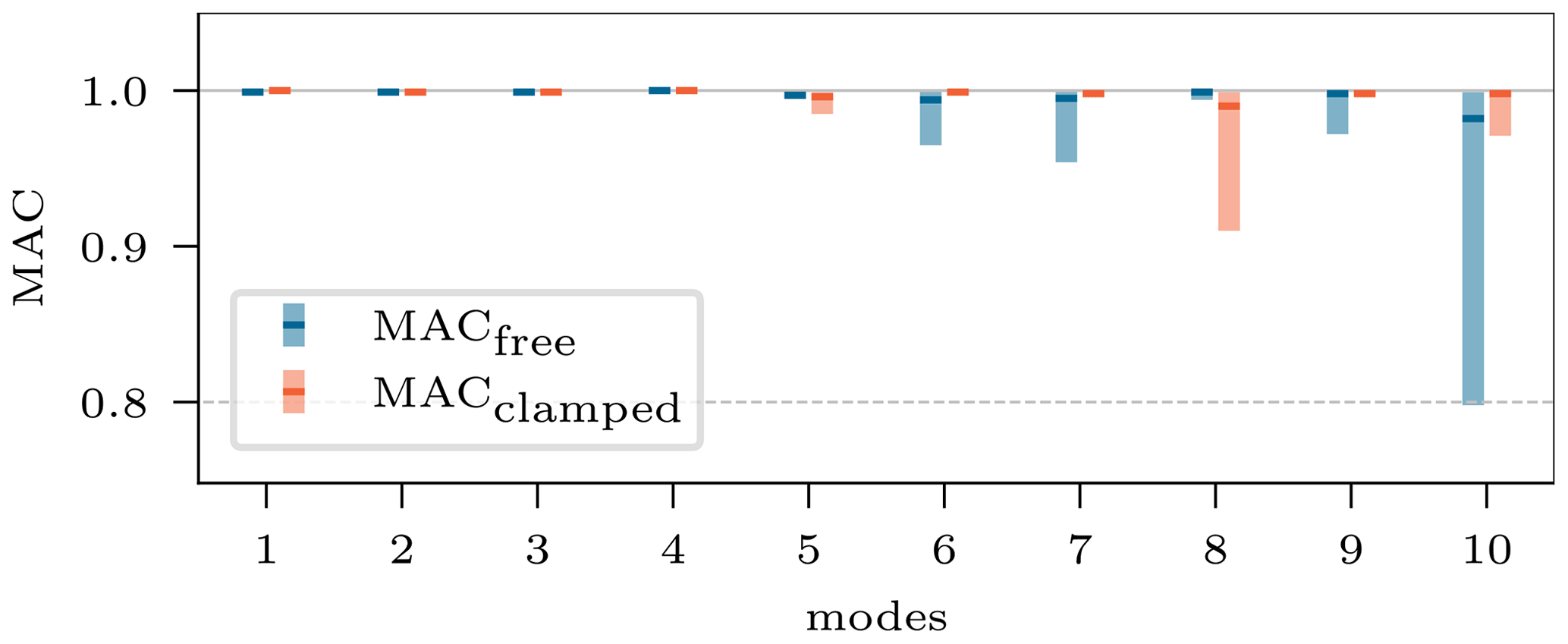
Figure 17Mean, maximum, and minimum diagonal entries of the MAC matrices computed for 1000 target responses.
The generally good performance is also confirmed by the predicted corresponding natural frequencies. Figure 18 shows the relative error from the resimulated frequencies to the target frequencies of each mode for both configurations, giving the mean and standard deviation over all resimulated samples. The range of the mean error is % and the standard deviation %.
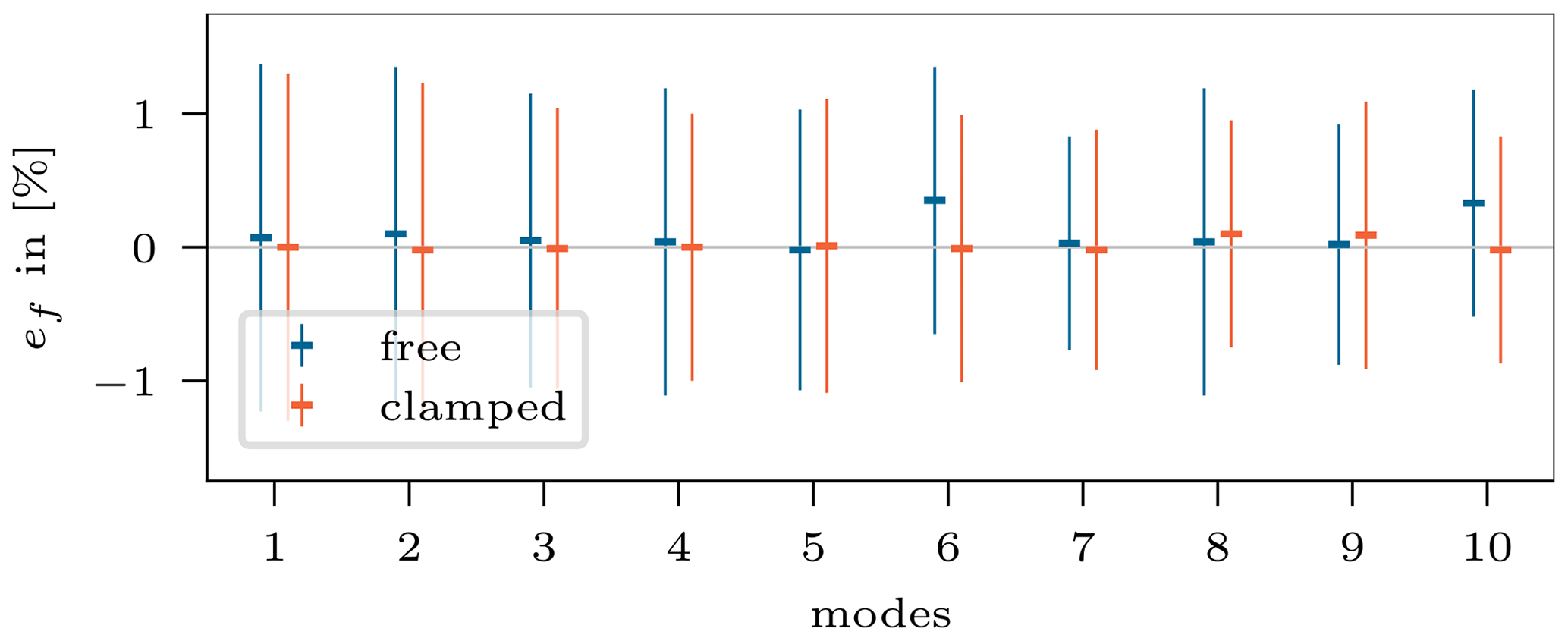
Figure 18Mean and standard deviation of the natural frequency error ef computed for 1000 target responses.
The results of the presented resimulation analysis show the following:
-
The counteracting intrinsic model ambiguities discussed in Sect. 4.2 cancel each other out; i.e., the overall shell laminate properties are correctly predicted, although the individual stiffness or density of the layers (Biax90 and Triax) is not predicted accurately. So the cINN still correctly captures the global model behavior with respect to mass and stiffness distribution.
-
As expected, the insensitive and thereby excluded input parameters really do not have an impact on the results and can be chosen arbitrarily (see Fig. 15).
-
The overall cINN updating performance is strikingly good, with on average 90 % of the mode shapes of the resimulated samples showing a . The frequencies were recovered with a mean error of %.
4.5 Replacing sensitivity analysis
Similarly to other model updating studies such as Luczak et al. (2014), this work relies on a sensitivity study to reduce the parameter space of the updating problem to significant parameters. This so-called feature selection is performed in this particular investigation with the aforementioned Sobol' method. A quasi-random sampling with low-discrepancy sequences (Dick and Pillichshammer, 2010) is applied to compute the Sobol' indices, which is a computationally efficient and space-efficient sampling method for the sensitivity analysis. However, the sampling set to train the cINN in general has to span a real random sampling space, where all features are varied independently but simultaneously. That means, despite the 79 360 samples for the sensitivity analysis, an additional set of 30 000 samples has to be generated for training purposes and a second variably sized set for validation and testing of the cINN. In total, this results in approximately 115 000 samples and thus model evaluations. This is crucial considering that the model evaluation in general is the computational bottleneck. Although a classical optimization algorithm would also need a feature selection to reduce the updating problem complexity on top of its usual model evaluation number for the optimization process, the overhead of the sensitivity cuts down the computational benefit of the cINN. A single model evaluation from creating the input parameter set to importing the modal response of the model took on average approx. 80 s on a single-core device. We generated the 115 000 samples on a 40-core computing cluster in slightly less than 2.66 d. In contrast, the cINN training for 150 epochs took only 0.67 h on an NVIDIA Tesla P100 GPU.
To reduce the computational sampling time, the idea is to apply the cINN to the full input parameter set x to identify relevant parameters. The cINN implicitly detects irrelevant features by predicting an uncertain posterior distribution, i.e., high standard deviation, due to missing information for the inference in the response. However, Sect. 4 and 4.2 showed that intrinsic model ambiguities lead to wider distributions, without being inaccurate in the global model behavior. This means the respective input parameters should not be rejected due only to a widely distributed posterior prediction. Therefore, we combine three metrics to perform the feature selection on the posterior predictions of the full input parameter set with respect to standardized values:
-
root mean square error (RMSE) of the predicted posterior's mean and target value,
-
standard deviation of the predicted posterior distribution,
-
cross-correlation matrix of the predicted posterior's mean values.
The RMSE should reject features that might have a narrow predicted posterior distribution but do not match the target value. This is more a security or backup metric. The standard deviation is a metric for the confidence of the cINN and should reject features that are not significantly included in the information of the modal beam response. And finally, a cross-correlation matrix should reveal intrinsic model ambiguities from feature interactions, in order to keep the respective features, though the other two metrics would reject them. The cross-correlation matrix of this inverse problem is depicted in Fig. 19. The inputs feat40−54 and feat60−74 in the matrix correspond to , , and and to , , and , respectively, which show the high negative correlation of the interacting features discussed in Sect. 4.2. This matrix also helps to detect other relevant correlations. Especially nearby nodes of the same feature (e.g., feat85−87, ) can counteract each other, as these have to predict in combination the spline behavior in between them; i.e., if one increases, the other has to diminish. Similar behavior was already detected in Bruns et al. (2019).
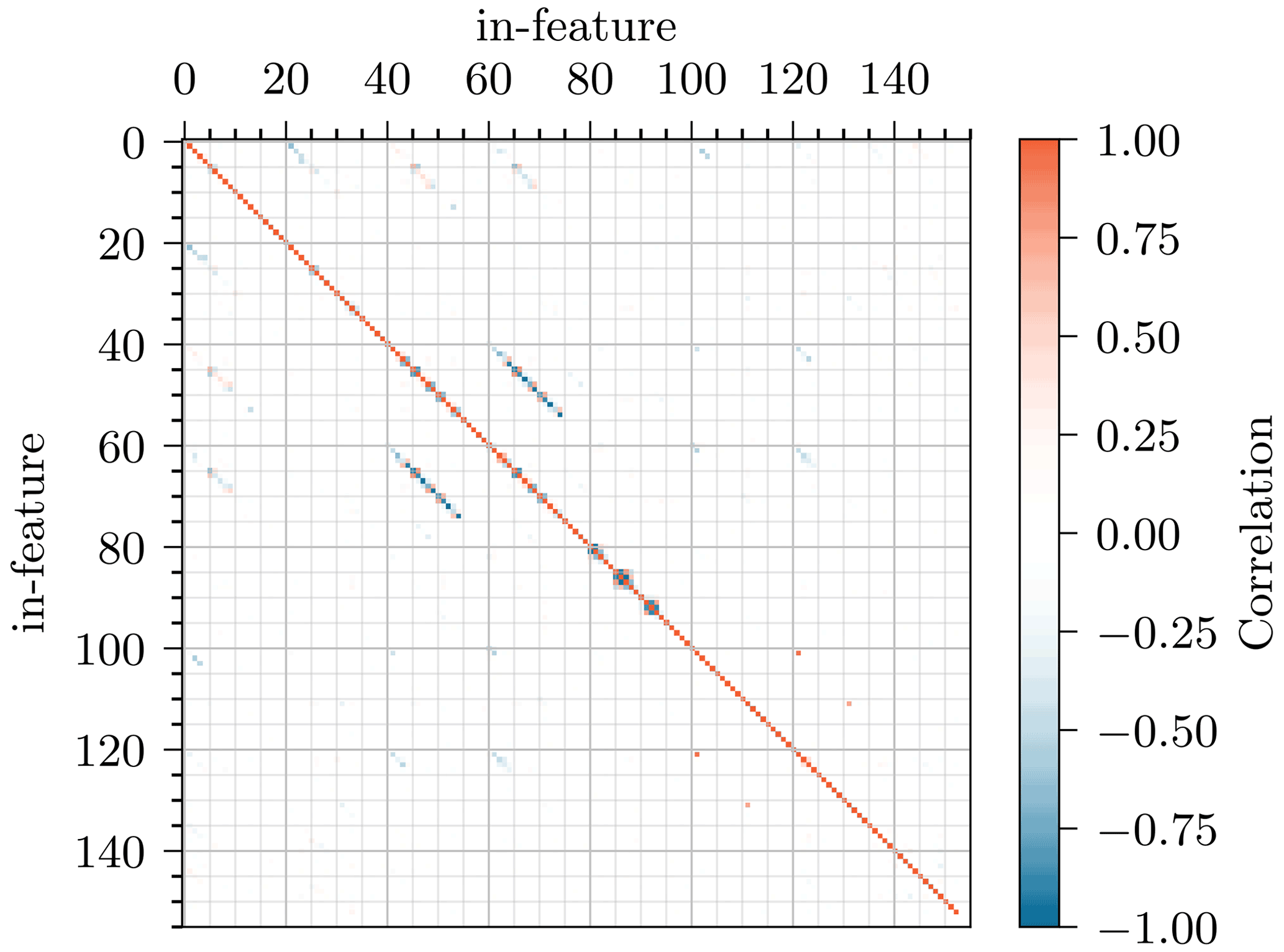
Figure 19Cross-correlation of all input features based on mean posterior prediction of the 5000 test samples.
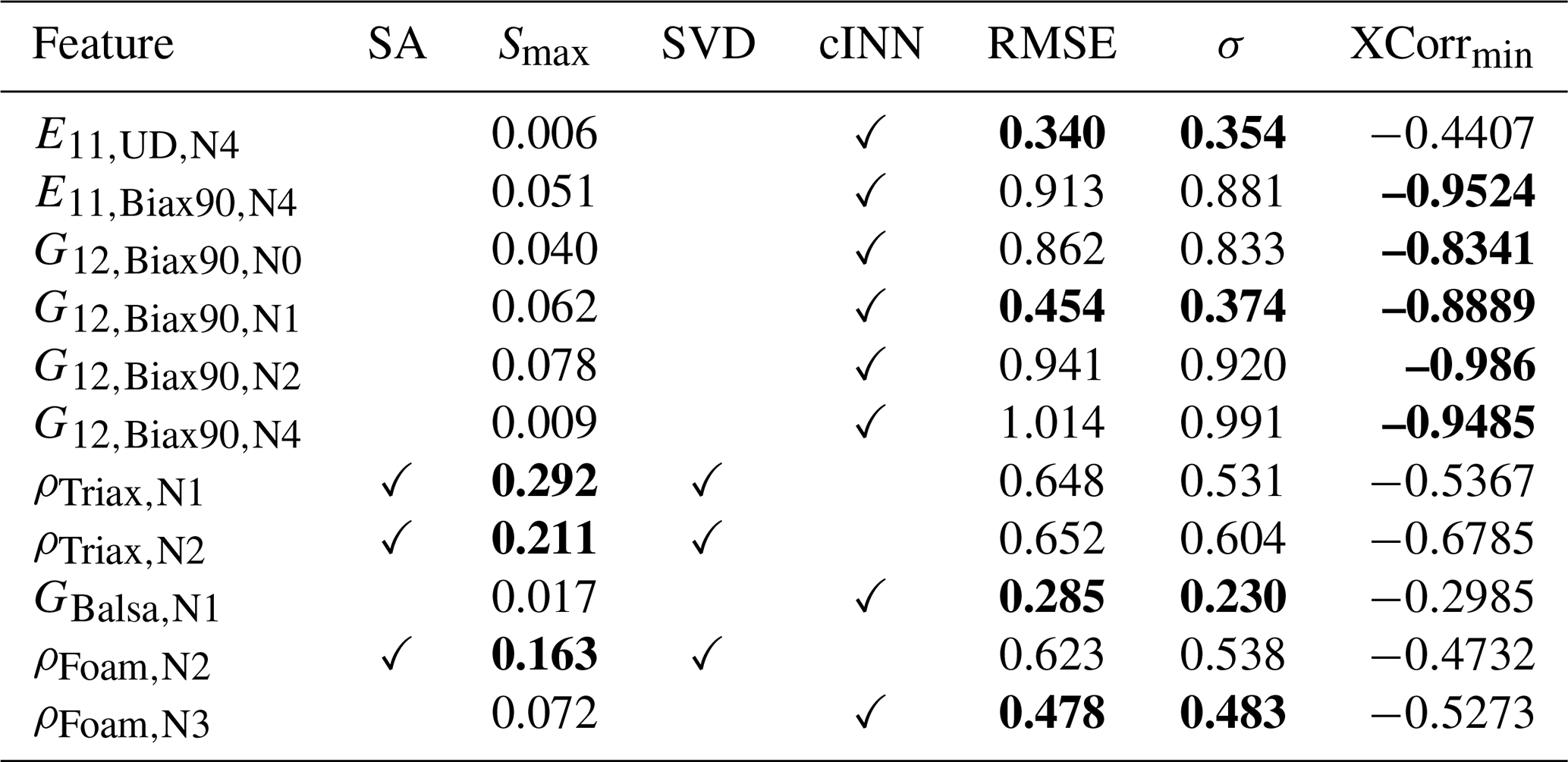
Similarly to the Sobol' threshold , thresholds for the given metrics can be chosen arbitrarily again and rely on experience. In this case we have chosen RMSEthld=0.5, σthld=0.5, and XCorr. Table A1 lists all features selected by the sensitivity analysis and the cINN in comparison. The sensitivity analysis selects 49 features, while the cINN includes 54 features. Most of the features agree for both selection methods, except those included in Table 6. The cINN, for example, includes the input features and , which can be very well predicted by the cINN but which are not detected by the sensitivity analysis to be significant for the response variations. Additionally, it detects a few highly negative correlating features – and – which follow the similarly ambiguous behavior shown in Sect. 4.2, counteracting the respective Triax properties. However, the features and , detected by the sensitivity analysis, were excluded by the cINN, though at least the first two show a significant Smax>0.200.
Table 6Feature selection discrepancies between both methods – sensitivity analysis (SA) and the cINN-based approach – and their corresponding metrics. All values depicted in bold meet their corresponding threshold and are thus selected by the respective approach.
Finally, this procedure is based on 30 000 samples and the same cINN architecture and hyperparameters. Figure A2 shows the correlation results for all features included in the sensitivity analysis, where the orange scatter represents the prediction with the model trained on the full input set and the blue scatter the prediction by the former model based on the feature selection from the sensitivity analysis. Only very few features show a significant loss in accuracy compared to the original model and most likely for the feature with a worse prediction quality. Thus, there is no need to perform a second training process with a reduced data set for the sensitivity-free procedure, though the selection of the samples should still reveal the significant parameters of the model. Relying on the same computing resources mentioned above, the overall process in this particular case adds up to a complete computation time of approximately 20 h, which corresponds to a reduction of 69 %. It also reveals that the cINN can handle a higher number of parameters while extracting the relevant information from the response to predict the significant input features. On account of that, there is no need for a pre-analyzing sensitivity study in future investigations. This gives cINNs a huge advantage over common approaches as discussed in the Introduction. They rely on a sensitivity analysis to identify a significant subspace to reduce the problem dimension. With 30 000 model evaluations for a total of 49 updated features, the cINN is quite efficient. A stochastic updating approach demanded 1200–12 000 evaluations for a simple three-feature updating problem (Augustyn et al., 2020; Marwala et al., 2016). Higher dimensional problems could explode in computational costs for common deterministic approaches, relying even more on an additional preprocessed subspace selection (here, 79 000 model evaluations). However, to the best of the authors knowledge, no model updating was found in the literature for such a high parameter space as presented in this work.
The current study aims to extend the feasibility study of model updating with invertible neural networks presented in Noever-Castelos et al. (2021) to a more complex and application-oriented level in the form of a Timoshenko beam. The model updating was performed on a global level. This took into account five-noded splines for input feature representation over the blade span of material density and stiffness, as well as layup geometry. The blade response used for the updating process is in the form of modal shapes and frequencies. The outstanding updating results presented in this study strengthen the conclusion in Noever-Castelos et al. (2021) that invertible neural networks are highly capable of efficiently dealing with wind turbine blade model updating for the given global fidelity level.
In comparison with Noever-Castelos et al. (2021), this investigation increased the model complexity from a single cross-sectional representation to a finite element Timoshenko beam model of the complete blade. The update parameter space was only slightly expanded for the materials to cover the most relevant, independent elastic properties of orthotropic materials. These, however, are varied over the complete blade length with three- to five-noded splines. Moreover, an established, global, variance-based sensitivity analysis with the Sobol' method was performed to determine the relevant update parameters. A total of 49 input parameters were updated based on modal responses of the blade in a free–free boundary configuration and a root-clamped configuration. The applied cINN approximately doubled its depth, and an additional feed-forward network was implemented to preprocess the conditions of the cINN in order to improve the network's flexibility and accuracy.
The result analysis of the predicted parameters shows strikingly high coherence with the target values with R2 scores over 0.9 for 75 % of the updated parameters. The very high updating certainty of the network is reflected in the narrow predicted posterior distributions of the updated parameters. Moreover, this study revealed more intrinsic model ambiguities of material properties (E11, G12, ρ) of the laminate face sheets Biax90∘ and Triax due to their proximity in the layup. The cINN learns and understands the intrinsic collinearities of the physical model, which result in ambiguous inverse paths. However, the cINN is still not able to distinguish from which parameter the individual contribution comes. Nevertheless, in contrast to a deterministic approach, the user can see how uncertain the cINN is about the prediction due to its wide spreading of affected features' prediction. In future contributions this can be handled by updating a joint density or stiffness variation, instead of individual features. However, the resimulation analysis revealed the modal response of the updated models matches the target results exceptionally well: 90 % of the mode shapes of the resimulated samples show a and a mean error in the natural frequencies of over 1000 randomly chosen test samples. Finally, this study presents a method for avoiding the computationally expensive sensitivity analysis by fully exploiting the opportunities of the cINN. For this reason, the full parameter set of Dtot=153 was used for the update process. Thanks to the underlying probabilistic approach of the cINN, a similar set of significant input features was detected from the complete parameter space, based on the predicted posterior distributions and a cross-correlation between the input feature to identify the ambiguities. Thus, the necessary sample number for the complete process was reduced to 30 000 samples and the computational time by 69 % while maintaining similar outstanding updating results.
Referring back to the three major problems of the approaches studied in the Introduction, the cINN tackles these in the following ways:
-
It has a high computational efficiency in relation to the model complexity, i.e., updating parameter space, and even more by evading computationally expensive sensitivity analysis. The cINN only demanded 30 000 model evaluations (≈20 h) for a total of 49 updated features within an original space of 153 features.
-
It makes an inherent probabilistic evaluation, as it follows Bayes' theorem and is trained to minimize the negative log likelihood of the mapping between posterior distribution and latent distribution.
-
A surrogate of the inverted model is represented. By that, the cINN can be evaluated for any given response (in the model boundaries) at practically no additional cost after training. Any other approach is solved only for one particular model response and has to be repeated in the case of a different set of responses.
In conclusion, the feasibility study was highly successfully extended to a full-blade beam model, though with a still limited parameter set. The cINN proved to be extremely capable of performing efficient model updating with a larger parameter space. The physical model complexity in the form of a Timoshenko finite element beam is already at the state-of-the-art level applied in industry. However, to ensure that the cINN learns the complete inverted physical model, it is important that all possibly relevant parameters have to be varied so that the cINN is trained for all circumstances of variations for the model updating. Therefore, ongoing and future investigations should bring this method to a real life application, where the parameter space will span more relevant aspects of blade manufacturing deviations, such as adhesive joints. Moreover, the combined laminate properties of the face sheets might be able to prevent the model ambiguities and even improve the already good prediction accuracy. One possible application scenario could be a final quality control after manufacturing if the response generation can be automated. The benefit would be to find rough manufacturing deviations and even provide individually updated models for each blade, which could for example enhance turbine controls.
Table A1Comparison of the feature selection performed by the sensitivity analysis (SA) and directly with the cINN applied to the full input parameter set.
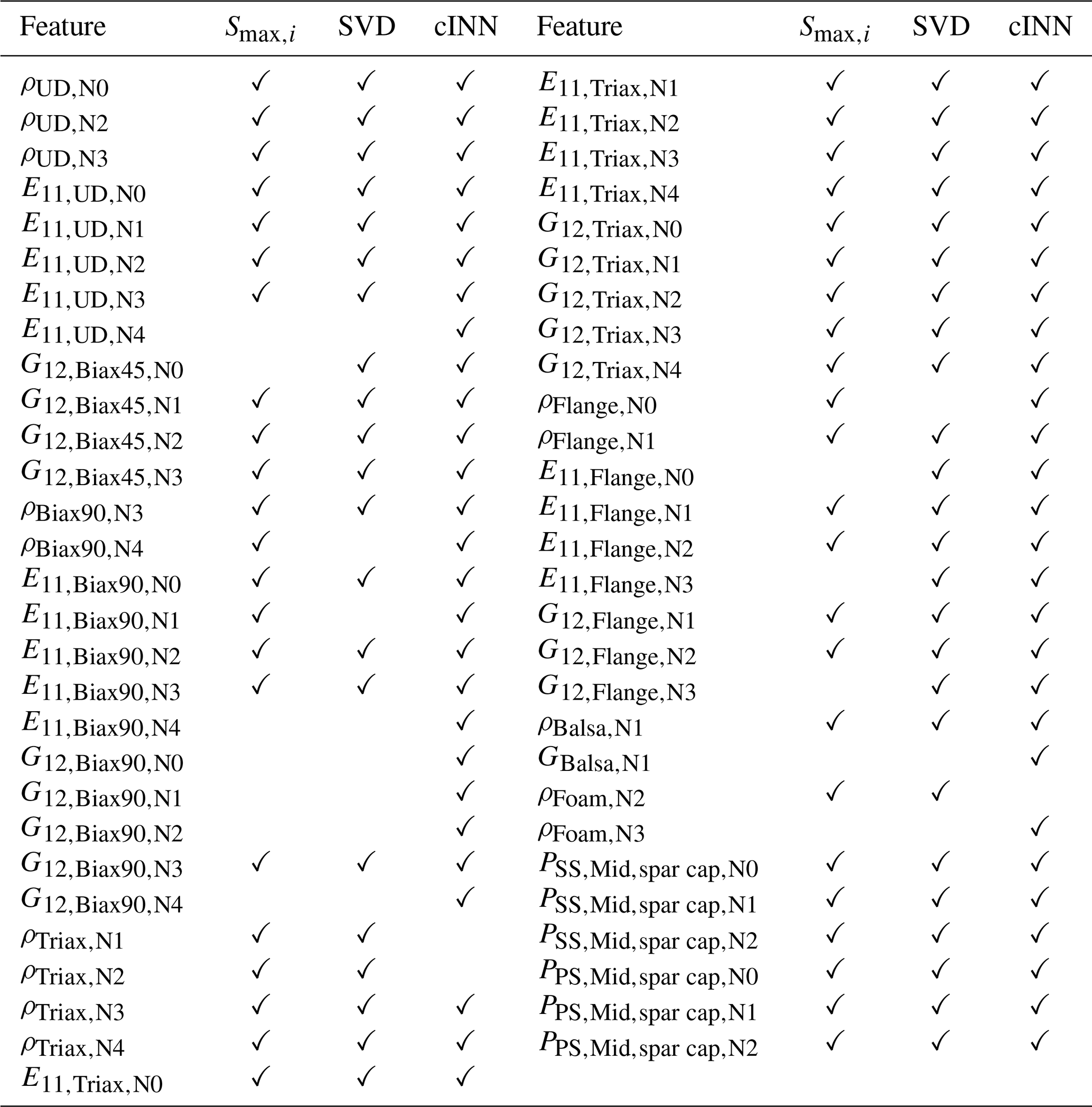
Table A2Identified mode shapes of the first 10 modes (excluding rigid body motion) of the free–free and the clamped modal configuration.
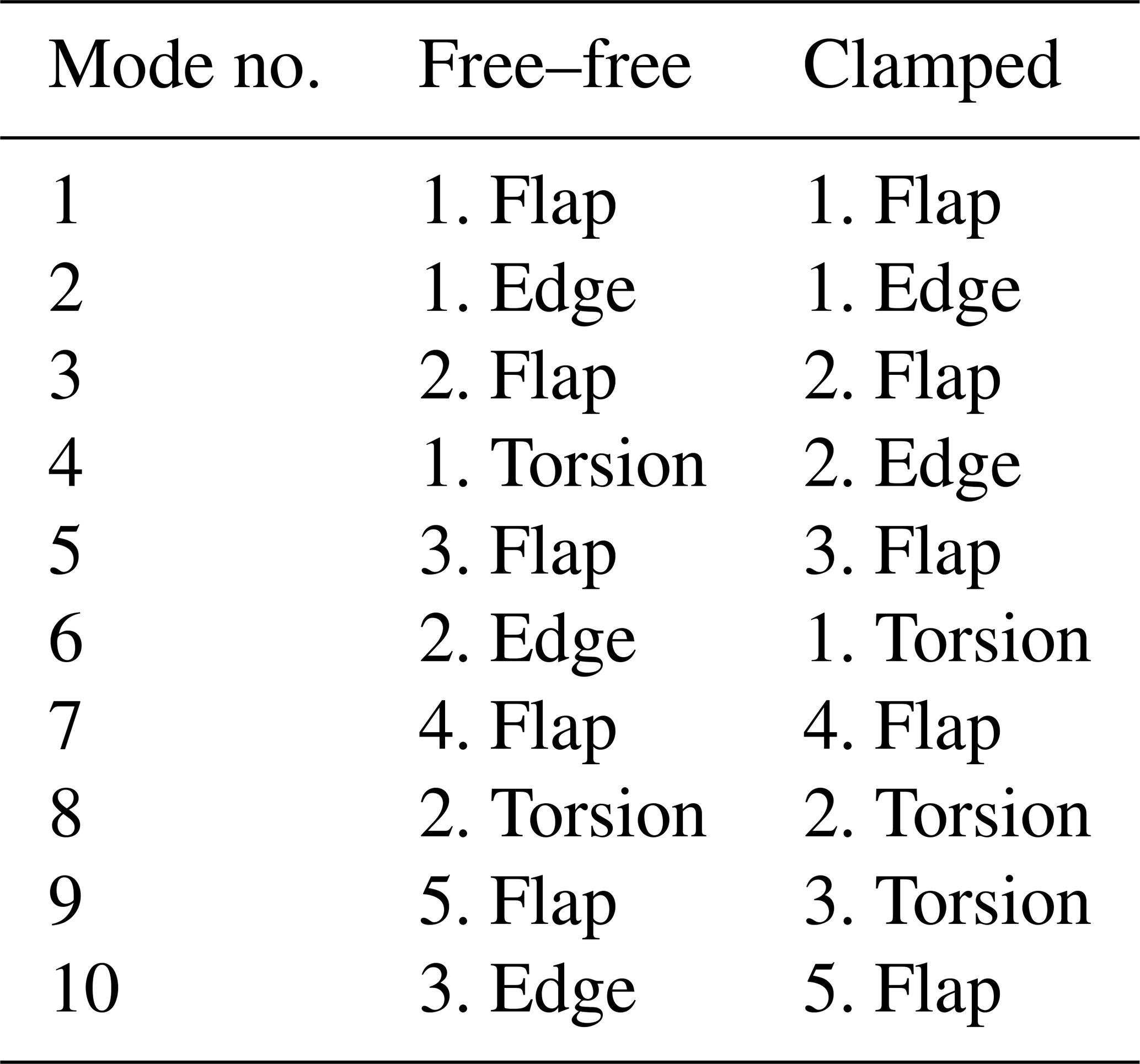
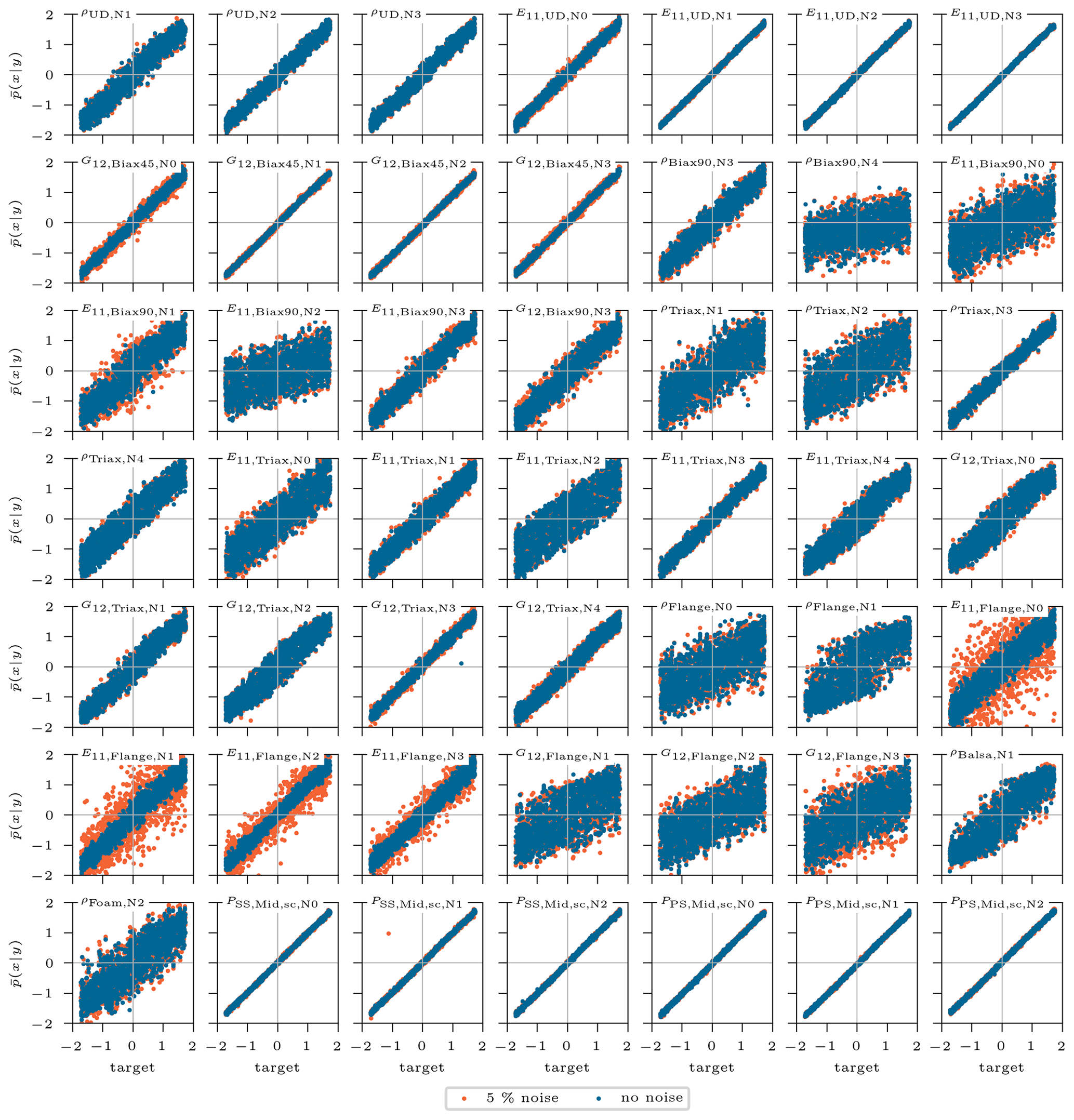
Figure A1Standardized mean of posterior prediction of the updated inputs over the corresponding target standardized value for the 5000 test samples. The original samples predicted with clean conditions are in blue, compared to samples with noisy flawed conditions (5 % random noise) in orange. The noisy conditions are intended to simulate measurement inaccuracies of the modal beam response.
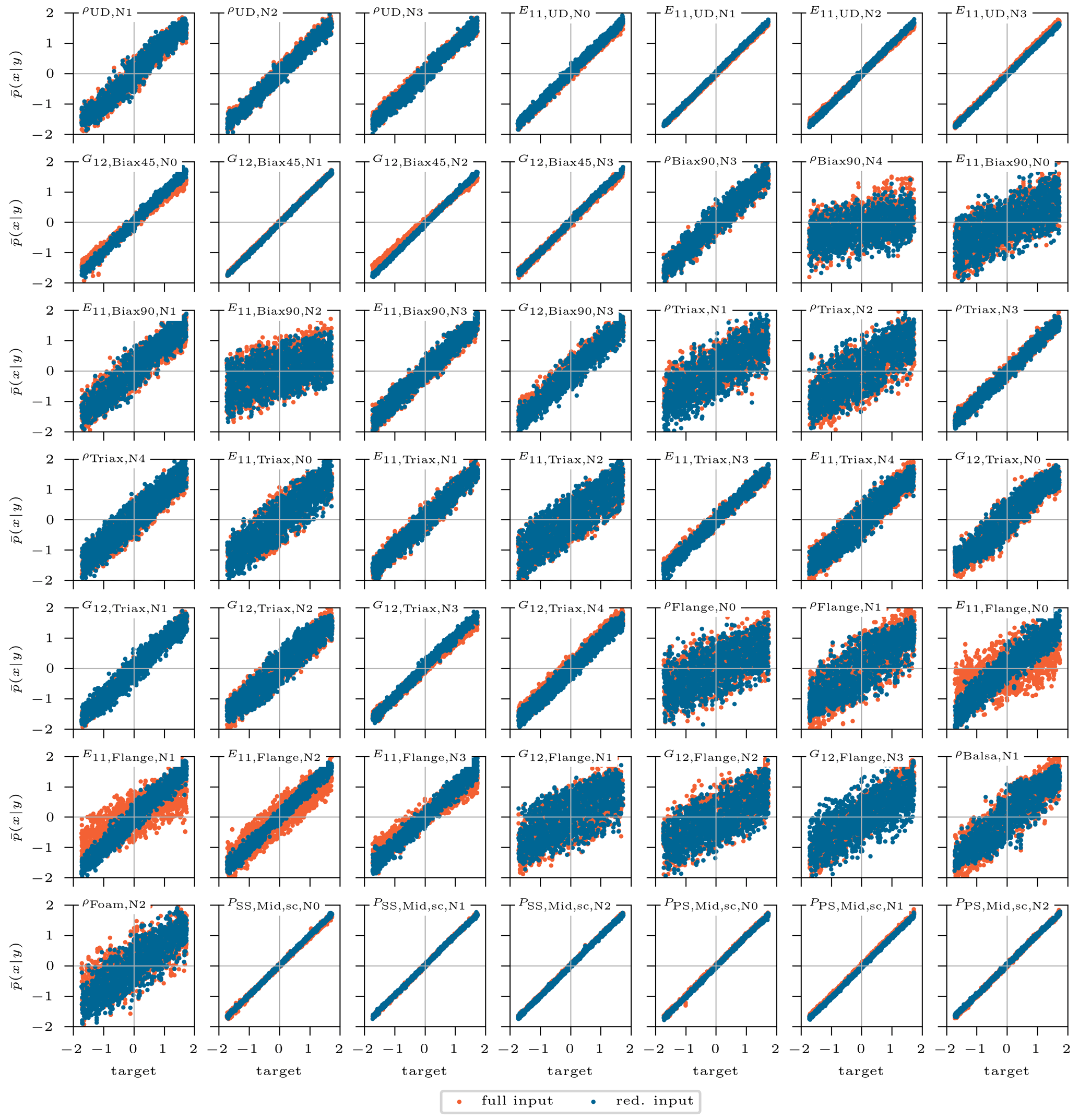
Figure A2Standardized mean of posterior prediction of the inputs selected by the sensitivity analysis, over the corresponding target standardized values for the 5000 test samples. The original samples predicted with the reduced input set according to the sensitivity analysis selection are depicted in blue. They are compared with the inputs predicted by the cINN trained on the full input set (in orange).
Code is available in a publicly accessible repository: https://doi.org/10.5281/zenodo.6351906 (Noever-Castelos, 2022a). Data are available at https://doi.org/10.25835/0042221 (Noever-Castelos, 2022b).
PNC prepared the concept and methodology, conducted the analysis, wrote the paper, and processed the review. DM supported PNC in transferring the BECAS beam information to ANSYS and in conducting the FE-analysis. CB is the supervisor and guided PNC in the conception of the paper.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The information in this paper is provided as is, and no guarantee or warranty is given that the information is fit for any particular purpose. The user thereof uses the information at their own risk and liability.
This work was supported by the Federal Ministry for Economic Affairs and Climate Action of Germany (BMWK) in the project ReliaBlade (grant number 0324335A/B).
This work was supported by the compute cluster, which is funded by the Leibniz University Hannover, the Lower Saxony Ministry of Science and Culture (MWK), and the German Research Association (DFG).
The publication of this article was funded by the open-access fund of Leibniz Universität Hannover.
This paper was edited by Carlo L. Bottasso and reviewed by Sarah Barber and Stefano Cacciola.
Akima, H.: A New Method of Interpolation and Smooth Curve Fitting Based on Local Procedures, J. ACM, 17, 589–602, https://doi.org/10.1145/321607.321609, 1970. a
Allemang, R. J.: The modal assurance criterion – twenty years of use and abuse, Sound Vibrat., 37, 14–23, 2003. a, b
ANSYS Inc.: Ansys® Academic Research Mechanical, Release 2021 R2, Help System, ANSYS Mechanical APDL Element Reference, https://www.ansys.com/academic/terms-and-conditions (last access: 14 March 2022), 2021a. a, b
Ardizzone, L., Mackowiak, R., Rother, C., and Köthe, U.: Training Normalizing Flows with the Information Bottleneck for Competitive Generative Classification, in: 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), vol. 33, 7828–7840, https://researchr.org/publication/nips-2020 (last access: 14 March 2022), 2018. a
Ardizzone, L., Kruse, J., Wirkert, S., Rahner, D., Pellegrini, E. W., Klessen, R. S., Maier-Hein, L., Rother, C., and Köthe, U.: Analyzing Inverse Problems with Invertible Neural Networks, in: Seventh International Conference on Learning Representations, https://doi.org/10.48550/arXiv.1808.04730, 2019a. a, b
Ardizzone, L., Lüth, C., Kruse, J., Rother, C., and Köthe, U.: Guided Image Generation with Conditional Invertible Neural Networks, https://doi.org/10.48550/arXiv.1907.02392, 2019b. a, b, c, d, e, f
Augustyn, D., Smolka, U., Tygesen, U. T., Ulriksen, M. D., and Sørensen, J. D.: Data-driven model updating of an offshore wind jacket substructure, Appl. Ocean Res., 104, 102366, https://doi.org/10.1016/j.apor.2020.102366, 2020. a, b
Blasques, J. P. and Stolpe, M.: Multi-material topology optimization of laminated composite beam cross sections, Compos. Struct., 94, 3278–3289, https://doi.org/10.1016/j.compstruct.2012.05.002, 2012. a, b, c, d
Bruns, M., Hofmeister, B., Grießmann, T., and Rolfes, R.: Comparative Study of Parameterizations for Damage Localization with Finite Element Model Updating, in: Proceedings of the 29th European Safety and Reliability Conference (ESREL), edited by: Beer, M. and Zio, E., 1125–1132, Research Publishing Services, Singapore, https://doi.org/10.3850/978-981-11-2724-3_0713-cd, 2019. a, b, c
Chakroborty, S. and Saha, G.: Feature selection using singular value decomposition and QR factorization with column pivoting for text-independent speaker identification, Speech Commun., 52, 693–709, https://doi.org/10.1016/j.specom.2010.04.002, 2010. a, b, c, d
Chollet, F.: Deep learning with Python, Safari Tech Books Online, Manning, Shelter Island, NY, ISBN 9781617294433, 2018. a, b
Chopard, B. and Tomassini, M. (Eds.): An Introduction to Metaheuristics for Optimization, Natural Computing Series, Springer International Publishing, Cham, https://doi.org/10.1007/978-3-319-93073-2, 2018. a
Dick, J. and Pillichshammer, F.: Digital nets and sequences: Discrepancy theory and quasi-Monte Carlo integration, Cambridge Univ. Press, Cambrigde, ISBN 9780511761188, 2010. a
Duchi, J., Hazan, E., and Singer, Y.: Adaptive Subgradient Methods for Online Learning and Stochastic Optimization, J. Mach. Learn. Res., 12, 2121–2159, 2011. a
Golub, G. H. and van Loan, C. F.: Matrix computations, Johns Hopkins studies in the mathematical sciences, 4th Edn., The Johns Hopkins University Press, Baltimore, ISBN 1421407949, 2013. a, b
Grieves, M. W.: Virtually Intelligent Product Systems: Digital and Physical Twins, in: Complex Systems Engineering: Theory and Practice, vol. 411, edited by: Flumerfelt, S., Schwartz, K. G., Mavris, D., and Briceno, S., American Institute of Aeronautics and Astronautics, Inc, Reston, VA, 175–200, https://doi.org/10.2514/5.9781624105654.0175.0200, 2019. a
Gross, D., Hauger, W., Schröder, J., and Wall, W. A.: Technische Mechanik 2: Elastostatik, Springer-Lehrbuch, 11. bearb. Aufl., Springer, Berlin, ISBN 9783642005640, 2012. a, b
Gundlach, J. and Govers, Y.: Experimental modal analysis of aeroelastic tailored rotor blades in different boundary conditions, J. Phys.: Conf. Ser., 1356, 012023, https://doi.org/10.1088/1742-6596/1356/1/012023, 2019. a
He, K., Zhang, X., Ren, S., and Sun, J.: Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, https://doi.org/10.48550/arXiv.1502.01852, 2015. a
Herman, J. and Usher, W.: SALib: An open-source Python library for Sensitivity Analysis, J. Open Source Softw., 2, 97, https://doi.org/10.21105/joss.00097, 2017. a
Hodges, D. H.: Nonlinear composite beam theory, in: vol. 213 of Progress in astronautics and aeronautics, American Institute of Aeronautics and Astronautics, Reston, VA, ISBN 1563476975, 2006. a, b
Hofmeister, B., Bruns, M., and Rolfes, R.: Finite element model updating using deterministic optimisation: A global pattern search approach, Eng. Struct., 195, 373–381, https://doi.org/10.1016/j.engstruct.2019.05.047, 2019. a
Knebusch, J., Gundlach, J., and Govers, Y.: A systematic investigation of common gradient based model updating approaches applied to high-fidelity test-data of a wind turbine rotor blade, in: Proceedings of the XI International Conference on Structural Dynamics, EASDAthens, 2159–2174, https://doi.org/10.47964/1120.9175.19508, 2020. a, b
Lin, J., Leung, L. K., Xu, Y.-L., Zhan, S., and Zhu, S.: Field measurement, model updating, and response prediction of a large-scale straight-bladed vertical axis wind turbine structure, Measurement, 130, 57–70, https://doi.org/10.1016/j.measurement.2018.07.057, 2018. a
Liu, X., Leimbach, K. R., and Hartmann, D.: System identification of a wind turbine using robust model updating strategy, in: Proceedings of 19th International Conference on the Application of Computer Science and Mathematics in Architecture and Civil Enrineering, Weimar, 250–260, https://e-pub.uni-weimar.de/opus4/frontdoor/deliver/index/docId/2457/file/IKM2012_pdfa.pdf (last access: 14 March 2022), 2012. a
Luczak, M., Manzato, S., Peeters, B., Branner, K., Berring, P., and Kahsin, M.: Updating Finite Element Model of a Wind Turbine Blade Section Using Experimental Modal Analysis Results, Shock Vibrat., 2014, 1–12, https://doi.org/10.1155/2014/684786, 2014. a, b
Marwala, T., Boulkaibet, I., and Adhikari, S.: Probabilistic Finite Element Model Updating Using Bayesian Statistics, John Wiley & Sons, Ltd, Chichester, UK, https://doi.org/10.1002/9781119153023, 2016. a, b
Noever-Castelos, P.: IWES-LUH/Beam-ModelUpdating-cINN, Zenodo [code], https://doi.org/10.5281/zenodo.6351906, 2022a. a
Noever-Castelos, P.: Training data and models for cINN model updating of finite element beam models of wind turbine blades, Research Data Repository of the Leibniz Universität Hannover [data set], https://doi.org/10.25835/0042221, 2022b. a
Noever-Castelos, P., Ardizzone, L., and Balzani, C.: Model updating of wind turbine blade cross sections with invertible neural networks, https://doi.org/10.15488/11045, 2021. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t
Noever-Castelos, P., Haller, B., and Balzani, C.: Validation of a modeling methodology for wind turbine rotor blades based on a full-scale blade test, Wind Energ. Sci., 7, 105–127, https://doi.org/10.5194/wes-7-105-2022, 2022. a, b, c, d
Olufsen, M. S. and Ottesen, J. T.: A practical approach to parameter estimation applied to model predicting heart rate regulation, J. Math. Biol., 67, 39–68, https://doi.org/10.1007/s00285-012-0535-8, 2013. a, b
Omenzetter, P. and Turnbull, H.: Comparison of two optimization algorithms for fuzzy finite element model updating for damage detection in a wind turbine blade, in: Nondestructive Characterization and Monitoring of Advanced Materials, Aerospace, Civil Infrastructure, and Transportation XII, edited by: Shull, P. J., SPIE, p. 60, https://doi.org/10.1117/12.2295314, 2018. a, b, c
Pastor, M., Binda, M., and Harčarik, T.: Modal Assurance Criterion, Proced. Eng., 48, 543–548, https://doi.org/10.1016/j.proeng.2012.09.551, 2012. a, b
Patelli, E., Govers, Y., Broggi, M., Gomes, H. M., Link, M., and Mottershead, J. E.: Sensitivity or Bayesian model updating: a comparison of techniques using the DLR AIRMOD test data, Arch. Appl. Mech., 87, 905–925, https://doi.org/10.1007/s00419-017-1233-1, 2017. a
Saltelli, A., Ratto, M., Andres, T., Campolongo, F., Cariboni, J., Gatelli, D., Saisana, M., and Tarantola, S.: Global Sensitivity Analysis: The Primer, John Wiley & Sons, New York, NY, ISBN 9780470059975, 2008. a, b, c, d
Sayer, F., Antoniou, A., Goutianos, S., Gebauer, I., Branner, K., and Balzani, C.: ReliaBlade Project: A Material's Perspective towards the Digitalization of Wind Turbine Rotor Blades, IOP Conf. Ser.: Mater. Sci. Eng., 942, 012006, https://doi.org/10.1088/1757-899X/942/1/012006, 2020. a
Schröder, K., Grove, S., Tsiapoki, S., Gebhardt, C. G., and Rolfes, R.: Structural Change Identification at a Wind Turbine Blade using Model Updating, J. Phys.: Conf. Ser., 1104, 012030, https://doi.org/10.1088/1742-6596/1104/1/012030, 2018. a, b
Sehgal, S. and Kumar, H.: Structural Dynamic Model Updating Techniques: A State of the Art Review, Arch. Comput. Meth. Eng., 23, 515–533, https://doi.org/10.1007/s11831-015-9150-3, 2016. a
SmartBlades2: Fabrication, Testing, and Further Development of Smart Rotor Blades, coordinated research project (project numbers 0324032A-H), supported by the Federal Ministry for Economic Affairs and Energy of Germany due to a decision of the German Bundestag, 2016–2020. a
Sobol', I. M.: Sensitivity estimates for nonlinear mathematical models, Math. Model. Comput. Exp., 1, 407–414, 1993. a, b
Sobol', I. M.: Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates, Math. Comput. Simul., 55, 271–280, https://doi.org/10.1016/S0378-4754(00)00270-6, 2001. a
Velazquez, A. and Swartz, R. A.: Operational model updating of low-order horizontal axis wind turbine models for structural health monitoring applications, J. Intel. Mater. Syst. Struct., 26, 1739–1752, https://doi.org/10.1177/1045389X14563864, 2015. a
Visual Learning Lab Heidelberg: FrEIA – Framework for Easily Invertible Architectures, GitHub, https://github.com/VLL-HD/FrEIA (last access: 14 March 2022), 2021. a
- Abstract
- Introduction
- Sensitivity analysis of modal responses of a rotor blade finite element beam model
- Invertible neural network architecture
- Model updating of a rotor blade beam model
- Conclusions
- Appendix A: Tables and figures
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Sensitivity analysis of modal responses of a rotor blade finite element beam model
- Invertible neural network architecture
- Model updating of a rotor blade beam model
- Conclusions
- Appendix A: Tables and figures
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References