the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 19 Jan 2026
| 19 Jan 2026
Determining the ideal length of wind speed series for wind speed distribution and resource assessment
Igor Esau
Accurate wind resource assessment depends on wind speed data that capture local wind conditions, which are crucial for energy yield estimates and site selection. While the International Electrotechnical Commission (IEC) recommends at least 1 year of data collection, this duration may be insufficient to fully capture interannual variability. Although studies often maximize data length, limited guidance exists on the minimum sample size required to reliably estimate wind statistics and energy potential. To address this gap, we propose a method to quantify errors in wind speed distribution parameters arising from the use of time series of varying lengths compared with long-term reference data. This enables us to determine the minimum number of hourly observations needed to achieve a given accuracy. We apply this method to in situ station observations and ERA5 reanalysis data at 10 and 100 m heights. Our results show that basic parameters (mean, standard deviation, and Weibull parameters) stabilize with a sample size equivalent to ∼ 1 month of hourly data (not a contiguous period) drawn across multiple years, while higher-order moments require substantially larger samples (skewness: equivalent to ∼ 1.6 years; kurtosis: equivalent to 88.6 years). Although ERA5 stabilizes faster, it exhibits systematic biases compared to in situ measurements. Moreover, random cross-year sampling yields comparable distribution parameters to diurnally or seasonally controlled sampling, while continuous sampling demands far longer records for the same accuracy. These findings provide a practical framework for optimizing data collection in wind resource assessments, balancing accuracy, temporal coverage, and resource constraints.
- Article
(7497 KB) - Full-text XML
-
Supplement
(4805 KB) - BibTeX
- EndNote




Wind energy production critically depends on the strengths and persistence of winds in Earth's lower atmosphere. A precise and cost-effective assessment of wind speed is crucial for evaluating wind energy potential and designing wind farms and power generators because accurate assessments ensure that the selected site has adequate wind conditions, making the investment economically viable and optimizing energy production efficiency (Wang et al., 2022). Quantifying wind speed characteristics, a crucial component of wind speed assessment, typically relies on analysing wind speed distribution from collected data. Ideally, long-term meteorological measurements at the proposed wind turbine locations are preferred as they account for a broader range of wind variability. Wind speed measurements covering 4 years are typically considered to be suitable for short-term analysis, while datasets extending beyond this period fall into the category of long-term analysis. A 10-year dataset is generally recommended for the most accurate wind resource assessment, if available (Murthy and Rahi, 2017). However, collecting such long-term measurements is often impractical due to the time and financial constraints involved, particularly in the early planning stages of wind farm development (Wais, 2016).
As a more practical alternative, wind energy potential is often assessed using wind speed data covering a single year or a few years (Ouarda et al., 2015). A review of 46 studies revealed that 31 of them (67.4 %) used wind speed time series of 6 years or less. However, such datasets lack year-to-year (interannual) variability, which can significantly affect wind speed and, consequently, wind power output (Jung and Schindler, 2018). For example, decadal changes in wind speed can result in a 17 ± 2 % variation in potential wind energy (Zeng et al., 2019). Since wind farms typically operate for 20 to 30 years (Pryor et al., 2020), relying on such short-term datasets without accounting for interannual variability can introduce significant biases into wind energy assessments. Additionally, short-term datasets may lack seasonal or diurnal characteristics due to sampling frequency or other factors that lead to data gaps. For instance, the Sentinel-1 Ocean wind product, aligning well with in situ observations and reanalysis products (Khachatrian et al., 2024), revisits the same location only once every 1 or 2 d, making it unable to capture the diurnal characteristics of wind speed.
This discussion highlights a critical research gap: the optimal duration of wind observation time series required to adequately account for wind variability in resource assessments remains poorly quantified. Specifically, is 1 year of data, as recommended by the IEC (International Electrotechnical Commission, 2019), sufficient to provide accurate assessments of wind distributions given the interannual variability of wind? Furthermore, considering the challenges in obtaining long-term observations, if we must rely on short-term datasets that may lack interannual, seasonal, or diurnal variability, how do errors vary with the length of data time series?
This research gap has been highlighted in previous studies. For instance, Barthelmie and Pryor (2003) and Pryor et al. (2004) evaluated the accuracy of satellite sampling in representing offshore wind speed distributions. They quantified the numbers of satellite observations required to estimate key probability distribution parameters with an uncertainty of ±10 %. Specifically, the mean and Weibull scale parameter required about 60–70 randomly selected half-hourly observations, respectively. In contrast, the variance requires 150 observations, and the Weibull shape parameter and energy density require nearly 2000 observations, while skewness and kurtosis required 9712 and more than 10 000 observations. However, these results are specific to satellite observations and may not directly apply to in situ measurements without further analysis. In situ measurements, such as meteorological weather stations, are more widely distributed, accessible, and frequently used in wind energy studies (Ouarda et al., 2015; Wang et al., 2016). To the authors' knowledge, relatively few studies have examined in situ observations, particularly those from weather stations certified by the World Meteorological Organization (WMO).
Our study aims to evaluate the potential biases and uncertainties that may arise when short-term wind speed data from WMO weather stations are used for wind energy assessments. Previous work by Barthelmie and Pryor (2003) proposed a random sampling approach to examine how sampling protocols affect the estimation of wind speed distribution parameters. However, random sampling may overlook the diurnal and seasonal cycles that are intrinsic to in situ terrestrial wind observations and critical for reliable wind energy analysis. To address this limitation, we first compare random sampling with sampling strategies that explicitly retain diurnal and seasonal cycles. This comparison allows us to isolate and quantify the influence of temporal structures on wind speed statistics. In addition, we evaluate the practical relevance of random sampling by contrasting it with continuous sampling, which preserves the chronological sequence of wind speed data and more closely reflects real-world wind resource assessment practices. Continuous datasets, such as those from anemometer towers, are commonly used in the wind energy industry, typically covering at least 1 year of measurements to characterize site-specific wind conditions prior to turbine installation (Yang et al., 2024; Liu et al., 2023). By integrating these multiple sampling strategies, our study provides a comprehensive assessment of how sampling choices affect the robustness of wind energy evaluations based on limited-duration datasets.
We further investigate how results derived from reanalysis products differ from those obtained using WMO weather station data under various sampling strategies. Reanalysis products have emerged as a primary alternative for wind resource assessment, especially given the spatial and temporal limitations of traditional in situ observations (Gil et al., 2021; Gualtieri, 2021). These datasets provide spatially continuous and temporally consistent wind speed data by assimilating observational data from multiple sources, including satellite instruments, surface synoptic observations, ships, and drifting buoys, into numerical weather prediction models (Hersbach et al., 2020). ERA5 stands out as the most widely used and up-to-date reanalysis product. We used ERA5 in our study because of its strong agreement with observed wind data at turbine-relevant heights, especially across Europe and North America (Ramon et al., 2019). ERA5 provides wind speed data at both 10 and 100 m, enabling direct analysis at typical hub heights and thus avoiding the need for extrapolation methods, such as wind profile log or power-law methods, to estimate wind speeds at hub height (e.g. Soares et al., 2020; Jung and Schindler, 2019).
The main objectives of our study are as follows:
-
to evaluate how the wind speed statistics (e.g. distribution parameters) derived from short-term WMO station data different those obtained from longer-term records;
-
to determine the optimal time series length required for accurate estimation of wind speed distribution parameters, with quantified uncertainty margins;
-
to explore whether ERA5 reanalysis products, at both 10 and 100 m heights, yield consistent results with ground-based observations.
Through these objectives, we aim to enhance the understanding of the limitations and capabilities of short-term meteorological data in wind speed assessment, contributing to more reliable wind energy evaluations.
2.1 Sampling methods
2.1.1 Random sampling
To determine the optimal length of wind speed series for accurately representing wind speed distribution parameters, we adopted the random sampling method proposed by Barthelmie and Pryor (2003). In our study, this approach involves comparing the distribution parameters derived from the full 16-year hourly wind speed series (referred to as the study datasets) with those obtained from randomly sampled subsets of varying lengths. Specifically, we constructed sample datasets ranging from 720 h (30 d) to 52 560 h (6 years), with increments of 240 h (10 d). For each sample size, 1000 synthetic datasets were generated by randomly selecting hourly observations with replacement from the full series using NumPy's “random” module.
For each generated dataset, we calculate seven parameters: four common statistical descriptors (mean, standard deviation, skewness, kurtosis), two Weibull parameters (shape and scale), and the Weibull wind power density. To evaluate the representativeness of these sampled subsets, we computed the percent error between each parameter estimated from the sample and the corresponding parameter from the full 16-year series. Specifically, we focused on the upper and lower bounds of the 90 % confidence interval for each parameter across 1000 realizations at each sample size. The percent errors (Y) in these bounds were then modelled as a function of sample size (n) using non-linear least-squares fitting, resulting in an equation that describes how sampling uncertainty decreases with increasing sample size; the corresponding bounds are ±Y(n), expressed as in Eq. (1):
These fitted curves enable the estimation of the minimum dataset length needed to achieve predefined error margins.
We selected 720 h as the starting point based on its frequent use in previous wind studies (e.g. Jung and Schindler, 2019; Ouarda and Charron, 2018), while the upper limit of 52 560 h (equivalent to 6 years of hourly data) was based on prior findings (Barthelmie and Pryor, 2004) showing that percent errors generally stabilize before this duration.
2.1.2 Diurnal- and seasonality-retained sampling
We implemented two structured sampling methods to retain key temporal patterns in the wind speed data: diurnal-retained sampling and seasonality-retained sampling. In the diurnal-retained approach, each synthetic dataset consists of observations evenly distributed across four 6 h time intervals (00:00–05:00, 06:00–11:00, 12:00–17:00, and 18:00–23:00) to preserve daily variability. For example, when the sample size is 720, we select 180 observations from each time interval. In the seasonality-retained sampling, each dataset includes an equal number of observations from all 12 months, thereby maintaining seasonal structure. For a sample size of 720, this results in 60 observations per month. For both methods, sampling was performed with replacement, meaning that the same observation could be selected in multiple realizations.
2.1.3 Continuous sampling
The continuous sampling method is designed to simulate real-world scenarios in which wind speed data are used in their natural temporal sequence. Unlike the random and stratified (diurnal- or seasonality-retained) sampling approaches, this method preserves the chronological order of observations by extracting time-contiguous subsets directly from the full series. Prior to sampling, linear interpolation was applied to fill any missing values. In this study, we investigated sample sizes ranging from 720 h (approximately 1 month) to 103 680 h (12 years), increasing in 1-month (720 h) increments. As this method requires each extracted subset to be continuous, the source dataset must be longer than or equal to the target sample size. For example, given a 46-year hourly wind speed dataset, we can extract all possible 1-year-long continuous sequences (i.e. using a moving window of 1 year), resulting in 395 089 potential samples of 8640 hourly observations each. Due to computational constraints, we randomly selected 1000 sequences for each sample size, in line with the approach used for the other sampling methods. The same parameter estimation procedure was then applied to these sequences to assess variability and to estimate confidence intervals.
2.2 Probability density distributions
In this study, we exclusively employed the two-parameter Weibull probability density function to fit wind speed data. The function is expressed in Eq. (2):
where v represents the wind speed, k is the shape parameter, and c is the scale parameter. The Weibull distribution is characterized by two key parameters: the dimensionless shape parameter, which determines the curve's shape, and the scale parameter, which adjusts the distribution along the wind speed axis. The distributions vary with different values of k and c, making it a popular choice for approximating observed wind speed frequencies (Wais, 2017; Ouarda and Charron, 2018; Carta et al., 2009).
To estimate the Weibull parameters, we used the “weibull_min.fit” function from Python's “scipy.stats”, employing the maximum likelihood estimation (MLE) method. MLE is preferred for its superior performances in parameter selection (Mohammadi et al., 2016). This “weibull_min.fit” function is particularly useful for iterative experiments requiring repeated Weibull distribution fitting, such as those with thousands of iterations.
We focused on the first four moments of the distributions, namely the mean, standard deviation, skewness, kurtosis, and Weibull shape and scale parameters, chosen for their importance in wind resource assessment. The standard deviation indicates wind speed variability, while skewness and kurtosis provide insights into asymmetry and extreme values in the distribution. We calculated the mean and standard deviation using Python's “NumPy” package, and the other parameters were calculated with scipy.stats.
2.3 Wind resource assessment method
We used the Weibull wind power density to represent wind resources at a specific location. The Weibull wind power density is calculated using the estimated Weibull k and c parameters and is given by Eq. (3):
where E represents the wind power density (W m−2), ρ is air density (with 1.225 kg m−3, the standard air density provided by the IEC, used for calculation), and Γ is the gamma function.
We chose the Weibull wind power density in our study for two main reasons. First, wind power density measures the amount of kinetic energy in airflow passing through a unit area, which can be converted into wind energy. It is a critical metric for evaluating wind resources and has been widely adopted in previous studies (e.g. Wang et al., 2022; Mohammadi et al., 2016). Second, the Weibull wind power density can be easily derived from the scale and shape parameters of the Weibull distribution, simplifying the calculation process.
Given that our objective is to determine which sample size, specifically, which time series length, most accurately represents long-term wind conditions, the use of Weibull wind power density enables us to compare how the shape and scale parameters vary with datasets of different lengths. This approach helps us more effectively identify the time series length that best captures long-term wind resource variability.
2.4 Data sources
2.4.1 In situ observations from weather stations
In this study, we first utilized weather station observations from the Norwegian Meteorological Institute (MET Norway). This data, accessed via their API (https://frost.met.no/observations/v0.jsonld?; last access: 12 December 2025), offers an hourly wind speed resolution over long periods, which is suitable for analysing interannual variability as wind assessments typically need at least hourly resolution (Jung and Schindler, 2019).
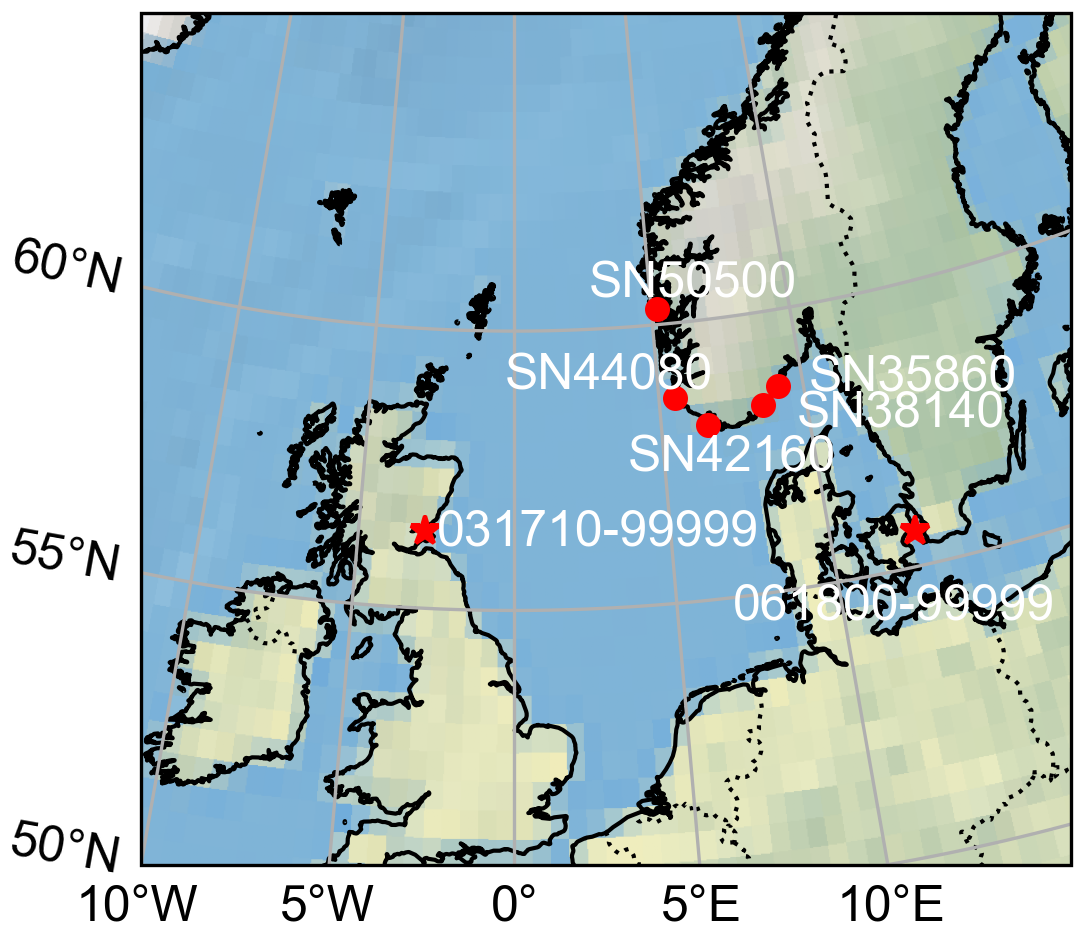
To compare wind distribution parameters from short-term data with long-term series that include interannual variability, we prioritized weather stations with the longest hourly data series, retaining years with at least 8600 hourly observations (97.9 % of the possible 8760 or 8784 h annually). Five stations met the criterion of having more than 16 years of hourly data: SN50500 (18 years), SN44080 (16 years), SN42160 (20 years), SN38140 (24 years), and SN35860 (17 years). Station details are provided in Table 1, and their locations in southern Norway are shown in Fig. 1. For consistency across sites, we restricted the analysis to 16 years per station by excluding years with fewer observations. Because using the same calendar years across all stations was not possible due to differences in data availability, the analysed years vary by station (Table S1 in the Supplement). The year with the lowest coverage still contained 8648 hourly observations (98.45 %), and the mean annual count was 8744 h (99.54 %).
Additionally, to complement the main analysis conducted on the five Norwegian stations mentioned above, we used two additional stations located in Copenhagen Airport (Denmark) and Leuchars (Scotland, UK) from another dataset, HadISD, version v3.4.2.202501p (https://www.metoffice.gov.uk/hadobs/hadisd/; last access: 12 December 2025; Dunn et al. 2016). Both sites provide 46 years (1979–2024) of hourly wind speed observations with an average data coverage of 99.2 % annually (minimum yearly data coverage is 95.7 % due to untimely updated data for 2024). The data coverage of each year is shown in Fig. S1.
Table 1Details of weather stations used in this study.
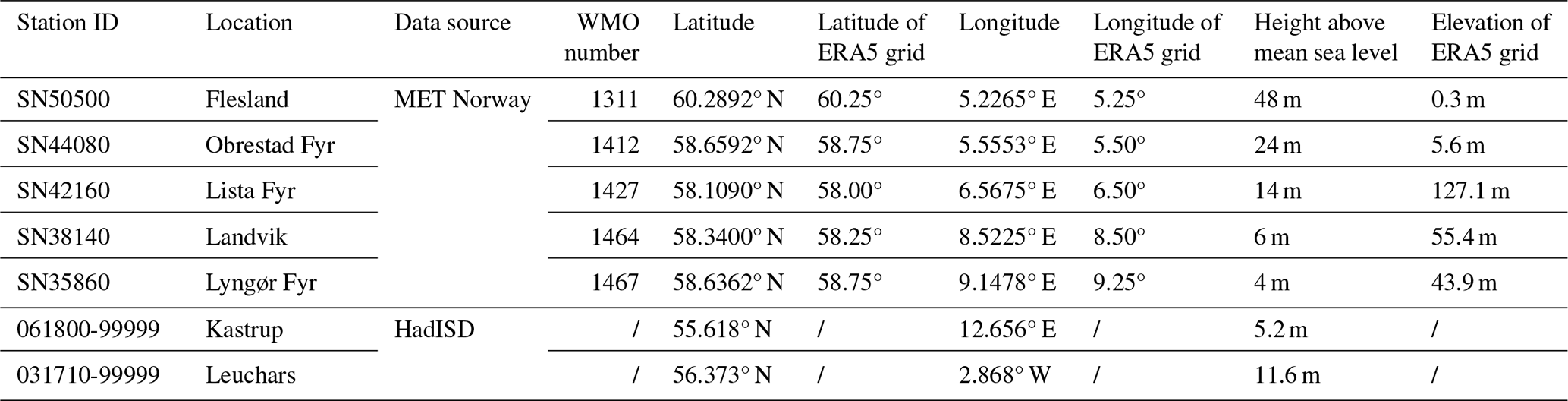
Note that, as the last two stations (Kastrup and Leuchars) were added specifically for the sensitivity analysis discussed in Sect. 4.1, they were excluded from the comparison with ERA5.
2.4.2 ERA5 reanalysis
For the ERA5 reanalysis products, we downloaded the “10 m u-component of wind”, “10 m v-component of wind”, “100 m u-component of wind”, and “100 m v-component of wind” variables from the Copernicus Climate Data Store (https://doi.org/10.24381/cds.adbb2d47, Hersbach et al., 2018). We calculated the wind speed at 10 and 100 m by taking the square root of the sum of the squares of the u-component and v-component of wind. We used the ERA5 grid point closest to the location of each station, as indicated in Table 1.
3.1 Can random sampling replace diurnal-cycle-retained or seasonality-retained sampling?
The five Norwegian stations exhibit distinct diurnal and seasonal variations (Figs. S2–S3). To assess whether random sampling can serve as a substitute for diurnal-cycle-retained or seasonality-retained sampling, we compared the 90 % confidence intervals (CIs) of distribution parameters derived from each method rather than single-point parameter estimates. This comparison can also help understand how sampling strategy affects uncertainty.
To visually compare the uncertainty ranges between the sampling methods, Figs. 2 and S4 present the 90 % confidence intervals (CIs) derived from each approach. It is evident that the intervals from random sampling largely overlap with those from diurnal- and seasonality-retained sampling. To quantify these differences, we calculated the CI differences (Fig. S5) and the root mean square error (RMSE) of these differences (Table S2). Most parameter differences fluctuate around zero, with magnitudes that are generally within ±0.2; power density is the only parameter showing larger fluctuations, within ±3. These differences tend to decrease as sample density increases (Fig. S5). Power density also exhibits the largest RMSE, likely due to its broader value range (from tens to hundreds), while the shape parameter shows the smallest RMSE (Table S2).
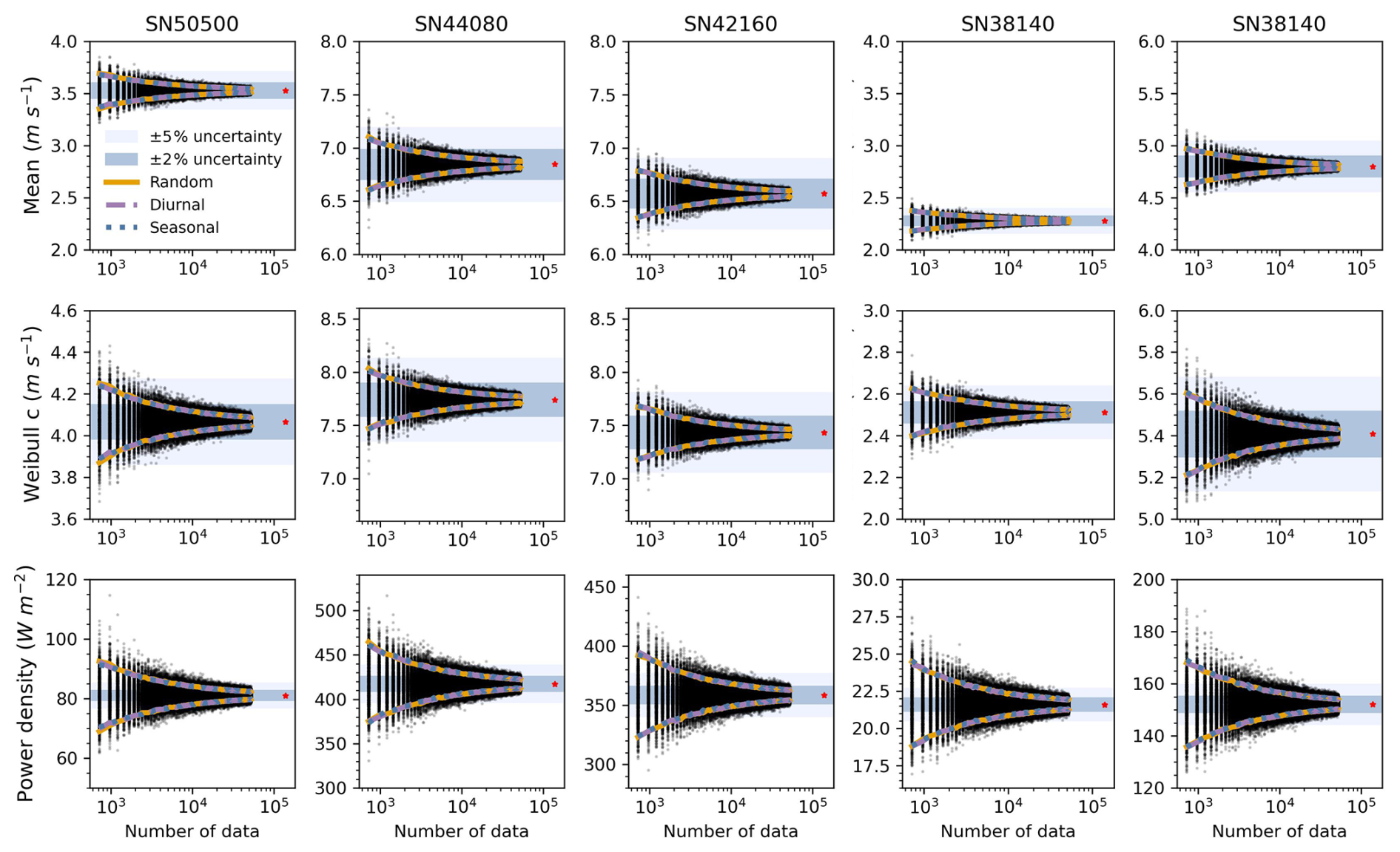
Figure 2Estimates of mean wind speed, Weibull scale parameter, and power density from three sampling strategies based on in situ observations from five Norwegian stations. The 90 % confidence intervals (CIs) are shown for each sampling method: random (orange), diurnal-cycle-retained (purple dashed), and seasonality-retained (blue dotted). Each black dot represents a parameter estimate from a single sampling realization of random sampling; corresponding realizations for the other two methods are not shown. Sample sizes range from 720 to 52 560, increasing in 240 h increments, with 1000 realizations per size. Red asterisks indicate the reference values from the full 16-year hourly dataset (see Table 2). Shaded areas represent the ±2 % (dark blue) and ±5 % (light blue) deviation ranges from full-series values.
We further examined whether similar results hold for ERA5 100 m wind speed data, which better reflect turbine-relevant altitudes and help address the scarcity of high-elevation measurements. Similar CI overlaps were observed (Figs. 3 and S6). The mean RMSEs of the differences in parameters from the ERA5 100 m (0.4896 for diurnal-retained and 1.1010 seasonal-retained) were comparable to the in situ values: 0.2865 (diurnal-retained) and 0.3903 (seasonality-retained). The higher values were primarily driven by power density differences (Table S2). A similar pattern in the 90 % confidence interval differences among the three sampling strategies is observed in the ERA5 100 m dataset and the in situ observations (Fig. S7). Based on these findings, we conclude that random sampling is a viable method for estimating wind distribution parameters, both at the surface and at turbine hub heights. Therefore, we adopted random sampling in subsequent analyses to determine the optimal sample size for capturing long-term wind characteristics.
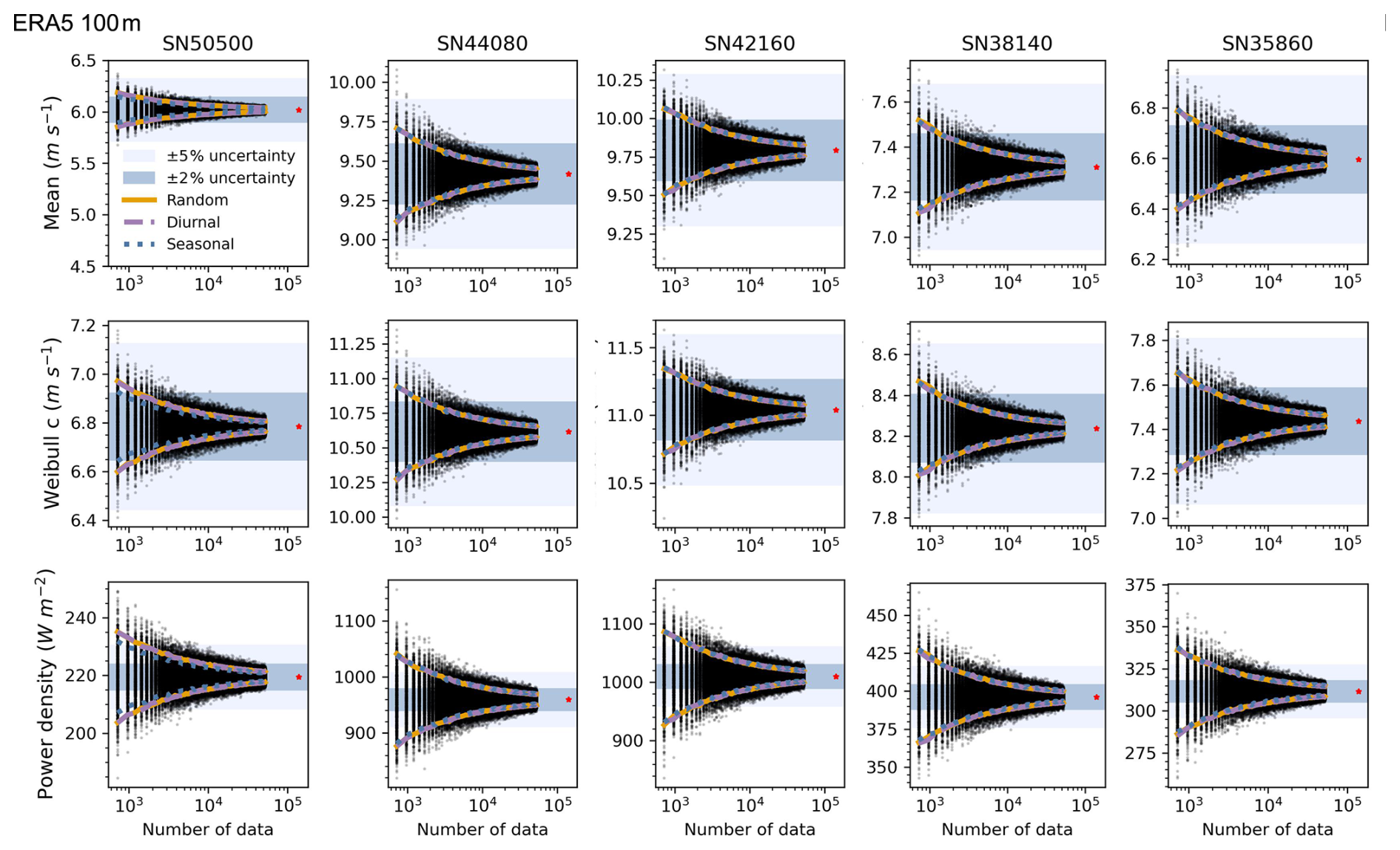
Figure 3Estimates of mean wind speed, Weibull scale parameter, and power density from three sampling strategies based on ERA5 100 m data. Sampling methods and visualization are consistent with Fig. 2. Red asterisks indicate values from the full 16-year ERA5 100 m dataset. Shaded areas represent ±2 % (dark blue) and ±5 % (light blue) deviation ranges from full-series values.
3.2 Effects of sample size on estimating wind distribution parameters
We investigated how sample size affects the accuracy of wind distribution parameters. Despite differences in wind conditions (Table 2; Fig. S8), all five Norwegian stations exhibited consistent patterns. We found that, as sample size increased, the 90 % confidence intervals (CIs) for all parameters narrowed, though the rate of convergence varied. The mean, standard deviation, and Weibull k and c parameters stabilized quickly, within ±5 % error margins, even at 720 hourly observations (Figs. 2 and S4). In contrast, power density showed greater variability, and skewness and kurtosis were far less robust, remaining beyond ±5 % even after 6 years of hourly data due to their sensitivity to distribution tails and extremes.
Table 2Distribution parameters and Weibull power density of five Norwegian stations, derived from the entirety of the datasets. Note that, for ERA5 products, the station ID indicates the corresponding grid point location.
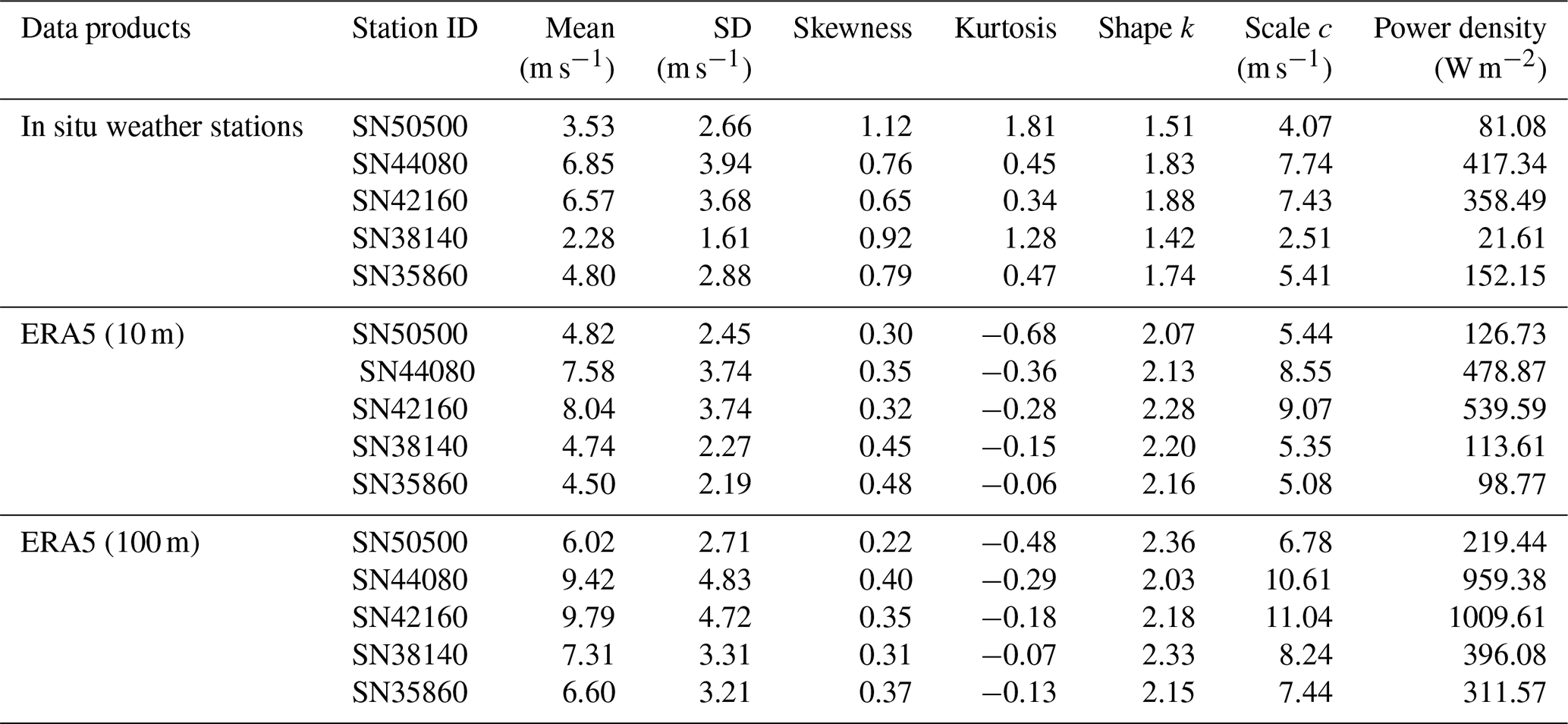
To assess systematic bias, we examined the median values across 1000 resampling iterations (Fig. S9). Skewness and, especially, kurtosis showed notable underestimation at low sample sizes. At 720 observations, median skewness was over 2 % lower, and kurtosis was more than 25 % lower than the full-series baseline. The kurtosis bias remained above 10 % until the sample size exceeded 2160 h, and SN50500 required 22 080 observations (equivalent to ∼ 2.5 years) to reduce the bias to within 10 %. In contrast, other parameters varied by less than 1 % across all sample sizes.
3.3 Determine an effective sample size for capturing overall wind characteristics
To determine the optimal sample size for capturing wind characteristics, we analysed the relationship between percent errors and sample sizes (Figs. 4–5). Percent error measures discrepancies between parameters from the full dataset and smaller subsets. Based on the 90 % CIs derived from 1000 realizations of random sampling of the in situ observations (orange lines in Figs. 2 and S4), we computed the percent errors of CI bounds and fitted equations describing their dependence on sample size. These fitted equations are summarized in Table 3 and allow extrapolation of error margins for any given sample size.
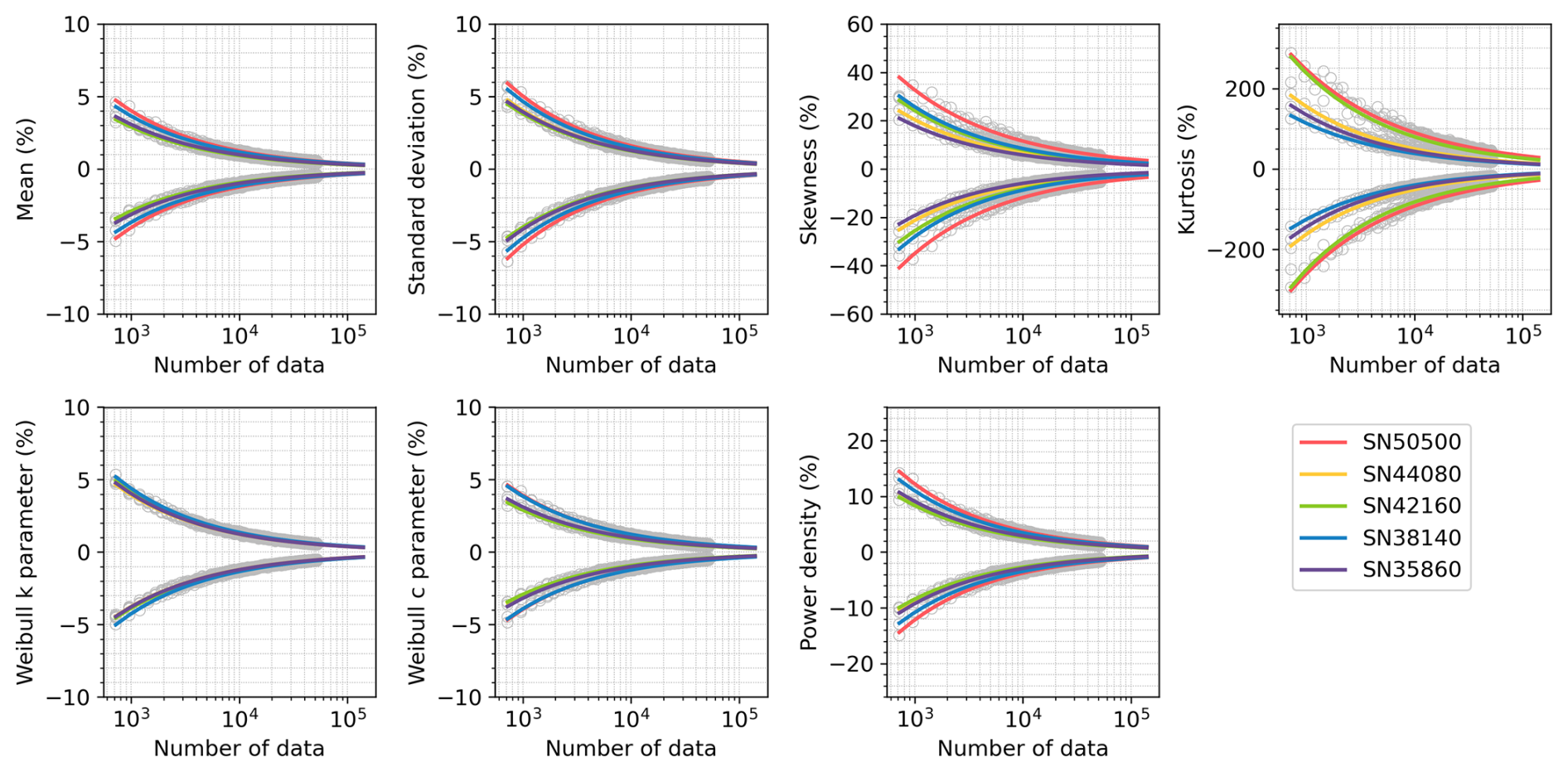
Figure 4The relationship between the percent error (Y) and sample size (n) (number of hourly observations) across five stations. Curves are fitted for n=720–140 160, with n=720 being equivalent in size to 30 d of hourly data and 140 160 being equivalent to 16 years. The equations of fits are shown in Table 3. Grey circles indicate the values used to fit the 90 % confidence intervals for the percent error shown.
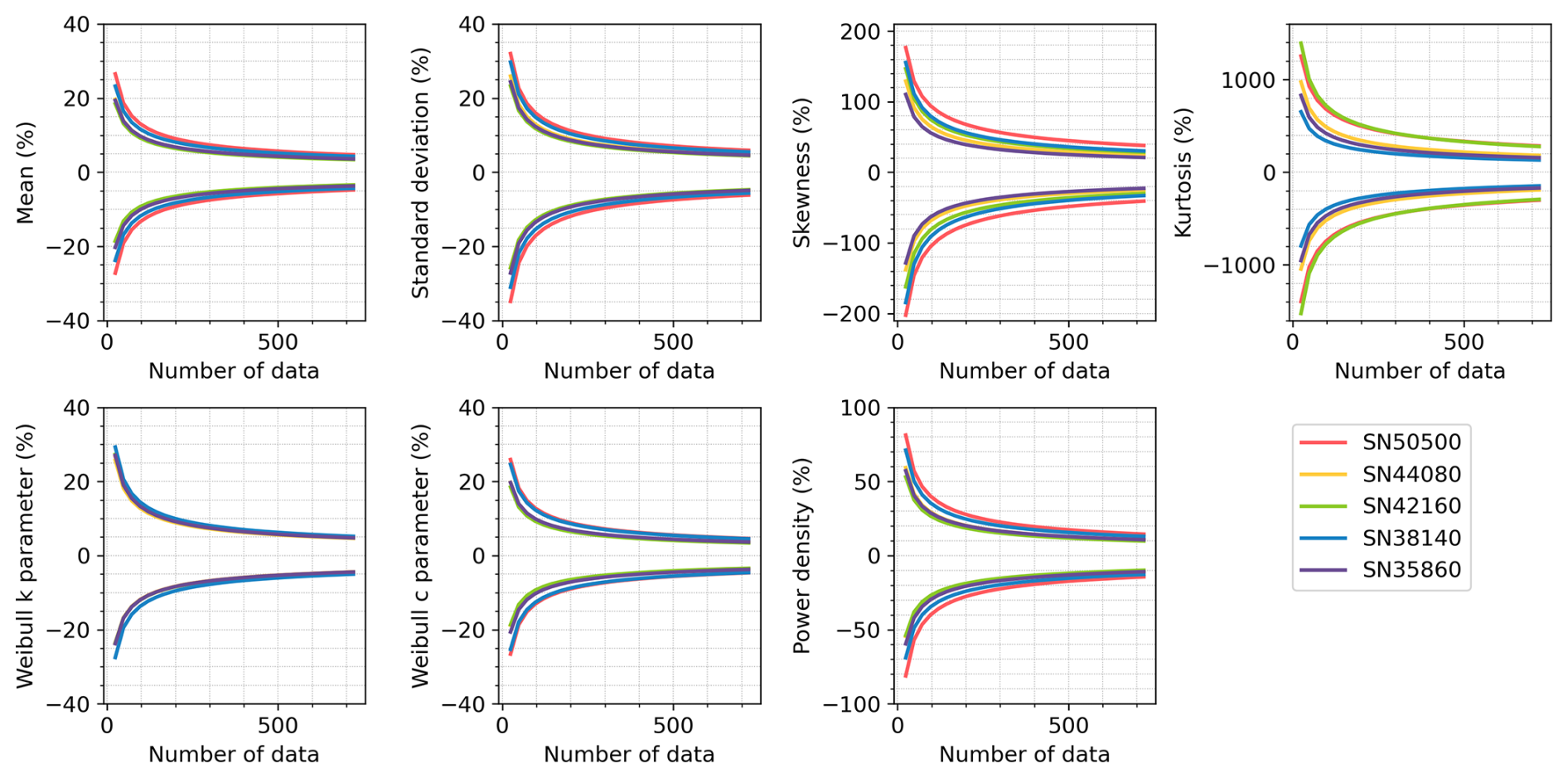
Figure 5Same as Fig. 4 but for the hourly observations in the range n=24–720 across five stations. These intervals are calculated using the same fits as shown in Fig. 4.
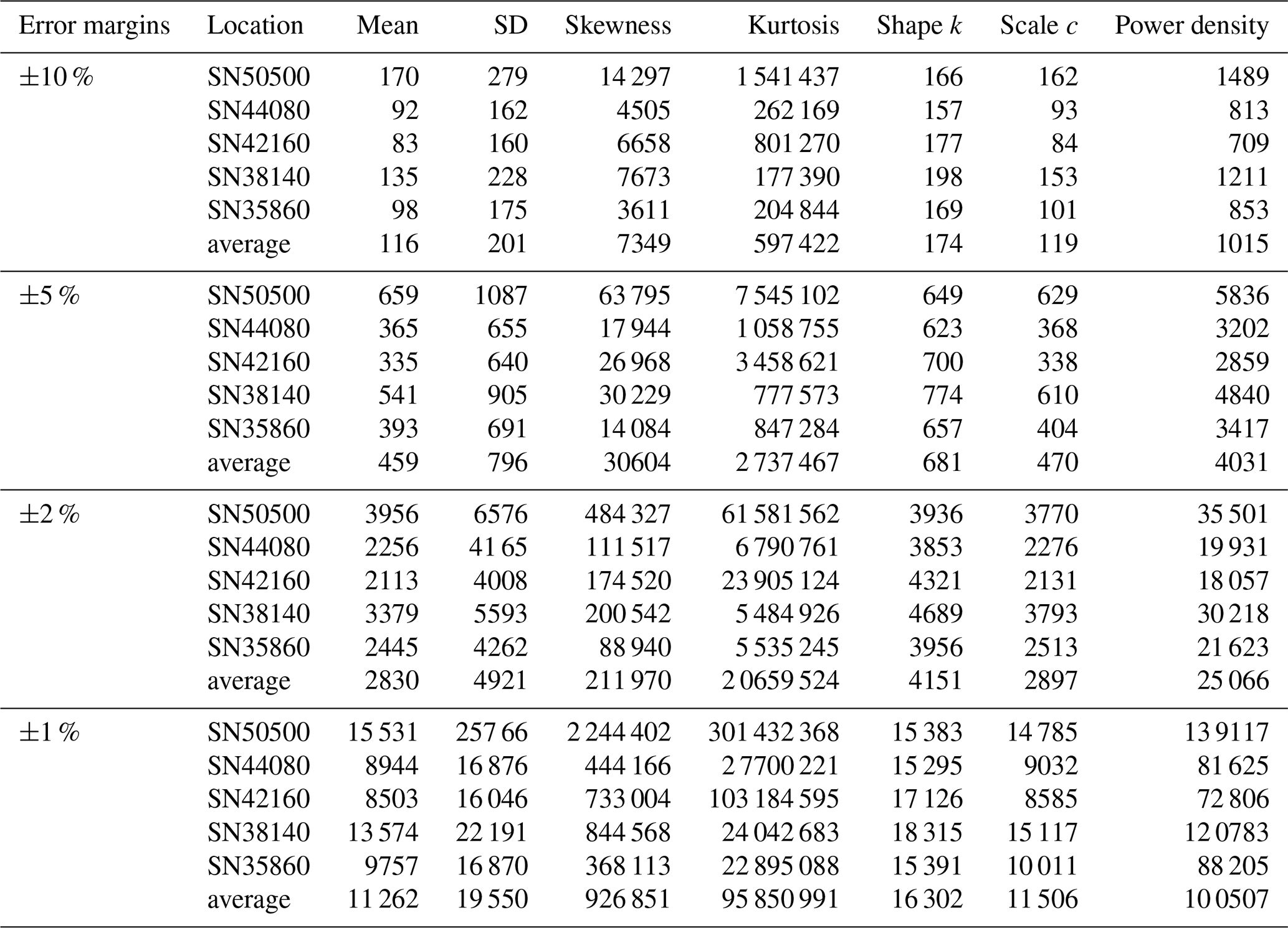
As expected, the percent error decreases with increasing sample size, though the rate and extent vary across parameters. For most stations, 720 hourly observations are sufficient to constrain the percent errors within ±7 % for the mean, standard deviation, and Weibull parameters (Fig. 4). In contrast, higher-order statistical moments such as skewness and kurtosis, as well as power density, show much larger errors under the same sampling conditions, with deviations ranging from ±10 % up to ±150 %, depending on the station. These parameters show greater variability across stations, with error differences of 4.6 % for power density, 18.1 % for skewness, and 154.2 % for kurtosis compared to less than 1.5 % for others. Errors decrease quickly below 400 observations and more slowly above (Fig. 5). About 200 observations can achieve ±10 % error for the mean, standard deviation, and Weibull parameters (Fig. 5). To facilitate practical use, we calculated the minimum sample sizes required to achieve ±10 %, ±5 %, ±2 %, and ±1 % error margins for each parameter at each station (Table 4). For example, ±5 % accuracy requires 459 hourly observations for the mean, 470 for the Weibull scale (∼ 20 d equivalent), 796 for the standard deviation (∼ 34 d equivalent), and 4031 for the power density. Achieving ±2 % and ±1 % error requires 6-fold and 24-fold more observations than the ±5 % case, respectively. Skewness and kurtosis are especially data-intensive due to their sensitivity to distribution tails. For instance, SN38140 needs 177 390 observations (equivalent to ∼ 20 years) for ±10 % error, while SN50500 needs 1 541 437 observations (equivalent to ∼ 176 years).
We also observe regional differences in sample requirements. Stations with higher wind speed variability but lower skewness and kurtosis tend to require fewer samples. For example, SN50500 and SN38140, with the highest skewness and kurtosis, require more observations. Power density has the largest regional difference (max-to-min ratio = 2.1), while the Weibull shape shows the least (1.2). Skewness and kurtosis are sensitive to wind characteristics, with required samples increasing from 3.96 to 6.10 and from 8.69 to 13.16, respectively, when error margins decrease from ±10 % to ±1 %.
Table 3Fitted equations describing the relationship between percent error (Y) and sample size (n) based on random sampling results from five in situ weather stations. Each equation corresponds to a power-law fit of the 90 % confidence interval bounds, positive (P) and negative (N), for each parameter across sample sizes from 720 to 52 560 h.

Table 4Required number of randomly selected in situ observations (unit: hours) to obtain an estimate within ±10 %, ±5 %, ±2 %, and ±1 % of the parameters from the entire observed time series (157 465 data points), calculated at the 90 % confidence level. The fits to get the required data density are shown in Table S2.
3.4 Does ERA5 reanalysis (10 and 100 m) show similar results with in situ observations?
To assess the consistency of reanalysis data with in situ measurements, we compared ERA5 (10 and 100 m) and in situ observations. At four out of five stations, ERA5 overestimated mean wind speeds in both the full time series (Table 2) and sampling experiments (Figs. 6 and S10), likely due to an overrepresentation of low to moderate wind speeds (Fig. S8). This bias also led to overestimation of the Weibull scale parameter at stations with higher wind speeds and underestimation at those with lower speeds. Additionally, the Weibull shape parameter was consistently higher in ERA5, often exceeding 2, indicating a potential bias in overestimating high-wind events. These biases collectively contributed to systematic overestimation in Weibull power density (Table 2 and Figs. 6 and S10).
Both in situ and ERA5 distributions were positively skewed (Fig. S8), but in situ data had higher skewness (Table 2). ERA5 consistently showed lower skewness (Fig. S10). For kurtosis, in situ observations show positive values (Table 2), indicating more peaked distributions, whereas ERA5 exhibited negative values, reflecting a flatter, less variable distribution. The largest divergence was observed at SN50500 and SN38140 (Fig. S10), where in situ kurtosis varied substantially, while ERA5 values remained comparatively uniform (Fig. S10).
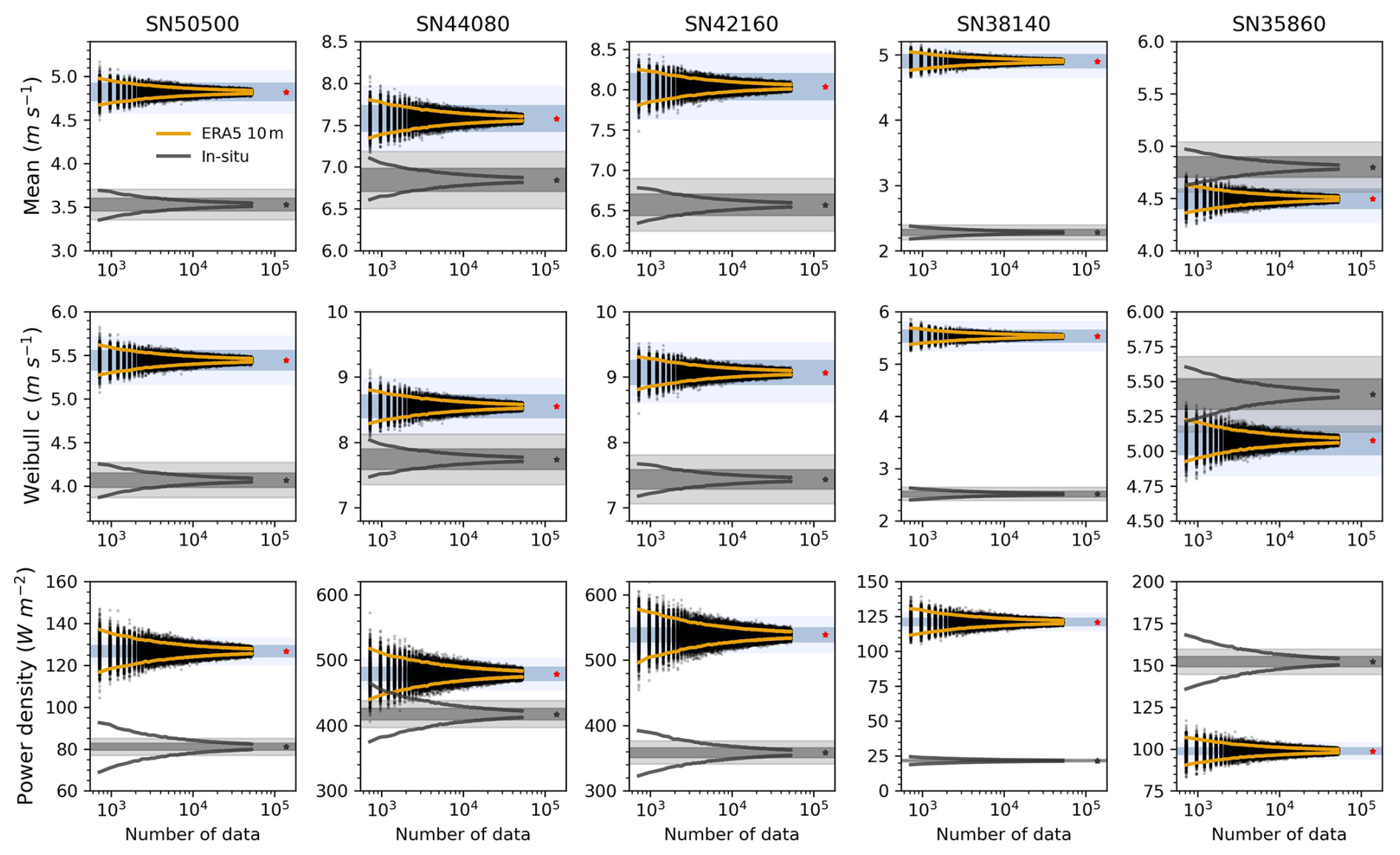
Figure 6Estimates of mean wind speed, Weibull scale parameter, and power density based on random sampling of ERA5 10 m reanalysis data (black dots) across five Norwegian stations. The sampling strategy is consistent with Fig. 2. The 90 % confidence intervals (CIs) are shown as orange lines (ERA5) and grey lines (in situ observations). Red asterisks denote reference values derived from the full 16-year ERA5 10 m dataset, and grey asterisks represent the corresponding values from in situ observations. Blue shading represents ±2 % (dark) and ±5 % (light) uncertainty margins around ERA5 10 m reference values, while grey shading indicates the same margins around in situ reference values.
These differences influence sample size requirements. For the mean, standard deviation, Weibull scale, and power density, ERA5 (10 m) generally required fewer data points to achieve the same error margin thresholds (Table S3). However, for tail-sensitive parameters like shape, skewness, and kurtosis, ERA5 requires a larger sample size. Additionally, ERA5 showed lower inter-station variability, as indicated by overlapping percent error curves (Figs. S11–S12). The equations used to estimate percent errors under different sample sizes for ERA5 10 m are summarized in Table S4.
We further analysed the ERA5 100 m dataset, which aligns more closely with hub heights. As shown in Figs. S13–S14, most parameters had similar data density requirements compared to those of the ERA5 10 m dataset, though it can vary by station. For instance, SN42160 had the highest error in the 10 m dataset, while SN35860 showed nearly double the error under the same density. Table S5 summarizes the required sample sizes, showing broadly similar patterns across both heights, but the 100 m dataset consistently required more data for the shape parameter. The equations used to estimate the required sample sizes for ERA5 100 m are summarized in Table S6.
4.1 Sensitivity to sampling strategy and climatic non-stationarity
In wind energy assessments, continuous sampling is more commonly used than random sampling because it preserves the temporal structure and seasonal variability in wind speed time series, and, most importantly, only long-term data are not available. However, continuous sampling may also introduce systematic bias, particularly over short durations, due to temporal autocorrelation and underlying climatic non-stationarity. To investigate the extent of this effect and to assess the generalizability of random sampling, we conducted a sensitivity analysis using 46 years (1979–2024) of hourly wind speed data from two coastal meteorological stations: Copenhagen Airport (061800–99999, Denmark) and Leuchars (031710–99999, Scotland). These sites were chosen for their long-term records and meteorological similarity compared to the five Norwegian locations analysed earlier. Copenhagen station exhibits a long-term decreasing wind speed trend (Fig. S1), consistently with broader global observations (Zeng et al., 2019).
Our results show that continuous sampling generally requires significantly longer periods to achieve the same level of uncertainty in estimated distribution parameters compared to random sampling (Fig. 7). This discrepancy arises because random sampling draws from multiple years, thereby capturing a wider range of interannual variability and reducing exposure to temporal clustering. Consequently, the 90 % confidence intervals (CIs) under random sampling are symmetric for all parameters, while, under continuous sampling, only the CIs for mean wind speed, Weibull scale parameter, and power density are symmetric. Shape-sensitive parameters, including standard deviation, skewness, kurtosis, and especially the Weibull shape parameter, exhibit pronounced asymmetries under continuous sampling, particularly at short durations (<2 years). This suggests that the presence of systematic climatic anomalies in continuous subsets may bias shape estimation.
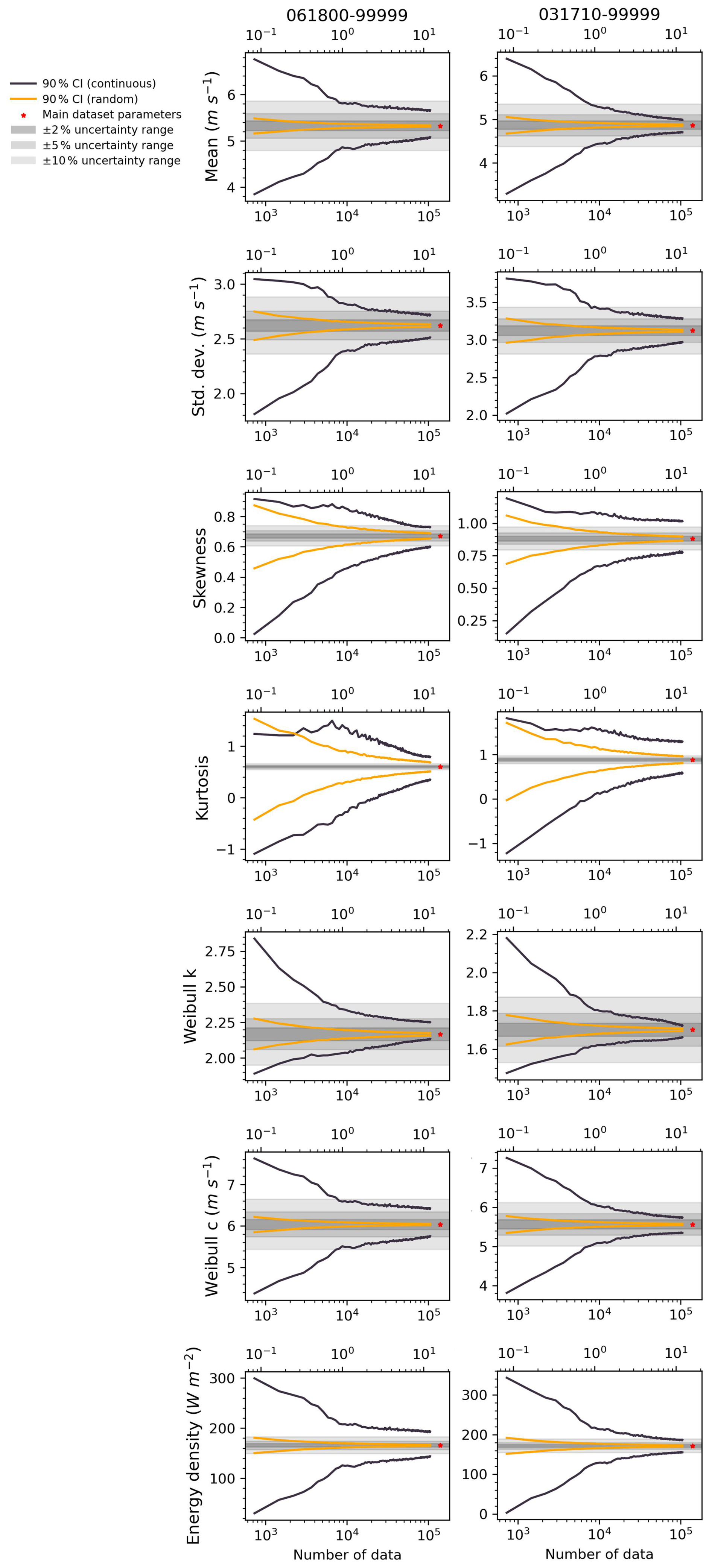
Figure 7Distribution parameters and Weibull power density derived from random sampling (orange lines) and continuous sampling (black lines) based on in situ measurements from weather stations. The x axis shows the number of hourly observations, and a secondary top axis indicates the equivalent number of years (1 year = 8760 h). Asterisks indicate values computed from the full 46-year dataset. Details of the experimental setup and sampling procedures are provided in the “Data and methods” section.
These findings support earlier recommendations by Murthy et al. (2017), who advocated for using at least 4 to 10 years of data for reliable wind energy assessments. Our results suggest that, when using continuous sampling, at least 5 years of data may be required to achieve ±10 % relative uncertainty in power density estimates, although this threshold is site-specific (e.g. Copenhagen station requires more than 10 years). We further recommend that random sampling be considered to be a complementary tool to identify potential biases in short-term continuous assessments.
The uncertainty bounds acquired by the random sampling were claimed by Barthelmie and Pryor (2003) to be robust and applicable to all remote sensing wind speed time series. Specifically, they reached this conclusion by finding a similar required sample size with an uncertainty of ±10 % from five different locations, including Denmark, the eastern North Pacific, the Gulf of Mexico, the Gulf of Alaska, and the western Atlantic (Barthelmie and Pryor, 2003; Pryor et al., 2004). However, upon replicating their methods using in situ wind speed measurements from WMO stations, we are reluctant to draw the same conclusion. However, when using the same error margin (±10 %) as Barthelmie and Pryor (2003), we obtain similar results. As the error margins narrow (from ±10 % to ±1 %), the discrepancy among stations becomes significant. Therefore, we suggest that the uncertainty bounds presented in Table 3 exhibit robustness and are applicable only under higher error margins, such as those exceeding ±10 %. Additionally, lower-order moments and two Weibull parameters showed higher robustness.
Furthermore, although we provided the uncertainty bounds for datasets with fewer than 720 samples, it is important to note that we calculated these values based on an exponential function fitted to the results derived from 720 to 52 560 points. As a result, the curve may be biased due to the potential asymmetry in the distribution of the parameters (Barthelmie and Pryor, 2003).
Our results indicated that ERA5 tends to overestimate the mean and Weibull scale parameters. Discrepancies between ERA5 and observational data are unsurprising as previous studies have noted differences in magnitude and trends (Zhou et al., 2021; Torralba et al., 2017). These discrepancies can be partly attributed to ERA5 not assimilating in situ land observations and the inherent limitations of the ERA5 reanalysis (Hersbach et al., 2020), such as its inability to accurately reproduce mesoscale dissipation rates (Bolgiani et al., 2022). Additionally, modern data assimilation systems still struggle to adequately correct the inevitable errors in model-generated guess fields at these smaller scales (Wang and Sardeshmukh, 2021). Consequently, ERA5 may underestimate variability and fail to capture local extremes observed in in situ data, leading to discrepancies in parameters like skewness and kurtosis. For instance, at stations SN50500 and SN38140, in situ data show significantly more wind observations close to zero compared to ERA5 datasets, resulting in distinct wind characteristics such as differing skewness and kurtosis.
4.2 Evaluation of global wind atlas estimates against observations
Since the publication of the first European Wind Atlas in 1989 (Dörenkämper et al., 2020), the wind atlas methodology has been widely adopted for regional wind resource assessments, including in countries such as Finland (Tammelin et al., 2013) and Greece (Kotroni et al., 2014). The Global Wind Atlas (GWA), developed by the Technical University of Denmark, applies the well-established numerical wind atlas method to downscale coarse-resolution reanalysis data to microscale levels. This is achieved using linearized flow models and topographic corrections based on the WAsP model. The GWA provides publicly accessible estimates of mean wind speed and power density, which have been used in applications such as bias correction of reanalysis data for wind power simulations (Gruber et al., 2022).
Given the energy-focused perspective of this study, it is relevant to compare our results with GWA estimates. We extracted GWA values at the nearest grid points for selected stations and compared them with observational estimates based on the full time series. Table S7 presents this comparison, focusing on two key metrics in wind energy assessments: mean wind speed and power density. The results show that GWA consistently overestimates both wind speed and power density relative to our station-based observations.
One likely explanation for this discrepancy lies in the different ways topographic effects are incorporated. As described by Davis et al. (2023), the GWA estimates the predicted wind climate (PWC) by applying high-resolution topographic perturbations to the generalized wind climate which is based on coarse reanalysis fields. The PWC is represented by a set of Weibull distributions and directional frequencies for each of the 12 directional sectors, and these are used to calculate derived variables such as mean wind speed and power density.
4.3 Implications
Both onshore and offshore sites exhibit seasonal variations, with onshore and near-coast locations often experiencing significant diurnal cycles (Barthelmie and Pryor, 2003; Barthelmie et al., 1996; Ashkenazy and Yizhaq, 2023). Our findings indicate that random sampling can effectively analyse wind distribution parameters, even when dealing with discontinuous data that lack explicit diurnal- or seasonal-cycle information. This is particularly important given the challenges associated with accurately collecting data that reflect these cycles; factors such as anemometer malfunctions, site relocations, and other disruptions can create gaps in the wind speed data series, leading to non-continuous records (Liu et al., 2024). For instance, the Sentinel-1 Level-2 OCN ocean wind field product (1 km resolution), while performing well in offshore areas, has a revisit frequency of 1 to 2 d that may not sufficiently capture rapid temporal variations (Khachatrian et al., 2024).
It was noted that this finding is drawn from analyses utilizing a 90 % confidence interval. This confidence level indicates that, while minor discrepancies may exist in the data, they are considered to be negligible under specific statistical assumptions. Therefore, we conclude that random sampling provides a practical and statistically robust alternative, particularly in scenarios where it is not feasible to retain the characteristics of diurnal cycles or seasonality.
4.4 Limitations of this study
While our study focuses on long-term wind data from five coastal onshore stations in Norway, it may not fully represent offshore wind conditions. Although these stations are all located at low elevations and near the coastline, their degree of exposure to open-sea winds varies due to local topography, coastal geometry, and sheltering effects (Fig. S15). For example, SN35860 and SN44080 are directly exposed to the open sea, while SN38140 is partially sheltered by inland terrain and surrounding vegetation. Offshore winds can differ significantly from those onshore. In our study, ERA5 data tend to overestimate the frequency of high-wind events at coastal sites. By contrast, a recent study indicates that ERA5 may underestimate strong wind speeds offshore (Gandoin and Garza, 2024), suggesting that discrepancies may stem from differences in surface roughness, atmospheric stability, and model representation of marine boundary layers. This highlights the need for targeted offshore studies, for example, using buoy-based wind measurements (Morgan et al., 2011). Furthermore, our analysis does not include complex inland terrains such as mountainous regions or deep valleys, where wind speed distributions can be bimodal (Jaramillo and Borja, 2004) or strongly affected by topographic channelling. These environments are likely to show different sensitivities to sampling strategies, especially regarding shape-related distribution metrics. We therefore recommend that future research apply this framework to both offshore locations and inland complex terrain to better capture the full range of wind resource variability and distributional stability.
Moreover, we compared the surface elevation of the ERA5 grid cells with the actual heights of the five Norwegian weather stations (Table 1). While all stations are situated near sea level (ranging from 4 to 48 m above mean sea level), ERA5 grid elevations differ substantially, with four out of five stations showing discrepancies exceeding 40 m and one exceeding 110 m. Specifically, ERA5 overestimates elevation at three stations and underestimates it at two. Interestingly, despite the mix of elevation biases, ERA5 wind speeds are overestimated at four stations and underestimated at only one. A station where ERA5 overestimated elevation is also the one where wind speed is underestimated. This suggests that elevation mismatch alone cannot fully explain the direction or magnitude of wind speed biases. Other factors, such as surface roughness and land use type, may also contribute to the discrepancies.
Another limitation is the time resolution of the wind speed data we used. We utilized hourly data instead of higher-temporal-resolution data, such as with 10 min intervals, for wind distribution assessments. Despite this, Yang et al., (2024) demonstrated that hourly wind speed data provide sufficiently accurate estimations of wind power density, with errors smaller than ±2 % when compared to 10 min resolution data. This suggests that hourly data are suitable for such analyses. Additionally, Effenberger et al. (2024) showed that 3- or 6-hourly instantaneous wind speed data can effectively preserve the distribution characteristics of 10 min wind speeds. Therefore, it is reasonable that hourly wind speed can adequately represent the characteristics of 10 min wind speeds.
It is worth noting that the hourly data provided by MET Norway represent the average wind speed over the last 10 min of each hour rather than the entire hour. Despite this, previous research found that Weibull distribution parameters remain consistent across different averaging periods (e.g. 1 and 30 min) (Barthelmie and Pryor, 2003). Based on these findings, we believe that our use of the last 10 min averages is unlikely to significantly impact the accuracy of the Weibull distribution parameters compared to full-hour averages.
Additionally, our study focuses on near-surface wind speeds (10 m), raising questions about whether our conclusions hold at turbine-height winds. Prior studies indicate a height dependency for Weibull distribution parameters, with higher altitudes typically showing higher means (and scale parameters), variances, skewness, and kurtosis, while the shape parameter remains height-independent (Barthelmie and Pryor, 2003; Dixon and Swift, 1984). Due to the absence of observational data at heights other than 10 m, we utilized the ERA5 dataset to compare distribution parameters at 10 and 100 m heights. For the five locations studied, only the mean (and Weibull scale parameter) and variance show height dependency, with other parameters (skewness, kurtosis, Weibull shape parameter) showing independence from height.
Our study quantifies the errors in estimating wind speed distribution parameters using time series of varying lengths, accounting for interannual variability. We find that skewness and kurtosis, particularly kurtosis, are systematically underestimated with small sample sizes, and this underestimation is more pronounced in datasets with higher skewness and kurtosis levels, necessitating significantly larger sample sizes for accurate estimates. While the mean and standard deviation stabilize with a few hundred hourly samples, skewness requires at least 14 084 h and kurtosis requires at least 777 573 h to meet a ±5 % error margin (1.6 years and 88.6 years equivalent, respectively). Here, “years equivalent” denotes the number of hourly observations equal to the hours in that duration and does not imply a contiguous period (observations are randomly drawn across years). These results emphasize that the required sample size is strongly dependent on the shape of the underlying distribution, with regional differences becoming more pronounced as accuracy demands increase, particularly for higher-order statistical moments like skewness and kurtosis.
These findings have important implications for wind resource assessment, particularly in regions characterized by highly variable wind regimes. In such areas, extended data collection periods or alternative strategies such as data fusion or machine learning may be essential to accurately capture higher-order statistical properties, which directly affects energy yield estimates and turbine design standards. Future studies should focus on mitigating biases in higher-order moment estimation. Moreover, extending this analysis to different terrain types and hub heights can further improve the reliability and generalizability of wind energy assessments.
We also compare different sampling strategies. Our results show that random cross-year sampling yields more statistically efficient estimates than continuous sampling, which preserves temporal correlation and diurnal patterns but introduces greater variability in estimated parameters. For instance, achieving ±10 % uncertainty in power density may require at least 5 years of continuous data, whereas an equivalent sample of 2 months of randomly sampled hourly data drawn across multiple years may suffice. This suggests that flexible sampling approaches may be feasible in data-limited environments, provided the sampling design avoids strong temporal clustering. An additional application of this result is to long-term high-resolution climate simulations: rather than processing the full, continuous multi-decadal time series, a relatively small, randomly sampled set of hourly outputs spanning multiple years can recover the key wind distribution characteristics. The required sample size can be determined from our sample size–uncertainty relationships to meet a prescribed accuracy bound, while model biases and non-stationarity should be addressed separately.
Finally, our evaluation of ERA5 reanalysis data reveals that, although such datasets require fewer data points for the same error margin, they introduce systematic biases, such as underestimating skewness and overestimating Weibull shape parameters, compared to in situ measurements. This underscores the need for caution when using reanalysis data in wind resource assessments, particularly in regions with complex wind regimes.
The code used for data processing and figure generation is available on GitHub and is archived on Zenodo (https://doi.org/10.5281/zenodo.17945145, Zhou, 2025).
The observed wind speed dataset from MET Norway is available for download from MET Norway's FROST platform (https://frost.met.no/index.html; last access: 12 December 2025). The ERA5 datasets is available at the Copernicus Climate Data Store (https://doi.org/10.24381/cds.adbb2d47, Hersbach et al., 2018).
The supplement related to this article is available online at https://doi.org/10.5194/wes-11-217-2026-supplement.
LH conceptualized and wrote the article and conducted the analysis, while IE supervised the project and contributed to the interpretation of the results and the writing.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
The work is part of the project “UiT – Intermittent character of wind energy resources on different spatial and temporal scales”, funded by the Faculty of Science and Technology, The Arctic University of Norway. We thank the two anonymous reviewers for their constructive comments, which improved the applicability and clarity of this research.
This research has been supported by the UiT academia agreement project “Maximizing wind energy production at the Arctic offshore wind farms (HAVVIND)”.
This paper was edited by Roland Schmehl and reviewed by two anonymous referees.
Ashkenazy, Y. and Yizhaq, H.: The diurnal cycle and temporal trends of surface winds, Earth Planet. Sci. Lett., 601, https://doi.org/10.1016/j.epsl.2022.117907, 2023.
Badger, M., Peña, A., Hahmann, A. N., Mouche, A. A., and Hasager, C. B.: Extrapolating satellite winds to turbine operating heights, J. Appl. Meteorol. Climatol., 55, 975–991, https://doi.org/10.1175/JAMC-D-15-0197.1, 2016.
Barthelmie, R. J. and Pryor, S. C.: Can Satellite Sampling of Offshore Wind Speeds Realistically Represent Wind Speed Distributions?, J. Appl. Meteorol., 42, 83–94, https://doi.org/10.1175/1520-0450(2003)042<0083:CSSOOW>2.0.CO;2, 2003.
Barthelmie, R. J., Grisogono, B., and Pryor, S. C.: Observations and simulations of diurnal cycles of near-surface wind speeds over land and sea, J. Geophys. Res. Atmos., 101, 21327–21337, https://doi.org/10.1029/96jd01520, 1996.
Bolgiani, P., Calvo-Sancho, C., Díaz-Fernández, J., Quitián-Hernández, L., Sastre, M., Santos-Muñoz, D., Farrán, J. I., González-Alemán, J. J., Valero, F., and Martín, M. L.: Wind kinetic energy climatology and effective resolution for the ERA5 reanalysis, Clim. Dyn., 59, 737–752, https://doi.org/10.1007/s00382-022-06154-y, 2022.
Carta, J. A., Ramírez, P., and Velázquez, S.: A review of wind speed probability distributions used in wind energy analysis. Case studies in the Canary Islands, Renew. Sustain. Energy Rev., 13, 933–955, https://doi.org/10.1016/j.rser.2008.05.005, 2009.
Dixon, J. C. and Swift, R. H.: The dependence of wind speed and Weibull characteristics on height for offshore winds, Wind Eng., 87–98, 1984.
Dunn, R. J., Willett, K. M., Parker, D. E., and Mitchell, L.:. Expanding HadISD: Quality-controlled, sub-daily station data from 1931, Geoscientific Instrumentation, Methods and Data Systems, 5, 473–491, 2016.
Dörenkämper, M., Olsen, B. T., Witha, B., Hahmann, A. N., Davis, N. N., Barcons, J., Ezber, Y., García-Bustamante, E., González-Rouco, J. F., Navarro, J., Sastre-Marugán, M., Sīle, T., Trei, W., Žagar, M., Badger, J., Gottschall, J., Sanz Rodrigo, J., and Mann, J.: The Making of the New European Wind Atlas – Part 2: Production and evaluation, Geosci. Model Dev., 13, 5079–5102, https://doi.org/10.5194/gmd-13-5079-2020, 2020.
Effenberger, N., Ludwig, N., and White, R. H.: Mind the (spectral) gap: How the temporal resolution of wind data affects multi-decadal wind power forecasts, Environ. Res. Lett., 19, https://doi.org/10.1088/1748-9326/ad0bd6, 2024.
Gandoin, R. and Garza, J.: Underestimation of strong wind speeds offshore in ERA5: evidence, discussion and correction, Wind Energ. Sci., 9, 1727–1745, https://doi.org/10.5194/wes-9-1727-2024, 2024.
Gil Ruiz, S. A., Barriga, J. E. C., and Martínez, J. A.: Wind power assessment in the Caribbean region of Colombia, using ten-minute wind observations and ERA5 data, Renew. Energy, 172, 158–176, https://doi.org/10.1016/j.renene.2021.03.033, 2021.
Gruber, K., Regner, P., Wehrle, S., Zeyringer, M., and Schmidt, J.: Towards global validation of wind power simulations: A multi-country assessment of wind power simulation from MERRA-2 and ERA-5 reanalyses bias-corrected with the global wind atlas, Energy, 238, 121520, https://doi.org/10.1016/j.energy.2021.121520, 2022.
Hersbach, H., Bell, B., Berrisford, P., Biavati, G., Horányi, A., Muñoz Sabater, J., Nicolas, J., Peubey, C., Radu, R., Rozum, I., Schepers, D., Simmons, A., Soci, C., Dee, D., and Thépaut, J.-N.: ERA5 hourly data on single levels from 1940 to present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/cds.adbb2d47, 2018.
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. R. Meteorol. Soc., 146, 730, https://doi.org/10.1002/qj.3803, 2020.
International Electrotechnical Commission: Wind energy generation systems – Part 12: Power performance measurements of electricity producing wind turbines – Overview (IEC 61400-12:2022), Int. Electrotech. Comm., https://webstore.iec.ch/en/publication/69211 (last access: 8 January 2026), 2022.
Jung, C. and Schindler, D.: On the inter-annual variability of wind energy generation – A case study from Germany, Appl. Energy, 230, https://doi.org/10.1016/j.apenergy.2018.09.019, 2018.
Jung, C. and Schindler, D.: Wind speed distribution selection – A review of recent development and progress, Renew. Sustain. Energy Rev., 114, 109290, https://doi.org/10.1016/j.rser.2019.109290, 2019.
Khachatrian, E., Asemann, P., Zhou, L., Birkelund, Y., Esau, I., and Ricaud, B.: Exploring the potential of Sentinel-1 Ocean Wind Field Product for near-surface offshore wind assessment in the Norwegian Arctic, Atmosphere, 15, https://doi.org/10.3390/atmos15020146, 2024.
Kotroni, V., Lagouvardos, K., and Lykoudis, S.: High-resolution model-based wind atlas for Greece, Renewable and Sustainable Energy Reviews, 30, 479–489, 2014.
Jaramillo, O. A. and Borja, M. A.: Wind speed analysis in La Ventosa, Mexico: a bimodal probability distribution case, Renewable Energy, 29, 1613–1630, 2004.
Liu, H., Zhang, X., Yan, Z., Yang, Y., Li, Q. A., and Cai, C.: Research on representative engineering applications of anemometer towers location in complex topography wind resource assessment, Energy Engineering: Journal of the Association of Energy Engineers, 120, 163, https://doi.org/10.32604/ee.2022.019927, 2023.
Liu, Y., Zhou, L., Qin, Y., Azorin-Molina, C., Shen, C., Xu, R., and Zeng, Z.: Impacts of anemometer changes, site relocations and processing methods on wind speed trends in China, Atmos. Meas. Tech., 17, 1123–1131, https://doi.org/10.5194/amt-17-1123-2024, 2024.
Mohammadi, K., Alavi, O., Mostafaeipour, A., Goudarzi, N., and Jalilvand, M.: Assessing different parameters estimation methods of Weibull distribution to compute wind power density, Energy Convers. Manag., 108, 322–335, https://doi.org/10.1016/j.enconman.2015.11.015, 2016.
Morgan, E. C., Lackner, M., Vogel, R. M., and Baise, L. G.: Probability distributions for offshore wind speeds, Energy Conversion and Management, 52, 15–26, 2011.
Murthy, K. S. R. and Rahi, O. P.: A comprehensive review of wind resource assessment, Renewable and Sustainable Energy Reviews, 72, 1320–1342, 2017.
Ouarda, T. B. M. J. and Charron, C.: On the mixture of wind speed distribution in a Nordic region, Energy Convers. Manag., 174, 33–44, https://doi.org/10.1016/j.enconman.2018.08.007, 2018.
Pryor, S. C., Barthelmie, R. J., Bukovsky, M. S., Leung, L. R., and Sakaguchi, K.: Climate change impacts on wind power generation, Nat. Rev. Earth Environ., 1, 627–643, https://doi.org/10.1038/s43017-020-0101-7, 2020.
Pryor, S. C., Nielsen, M., Barthelmie, R. J., and Mann, J.: Can Satellite Sampling of Offshore Wind Speeds Realistically Represent Wind Speed Distributions? Part II: Quantifying Uncertainties Associated with Distribution Fitting Methods, J. Appl. Meteorol. Climatol., 43, 739–750, 2004.
Ramon, J., Lledó, L., Torralba, V., Soret, A., and Doblas-Reyes, F. J.: What global reanalysis best represents near-surface winds?, Q. J. R. Meteorol. Soc., 145, 3236–3251, https://doi.org/10.1002/qj.3616, 2019.
Soares, P. M. M., Lima, D. C. A., and Nogueira, M.: Global offshore wind energy resources using the new ERA5 reanalysis, Environ. Res. Lett., 15, https://doi.org/10.1088/1748-9326/abb10d, 2020.
Tammelin, B., Vihma, T., Atlaskin, E., Badger, J., Fortelius, C., Gregow, H., Horttanainen, M., Hyvönen, R., Kilpinen, J., Latikka, J., Ljungberg, K., Mortensen, N. G., Niemelä, S., Ruosteenoja, K., Salonen, K., Suomi, I., and Venäläinen, A.: Production of the Finnish wind atlas, Wind Energy, 16, 19–35, 2013.
Torralba, V., Doblas-Reyes, F. J., and Gonzalez-Reviriego, N.: Uncertainty in recent near-surface wind speed trends: A global reanalysis intercomparison, Environ. Res. Lett., 12, https://doi.org/10.1088/1748-9326/aa8a58, 2017.
Wang, J. W. and Sardeshmukh, P. D.: Inconsistent global kinetic energy spectra in reanalyses and models, J. Atmos. Sci., 78, 2589–2603, 2021.
Wang, J., Hu, J., and Ma, K.: Wind speed probability distribution estimation and wind energy assessment, Renew. Sustain. Energy Rev., 60, 881–899, https://doi.org/10.1016/j.rser.2016.01.057, 2016.
Wang, W., Chen, K., Bai, Y., Chen, Y., and Wang, J.: New estimation method of wind power density with three-parameter Weibull distribution: A case on Central Inner Mongolia suburbs, Wind Energy, 25, 368–386, https://doi.org/10.1002/we.2677, 2022.
Yang, X., Tao, Y., Jin, Y., Ye, B., Ye, F., Duan, W., Xu, R., and Zeng, Z.: Time resolution of wind speed data introduces errors in wind power density assessment, Energy Convers. Manag. X, 24, https://doi.org/10.1016/j.ecmx.2024.100753, 2024.
Zhou, L.: Determining the ideal length of wind speed series for wind speed distribution and resource assessment, Zenodo [code], https://doi.org/10.5281/zenodo.17945145, 2025.
Zhou, L., Zeng, Z., Azorin-Molina, C., Liu, Y., Wu, J., Wang, D., Li, D., Ziegler, A. D., and Dong, L.: A continuous decline of global seasonal wind speed range over land since 1980, J. Clim., 34, https://doi.org/10.1175/JCLI-D-21-0112.1, 2021.