the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Sep 2022
| 30 Sep 2022
Multifidelity multiobjective optimization for wake-steering strategies
Ryan N. King
Garrett Barter
Peter E. Hamlington
Wake steering is an emerging wind power plant control strategy where upstream turbines are intentionally yawed out of perpendicular alignment with the incoming wind, thereby “steering” wakes away from downstream turbines. However, trade-offs between the gains in power production and fatigue loads induced by this control strategy are the subject of continuing investigation. In this study, we present a multifidelity multiobjective optimization approach for exploring the Pareto front of trade-offs between power and loading during wake steering. A large eddy simulation is used as the high-fidelity model, where an actuator line representation is used to model wind turbine blades and a rainflow-counting algorithm is used to compute damage equivalent loads. A coarser simulation with a simpler loads model is employed as a supplementary low-fidelity model. Multifidelity Bayesian optimization is performed to iteratively learn both a surrogate of the low-fidelity model and an additive discrepancy function, which maps the low-fidelity model to the high-fidelity model. Each optimization uses the expected hypervolume improvement acquisition function, weighted by the total cost of a proposed model evaluation in the multifidelity case. The multifidelity approach is able to capture the logit function shape of the Pareto frontier at a computational cost only 30 % that of the single-fidelity approach. Additionally, we provide physical insights into the vortical structures in the wake that contribute to the Pareto front shape.
- Article
(5284 KB) - Full-text XML
- BibTeX
- EndNote





As wind energy systems have matured, plant-level control has emerged as a new paradigm, where groups of turbines are controlled in coordination to maximize collective power production. This is in contrast to more traditional control strategies, where individual turbines are controlled to maximize their own power production. A potentially promising form of such plant-level control is “wake steering”, where upstream wind turbine yaw positions are intentionally misaligned from the incoming wind, “steering” the wake away from downstream turbines. A counter-rotating pair of vortices is generated by the lateral thrust of the wind turbine rotor, which is determined by the yaw offset direction (Fleming et al., 2018; Martínez-Tossas and Branlard, 2020). This allows the performance of wind power plants to be improved by diverting wakes away from downstream turbines
It is speculated that wake steering may produce more power while inducing less total fatigue on all turbines when compared to the baseline strategy of aligning each turbine with the incoming wind (Howland et al., 2019; Hulsman et al., 2020). However, very few studies have quantified the trade-offs between power and damage. Hulsman et al. (2020) used an actuator line model to train polynomial chaos surrogates for optimization of a weighted sum of power and damage equivalent loads. Yin et al. (2020) present a multiobjective genetic algorithm for the maximization of power and minimization of total thrust. Damiani et al. (2018) performed a detailed analysis of a single wind turbine, finding that negative yaw offsets tended to increase fatigue loading more than positive yaw offsets, but cautioned that this result could not be generalized given the dependence on incident conditions. Other studies have provided additional evidence supporting the notion that positive yaw misalignment results in less edgewise loading of downstream turbine blades than the corresponding negative yaw misalignment strategy (Zalkind and Pao, 2016; López et al., 2020). Wang et al. (2020) demonstrated the potential of individual pitch control to alleviate loads induced from intentionally offsetting the turbine yaw. Van Dijk et al. (2017) used the FLORIS and CCBlade tools to examine trade-offs between power produced and the edgewise and flapwise fatigue loading induced through wake steering. Lin and Porté-Agel (2020) utilize a large eddy simulation (LES) framework to construct the Pareto set between power and flapwise bending moment loading through a comprehensive parameter sweep. While these studies all provide insights into the trade-offs between power and loading, there is still a need for an efficient optimization algorithm to quantify these trade-offs using computationally intensive simulations.
Despite its promise, plant-level control via wake steering involves complex physics and is challenging to model. Engineering wake models have dubious accuracy when predicting fatigue loading, which higher-fidelity models predict more accurately (Rinker et al., 2021). In this study, we propose a multifidelity multiobjective optimization framework to address this challenge and explore trade-offs between power and loading in wake-steering strategies. In practice, power and loading will likely be optimized in real time using a singular weighted objective. The relative weights may be decided upon by exploring trade-offs between power and loading using multiobjective optimization to estimate the Pareto frontier. When searching for the Pareto set, an efficient algorithm must balance exploration and exploitation. Several models have been developed that may be used to study the effects of control strategies with various levels of mathematical detail and real-world accuracy (i.e., fidelity) (Annoni et al., 2018; Martínez-Tossas et al., 2019; Hulsman et al., 2020).
Multifidelity optimization exploits the correlation between low- and high-fidelity models to reduce the overall computational cost of optimization. For instance, Andersson and Imsland (2020) present a real-time modifier adaptation approach for wake-steering design, where a Gaussian process (GP) is used to iteratively learn the difference between observed operational data and the predictions of an engineering wake model. Ariyarit and Kanazaki (2017) present a two-objective bifidelity approach that iteratively builds a GP discrepancy function. Huang et al. (2006) and Rajnarayan et al. (2008) employ an augmented expected improvement formulation, including three factors to account for the correlation between the low- and high-fidelity models, the observed error, and the cost ratio between the low- and high-fidelity models. It is not always clear when a proposed low-fidelity model is appropriate for use in multifidelity optimization, though it is common to assess candidate low-fidelity models by measuring their correlation with the high-fidelity model (Giselle Fernández-Godino et al., 2019).
The novelty of the present study is the application of this multifidelity technique to wind energy systems, resulting in new insights into wake-steering flow physics. The present approach uses the low-fidelity model to first explore the full parameter space and then iteratively builds the low- and high-fidelity model surrogates to gain the most improvement in the Pareto front per model evaluation costs. While this framework is similar to that presented by Ariyarit and Kanazaki (2017) and Andersson and Imsland (2020), the exact framework outlined here is new, and this is the first demonstration of any such approach in the context of wind energy systems.
A Bayesian framework for multiobjective multifidelity optimization is presented. Throughout this section, we assume that minimization of functions is the objective of the optimization procedure (as opposed to maximization).
This study employs GP models to approximate power and loading dynamics. A GP is a collection of random variables, any finite number of which have a joint Gaussian distribution (Rasmussen and Williams, 2006). The simulated power and loads, fi, are approximated using individual Gaussian process surrogate models, g, which are defined as
where γ is a vector of proposed yaw angles (with dimension equal to the number of turbines), γ′ is an arbitrary vector of yaw angles, μi(γ) is the GP mean function, is the GP kernel covariance function, and the index i refers to power (i=1) or loading (i=2) objectives.
We perform Bayesian inference on functions by conditioning the GP on a set of observed input–output pairs , where is a matrix of simulated yaw offsets, and is a vector of observations of simulated power or loading outputs. We use the scikit-learn Gaussian process implementation (Pedregosa et al., 2011), which is a well-validated open-source project. The power and loading outputs are normalized to have zero mean and unity variance during a preprocessing step. After conditioning on 𝒟i, we obtain Gaussian distributions at test locations γ* with the posterior estimates of the mean,
and variance,
where is a vector and is a matrix.
The kernel covariance function encodes prior knowledge about structural properties of the underlying signal, such as smoothness, periodicity, and stationarity. In this study, we employ an anisotropic radial basis function kernel (Rasmussen and Williams, 2006) for ki, given by
where the correlation scale, lij, is estimated by maximizing the log-marginal likelihood function (Pedregosa et al., 2011).
2.1 Single-fidelity approach
In Bayesian optimization, an acquisition function is defined to maximize a metric representing both exploration and exploitation (Shahriari et al., 2015). A popular acquisition function for single objective optimization is the expected improvement (EI), which is the expected value of an improvement function (Zhan and Xing, 2020) with respect to the predicted uncertainty of a GP. This acquisition function is employed by the efficient global optimization (EGO) algorithm (Jones et al., 1998). The improvement function, I, quantifies the improvement in the objective function for a new evaluation, as compared to the best sampled objective, and is zero if the new objective does not outperform all of the previously sampled points. This results in
where f* is the minimum sampled value and f(γ) is the function value, which is generally unknown and must be predicted by a GP.
There is a range of potential outcomes from sampling a new point, and the GP framework conveniently estimates this uncertainty. These uncertainties are used to compute the expected value of the improvement function. It is important that the improvement function contains the maximum function; otherwise, there would be no exploration of regions of larger uncertainty. Other acquisition functions available include the knowledge gradient (Ghoreishi and Allaire, 2018), expected quantile improvement (He et al., 2017; Picheny et al., 2013), improved expected improvement (Qin et al., 2017), entropy search (Hennig and Schuler, 2012), and minimization of the predictor (Andersson and Imsland, 2020).
The expected improvement may be extended to a multiobjective context. This is done by introducing a hypervolume function, H, which measures the volume of a given Pareto front, A, using a reference point, r. The expected hypervolume improvement (EHVI), introduced by Emmerich et al. (2006), is the multiobjective counterpart to the expected improvement acquisition function used in the EGO algorithm and is given by
Here, 𝔼g(γ)[⋅] represents the expectation with respect to a normal distribution, g(γ), and is expressed as
where μ1 and σ1 are the mean and standard deviation, respectively, of the powers modeled by g1, and μ2 and σ2 are the mean and standard deviation, respectively, of loads modeled by g2. The hypervolume improvement indicator (HVI) function is the multiobjective counterpart to the improvement indicator function. It is given as
where A is an estimated Pareto frontier; is a new Pareto set that potentially includes [P,L]; and H is a hypervolume function, which measures the volume spanned by the Pareto set of objective functions relative to a reference point, r, which must not be dominated by . The Pareto frontier is defined as the set of all function values that are not strictly dominated by other function values. The formal definition is
where Ωγ is the set of allowable yaw offsets, ≺ denotes Pareto dominance (that is, if , then for all values of i and for at least one value of i; Voorneveld, 2003), and ∅ is the empty set.
The hypervolume, H, measures the extent of the Pareto set as the volume of the Pareto-dominated space bounded by a reference point, r, namely,
In practice, the Pareto set is computed by filtering a set of discrete inputs so that only non-dominated points remain,
where Y is a matrix of observed function values. This filters out observed samples that are Pareto dominated by other observed samples.
Although these ideas may also be extended to more objectives, assuming two objectives simplifies the problem, in this case, the observed Pareto set is defined as ) such that . The hypervolume is estimated using rectangular quadrature as
where n is the number of points in the given Pareto set and r1 and r2 are the components of the reference point. In this study, the EHVI is approximated through Monte Carlo simulation by
where Ns is the number of Monte Carlo samples and {𝒩[μ(γ),σ(γ)]}(k) is draw k from the GP model of power and loading, g.
Once the EHVI is estimated, it must be maximized. This is not necessarily trivial, as the EHVI computation is complicated and difficult to vectorize, and the cost of the optimization grows exponentially with the number of design variables. The EHVI optimum may be determined using a grid search, random sampling, direct optimization, or surrogate-based optimization. While a grid search is the most comprehensive option, the latter approaches are more computationally efficient for high-dimensional design inputs.
2.2 Multifidelity approach
The multifidelity approach introduces computationally cheaper but lower fidelity representations of the high-fidelity model, which allow for greater control between exploration and exploitation in the Bayesian optimization. Samples of the low-fidelity model are adaptively refined throughout the optimization as a cheap means for exploration of the high-fidelity function space. Throughout this section, we assume a known hierarchy of model fidelities, , where is the lowest-fidelity model of power/loading, N is the number of different fidelity models, and is the highest-fidelity model of power/loading. When a model is evaluated at a point, γ, we assume that all lower-fidelity models will also be evaluated at this point.
The lowest-fidelity model, , is approximated using a GP, , resulting in the following output distribution:
where and are the mean and standard deviations, respectively, associated with the lowest-fidelity power/loading model. Higher-fidelity models, , are approximated using additive discrepancy functions that map the next lowest fidelity function, , to :
where is the discrepancy function associated with objective k and fidelity i,
where and are the mean and standard deviations, respectively, modeled by the discrepancy function GP associated with fidelity i.
New GPs are defined to extend the EHVI to a multifidelity context. No matter which fidelity is to be sampled next, the ultimate goal is to minimize the highest fidelity functions, so each GP is constructed to predict the high-fidelity outputs. However, GPs associated with lower-fidelity models should not take into account uncertainties associated with higher-fidelity models, as these uncertainties will not be collapsed if the lower-fidelity model is sampled. Sampling the highest-fidelity model must take all sources of surrogate uncertainty into account, as a high-fidelity model evaluation will be associated with sampling all lower-fidelity models at the same point. So, new GP models, hi, are constructed to predict the high-fidelity output while encoding different uncertainty information. The GPs associated with each fidelity are defined as
Putting the above formulations together, it is natural to define a multifidelity multiobjective acquisition function as the ratio of EHVI per evaluation cost:
where J is the optimization acquisition function, which is a function of a set of proposed yaw offsets and model fidelity, to be minimized with respect to yaw offsets, γ, and model fidelity, i, in each optimization iteration, and Ci is the computational cost associated with model i.
In this study, we examine the bifidelity case (N=2), where
and
The bifidelity workflow is visualized in Fig. 1. The EHVIs associated with the low-fidelity (h1) and high-fidelity (h2) GP models are maximized. Then, the EHVI per cost is maximized with respect to fidelity in the comparative step, which corresponds to minimizing J(γ,i). If the EHVI per cost associated with evaluating the low-fidelity model is greater than the EHVI per cost associated with evaluating the high-fidelity model, the low-fidelity model is evaluated. Otherwise, the high-fidelity model is evaluated. In the figure, h1 is represented by GPLF, h2 is represented by GPHF, C1 is represented by CLF, and C2 is represented by CHF.
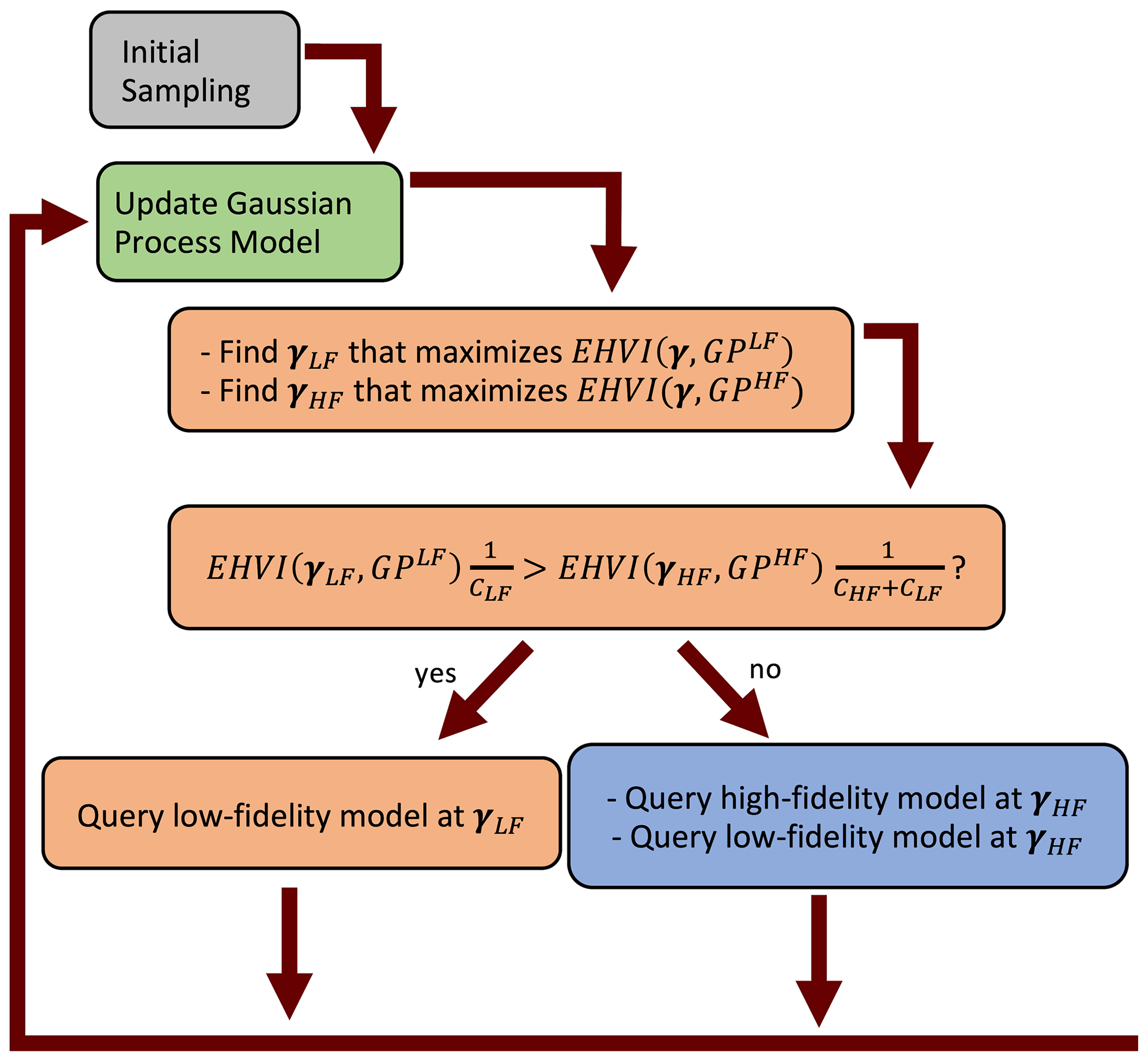
Figure 1Workflow visualization for the bifidelity optimization case. h1 is represented by GPLF, h2 is represented by GPHF, C1 is represented by CLF, and C2 is represented by CHF.
This section outlines the numerical approaches used in this study. Section 3.1 presents the flow modeling framework employed. Section 3.2 introduces the specific power and loading objective functions used in this study. Section 3.3 presents the approach used to maximize the multiobjective acquisition function. Section 3.3.1 outlines the sampling approach, and Sect. 3.3.2 presents a correlation analysis used to determine the low-fidelity loading proxy.
3.1 Flow modeling
We use the WindSE framework (National Renewable Energy Laboratory, 2021) to model flow within the wind power plant. We investigate a two-turbine case, with a single wind direction and speed, where the turbines are spaced seven rotor diameters apart and the wind direction is such that the front turbine directly wakes the back turbine. The large turbine spacing was chosen to ensure that solutions associated with optimal power production were inside of the boundaries of allowable yaw offsets. When turbines are spaced tightly, it is common for the optimal power to be associated with the largest allowable yaw offset of the front turbine, which is a less challenging optimization case. The inflow boundary is modeled using a logarithmic profile with a hub height wind speed of 7.5 m s−1. The top, side, and outflow boundaries are specified as no-stress boundaries, and the ground is specified as a no-slip boundary. We consider turbine representations of the IEA 3.4 MW reference turbine (Bortolotti et al., 2019), with hub heights of 120 m and rotor diameters of 130 m. The turbine blades are represented as actuator lines with 15 force nodes. This analysis does not consider the turbine nacelle or tower, and the turbine blades are modeled as being rigid. There is no turbine controller, and the rotor speed and blade pitch angles are modeled as constants. The domain is represented with a m3 mesh, corresponding to a 301 s flow-through time. The mesh is refined near the center of the domain and where the turbines are located. A target Courant–Friedrichs–Lewy condition of 0.98 is specified. All simulations were initiated with the same atmospheric conditions.
The simulations solve the filtered conservation of mass and Navier–Stokes equations given by
where is the material derivative, is the velocity, t is time, x is the spatial location, ∇ is the spatial gradient, ρ is the density, is the pressure, μ is the dynamic viscosity, νt is the turbulent viscosity, and ℱ is the turbine forcing. The density is specified as ρ=1 kg m−3, and the dynamic viscosity is specified as kg m−1 s−1. The turbulent viscosity, νt, is modeled using the Smagorinsky–Lilly LES model as
where Cs=0.17, Δ is the grid cell size, and S is the strain rate tensor given by
and .
The turbine forcing is computed as
where Nnodes is the number of actuator nodes per blade; ϵ is the characteristic width of the actuator forces (specified as 2 m in this study); dkbj(x) is the distance from node j associated with blade b and turbine k; and fkbj(x) is the actuator force on node j associated with blade b and turbine k, which is computed based on the wind speed, angle of attack, and the reference airfoil lift and drag coefficients, as well as a tip loss correction, as described by Allen et al. (2022).
Low- and high-fidelity models were developed for this study using the WindSE framework. A Cartesian discretization of the computation domain is specified, where the grid is refined twice in the wake region as well as near the turbine rotors. Each high-fidelity simulation is run to 1200 s using Taylor–Hood elements (Ern and Guermond, 2004). The power and loading results only use information from the final 600 s of simulation time. These time parameters were justified by comparing power and loading computed over time intervals of 600–900 and 900–1200 s, resulting in relative differences of only 2.6 % for power and 4.2 % for loading when . These time parameters were chosen to obtain a reasonably efficient optimization problem for the present demonstration, accepting the possibility that the optimization results could be slightly different if different time parameters were chosen. For example, using a time interval from 1200 to 1800 s, instead of the present 600–1200 s, resulted in changes to the hypervolumes of the Pareto fronts discovered by the single-fidelity and multifidelity optimizations of less than 0.5 %. The low-fidelity model was selected using the same grid as the high-fidelity model but runs to 400 simulation seconds and uses piecewise linear elements. The power is averaged after 300 s and the loading is estimated using the front and back turbine moments past 300 s. This cut-in time and the total low-fidelity model simulation time were selected to avoid initial transient effects while minimizing the computational cost of the low-fidelity simulation. Using eight processors, the high-fidelity model was measured to take 5.4 h to run, and the low-fidelity model was measured to take 0.24 h to run. This corresponds to a cost ratio of approximately 0.05. The flow fields produced by the low- and high-fidelity models are compared in Fig. 2.
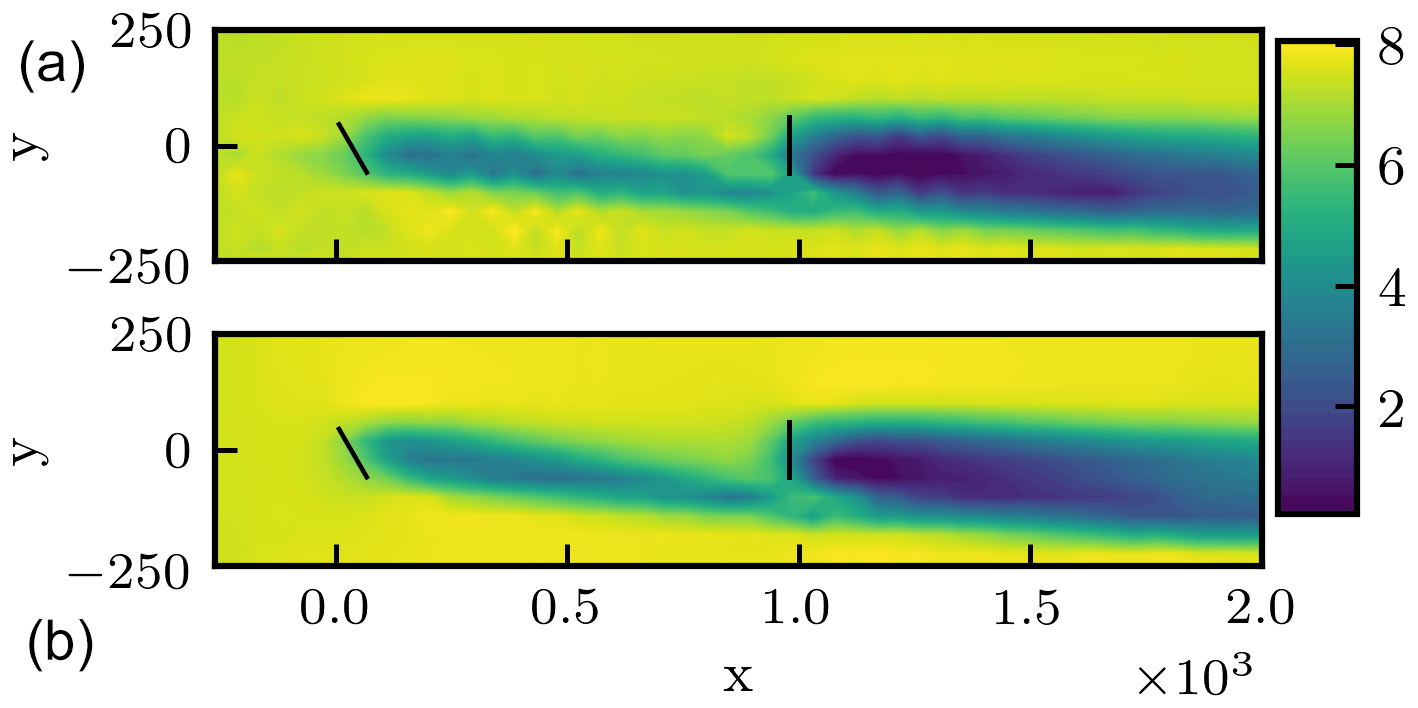
Figure 2Time-averaged velocity magnitude fields at the turbine hub height associated with the low- and high-fidelity models. Panel (a) shows the flow field associated with the low-fidelity model, and panel (b) shows the flow field associated with the high-fidelity model. In both cases, the front turbine is offset by 30∘, and the back turbine has no yaw offset. Brighter colors correspond to faster velocity magnitudes. Turbine positions are shown with dark lines.
3.2 Objective functions
The objective of the optimization is to minimize negative power, −P, and loading, L, with respect to each turbine yaw offset such that the yaw offset angles, γ, are bounded between −30 and 30∘.
Power and loading are quantified using the actuator line model results, discarding an initial transient period. Power is computed as the average total power after the initial transient period. While there are several ways to quantify loading, this study provides a demonstration of the optimization framework by summarizing the time history of the flapwise bending moment of one blade in the front and back turbines after the same initial transient period. Using the high-fidelity model, loading is computed as the sum of damage equivalent loads (DELs) (International Electro-technical Commission, 2015) associated with the front and back turbine flapwise bending moments. The power and flapwise bending moment are computed from the actuator force as
and
where 𝒫k(t) is the power associated with turbine k, Mk(t) is the flapwise bending moment associated with turbine k, ω is the angular speed of the rotor (which is a constant 11.6 rotations per minute in this study), rj is the radial location associated with node j, is the unit vector orientated outward from the rotor plane associated with turbine k, and is the unit vector oriented in the direction of rotation of turbine k.
The average power production of each turbine is computed as
where 𝒫k,avg is the average power associated with turbine k, t0 is the initial time considered, and tf is the final time of the data set. The total power, measured in megawatts, is computed as the sum of the powers produced by each wind turbine,
Each DEL is computed using the rainflow-counting algorithm as
where i loops through each cycle found using the rainflow-counting algorithm, Ri is a load range, ci is the number of cycles associated with the ith range bin of the moment load spectrum, Δt is the time elapsed in seconds, and m is the Wöhler exponent. In this study, m is set as 10, and Ri and ci are computed using the fatpack Python package (Frøseth and Capponi, 2021), utilizing 100 loading bins. The loading objective is computed as the sum of the flapwise bending moment DELs associated with the front and back turbines as
The loading objective, L, is normalized to be negative and on a similar scale to power, as
where is the load prior to normalization, which is computed in newton meters. This normalization was chosen to ensure that power and loading are of similar scale and that both are negative. Because the EHVI is an area produced by the two objectives, we do not expect different values in this scaling function to affect the results of maximizing the acquisition function, provided that all sampled objective values are always less than the associated reference value.
3.3 Optimization implementation
Here we use a simple optimization approach for simplicity of demonstration. In each iteration, the l correlation scale parameter in Eq. (4) is selected based on the maximum likelihood function (Pedregosa et al., 2011), with a lower bound of 5∘ and an upper bound of 30∘. The reference point, r, in Eq. (12) is specified as . In our formulation, we minimize J(γ,l) using a grid-based search for the maximum value. The grid is evenly spaced with 31 inputs per yaw offset dimension. Individual grids are considered for all values of l. The EHVI is computed using Monte Carlo sampling with 1200 samples taken from the GP. The EHVI may also be computed through numerical quadrature (Emmerich et al., 2011; Hupkens et al., 2015). When dealing with inputs of larger dimension, the EHVI may be maximized using an optimization algorithm, such as a genetic algorithm or the EGO approach. After the optimization, the Pareto set was refined using B-spline interpolation in SciPy (Virtanen et al., 2020).
3.3.1 Initial sampling
Initial sampling points are selected using a heuristic approach, where an assumed kernel is used to progressively minimize the standard deviation of the predictor. The simplest approach to initializing the optimization procedure is to randomly sample the low-fidelity and discrepancy functions. Random initial sampling may affect the optimization results, so a deterministic and symmetric sampling strategy is used as a test case. An isotropic kernel is used with a correlation scale of 10∘. The GP model is initialized with the point . A 100×100 grid of inputs ranging between −30 and 30∘ degrees is used to find the next point that minimizes uncertainty in the predicted variance. This process was repeated iteratively to generate 100 points. These points were used to naively estimate the optimal power and loading and Pareto hypervolume as a reference. The first 5 points were used as the initial high-fidelity samples, and the first 20 points were used as the initial low-fidelity samples. This heuristic sampling approach is also used to generate 100 samples for use in a correlation analysis and as a naive, baseline approach to searching for the Pareto set.
3.3.2 Low-fidelity loading model
We considered several different low-fidelity model forms for loading and selected the one with the highest correlation to the high-fidelity model, as that is known to result in the best multifidelity performance. We used 100 samples obtained using the heuristic sampling method described in Sect. 3.3.1 to test the correlation. In practice, this correlation test would not be part of the optimization procedure, and reasonably accurate models would be identified based on past experience and/or expert opinion. The correlation analysis revealed a correlation of 0.976 between the low- and high-fidelity power predictions. Using the DEL as the load proxy in the low-fidelity model yielded a low correlation between the low- and high-fidelity models. We explored other potential loading proxies – applying the proxy to both the front and back turbine moment histories and then summing the results – and the results of each correlation analysis are presented in Table 1. We used the proxy associated with the highest-measured correlation, namely
where μt and σt are the mean and standard deviation, respectively, with respect to time. The DEL is purposely replaced with lower-order moment functions to avoid the influence of the spurious oscillations caused by the low-fidelity loading model. The DEL is essentially a high-order moment, which is especially susceptible to these oscillations. The lower-order moments in Eq. (33) were less susceptible to the spurious oscillations, which is why larger correlations are observed.
Table 1Correlations observed between high-fidelity DEL and different loading proxies of the low-fidelity model using 100 heuristic samples.

4.1 Pareto set computation
The convergence of the single-fidelity and multifidelity optimization approaches is compared in Fig. 3. The dashed lines show the hypervolume, best-sampled load, and best-sampled power found from 100 sampled points using the heuristic sampling approach, which the single-fidelity and multifidelity approaches both outperformed. The EHVI associated with the multifidelity approach was generally lower than the EHVI associated with the single-fidelity approach. The multifidelity approach took less than a third as much total time to estimate the optimal power and loading compared to the single-fidelity approach. The optimal power is achieved with 26∘ offset in the front turbine and 2∘ offset in the back turbine. The optimal loading is achieved with 22∘ offset in the front turbine and −30∘ offset in the back turbine. We also performed several shorter optimizations as part of the development process using random initial samples, confirming that the multifidelity approach consistently determined the correct hypervolume in fewer iterations than the single-fidelity approach.

Figure 3Convergence history of the single-fidelity and multifidelity approaches. The left plots show the EHVI, hypervolume, and best-observed power and loading. The right plots show the yaw configurations associated with the best-observed power and loading.
Figure 4 compares the Pareto sets found using 50 equivalent high-fidelity evaluations using the single-fidelity and multifidelity approaches. The multifidelity approach captures five Pareto points, and the single-fidelity approach captures four Pareto points. The estimated Pareto sets are very similar, although the single-fidelity approach captures more of the Pareto set close to the optimal power and the multifidelity approach captures more of the Pareto set close to the optimal loading. The results of the single-fidelity and multifidelity approaches are combined to show a single Pareto set, which has a shape similar to a logit function.
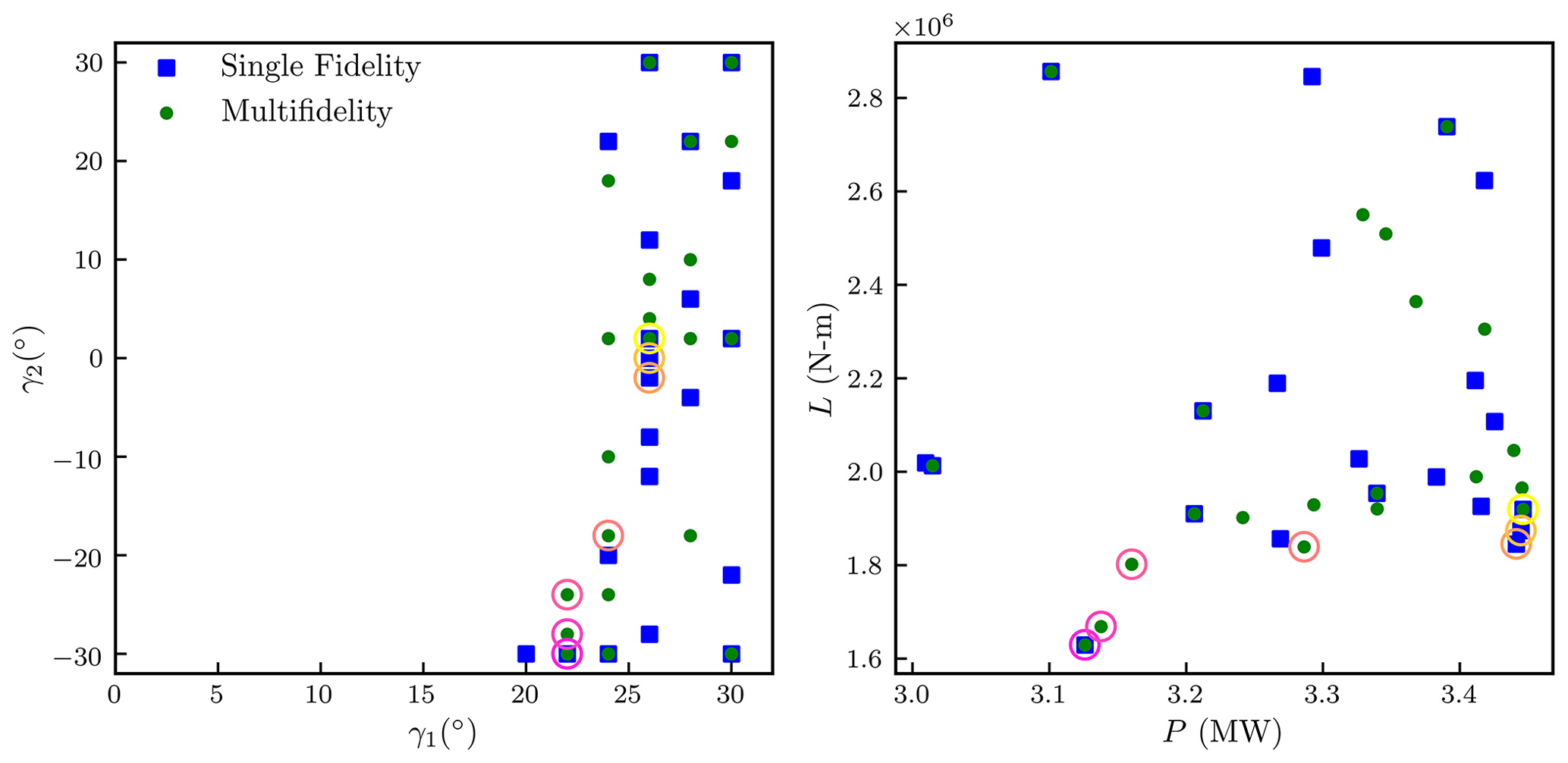
Figure 4Sampled inputs and outputs associated with power greater than 3 MW and loads less than 3 MN m. Points associated with the single-fidelity approach are shown using blue square markers, and points associated with the multifidelity approach are shown using green circular markers. A Pareto set constructed from the single-fidelity and multifidelity results is highlighted with hollow circles, where darker (magenta) circles correspond to Pareto points with lower loads and lower powers.
Although the primary goal of the present study is to develop and demonstrate a multifidelity multiobjective optimization framework, once several of the points in the Pareto set are identified the set can be further refined using a grid search. As a demonstration of this additional step, the Pareto set resulting from the combination of the single-fidelity and multifidelity approaches was interpolated to create refinement samples using B-spline interpolation (Virtanen et al., 2020) with 10 interpolation points. To pick up more of the Pareto set, this interpolation was offset in the γ1 direction by −2∘, −1∘, 1∘, and 2∘ when creating the input refinement set.
The Pareto set resulting from these additional refinement samples is visualized in Fig. 5. The resulting Pareto set has three more points than the Pareto set found combining the single-fidelity and multifidelity approaches. The optimization algorithm did not originally fill in these points because they reside in a relatively flat portion of the Pareto set (i.e., is small), where adding points would not be expected to increase the Pareto set hypervolume based on the rectangular quadrature employed in this study. Adding these points increased the hypervolume of the discovered Pareto set by a very small amount, on the order of 0.002 %. Even when using such a refined set of inputs, there are several points where the Pareto set jumps from one yaw position to another; attention would be needed for an operator to control the turbines to operate along the Pareto set.
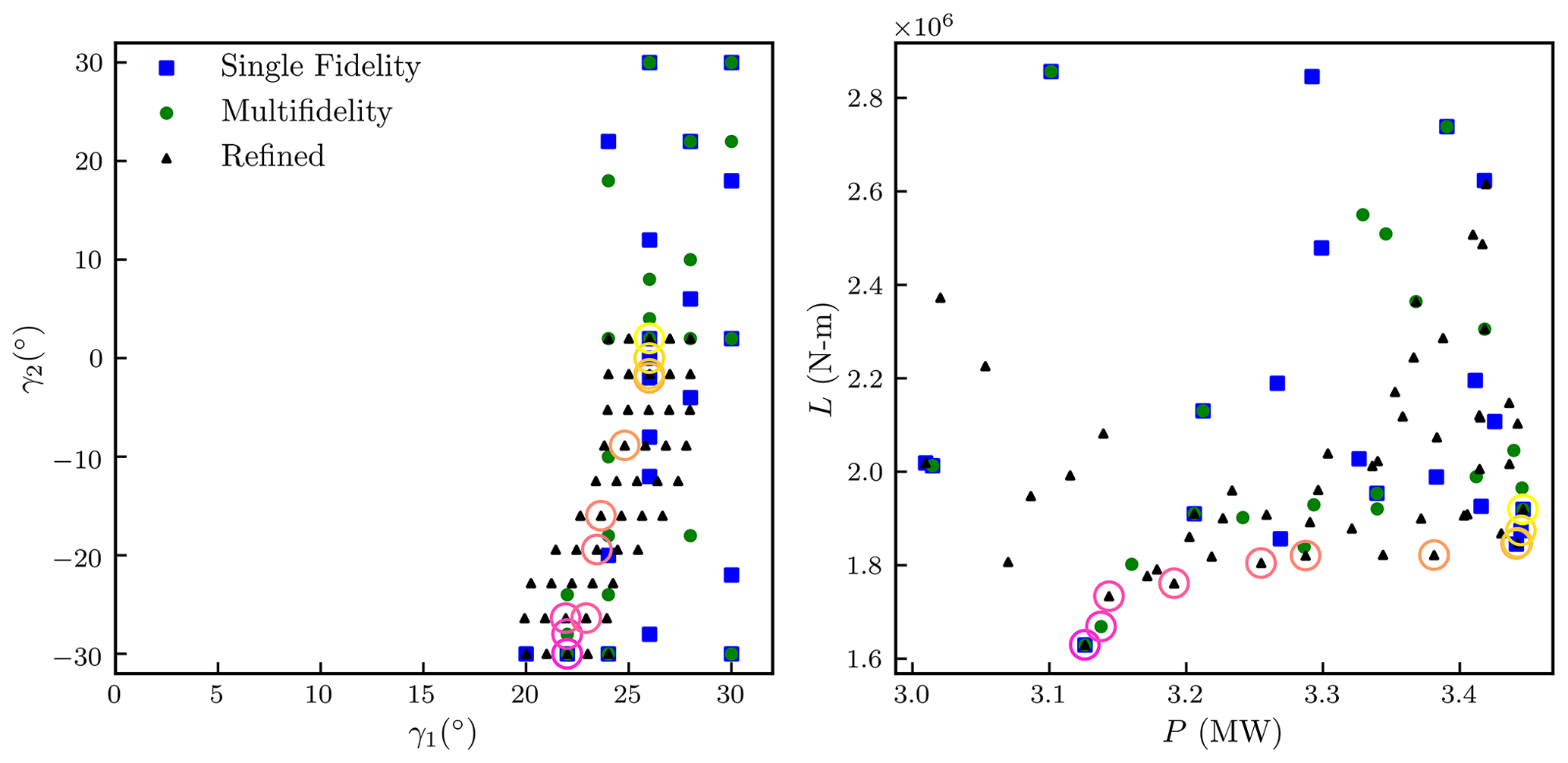
Figure 5Sampled inputs and outputs associated with power greater than 3 MW and loads less than 3 MN m. Points associated with the single-fidelity approach are shown using blue square markers, and points associated with the multifidelity approach are shown using green circular markers. Refinement points are shown as black triangles. A Pareto set constructed from the single-fidelity, multifidelity, and refinement samples is highlighted with hollow circles, where darker (magenta) circles correspond to Pareto points with lower loads and lower powers.
The multifidelity approach was successful in quantifying the trade-offs between loading and power and was shown to be more efficient than its single-fidelity counterpart. From the presented results, we find that loading may be reduced by 4 % while only reducing the optimal power by 0.3 %. The accuracy of the single-fidelity and multifidelity GP models is quantified using a leave-one-out analysis in the Appendix A. Table 2 shows the power and front and back turbine DELs associated with several strategies. Slight adjustments to the back turbine angle result in substantial differences in the back turbine loading. These small changes in yaw position adjust the turbine thrust away from the flow, reducing the total thrust imparted on the back turbine.
Table 2Observed power and loads for various yaw configurations.

4.2 Flow physics insights
Figure 6 shows the flow fields associated with neutral, −30∘, and +30∘ yaw offsets in the front turbine, with the back turbine aligned with the wind direction. When the front turbine is offset, two structures are produced: a pair of counter-rotating vortices and a coherent structure that is drawn from the boundary layer. The direction of vortex rotation is determined by the direction of thrust the turbine imparts on the incoming air. Induced vortices generally rotate in the opposite direction from the blades that generated them, and the location of the vortices is determined by their rotational direction and the direction of blade rotation. The upper vortex associated with the positive yaw offset is lower in elevation than the upper vortex produced by the negative yaw offset. The upper vortex also drifts less in the cross-flow direction when using the positive yaw offset than when using a negative yaw offset. The bottom vortex drifts similarly in both the positive and negative offset cases. All this amounts to a larger and more extreme velocity deficit encroaching on the back turbine when using the negative yaw offset, rather than the positive yaw offset, resulting in more loading and less power.
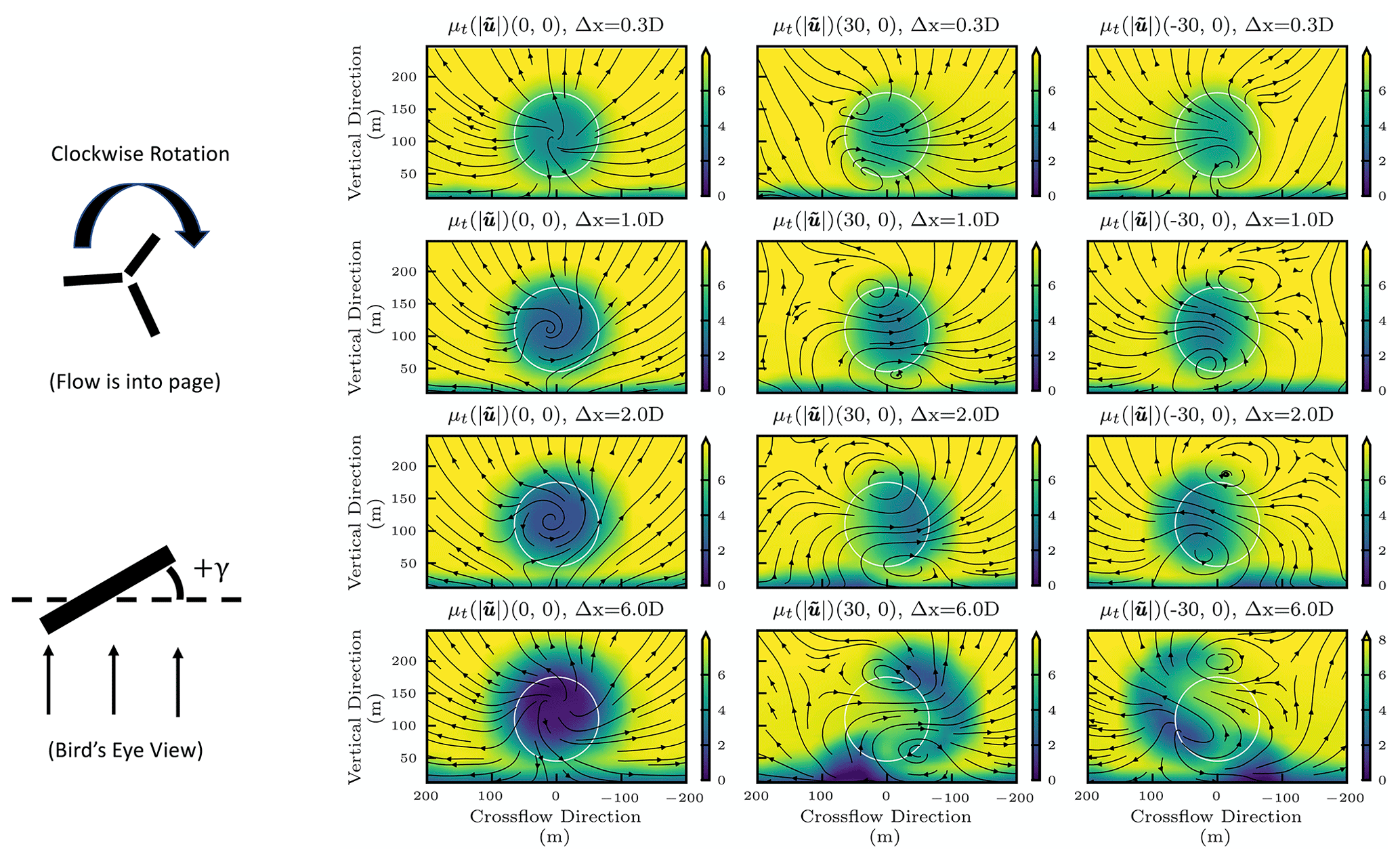
Figure 6Flow fields associated with the extreme and neutral offsets in the front turbine, viewed from upstream. The Δx term indicates the distance downstream from the front turbine in terms of rotor diameters. Brighter colors show faster velocities. Streamlines show the direction of the cross-flow and vertical velocity components. In each plot, the vertical and cross-flow location of the back turbine is shown as a white circle. The turbines rotate clockwise when viewed from upstream. A diagram is shown on the left depicting the direction of positive yaw offset when viewing the turbine from above.
Time-averaged flow fields associated with the optimal power, , and optimal loading, , solutions are compared in Fig. 7, which shows vertical slices of the flow field before the flow reaches the back turbine. The lesser front turbine yaw offset angle in the case results in less lateral movement of the wake, and the wake structure has greater overlap with the back turbine than in the case. The stronger vortical motion resulting from the case results in the boundary layer being convected further inwards. This boundary layer structure also impacts the back turbine less in the case because of the reduced back turbine projected area. As the wake convects past the back turbine, additional vorticity is added to the flow. In the case, the boundary layer structure appears to be pushed back down by the rotation of the bottom vortex.

Figure 7Time-averaged flow fields associated with the optimal power (left) and loading (right) found by the optimization, viewed from upstream, six rotor diameters away from the front turbine and one rotor diameter upstream of the downstream turbine. Brighter colors indicate faster velocity magnitudes. In each plot, the vertical location and cross-flow location of the back turbine are shown as a white ellipse.
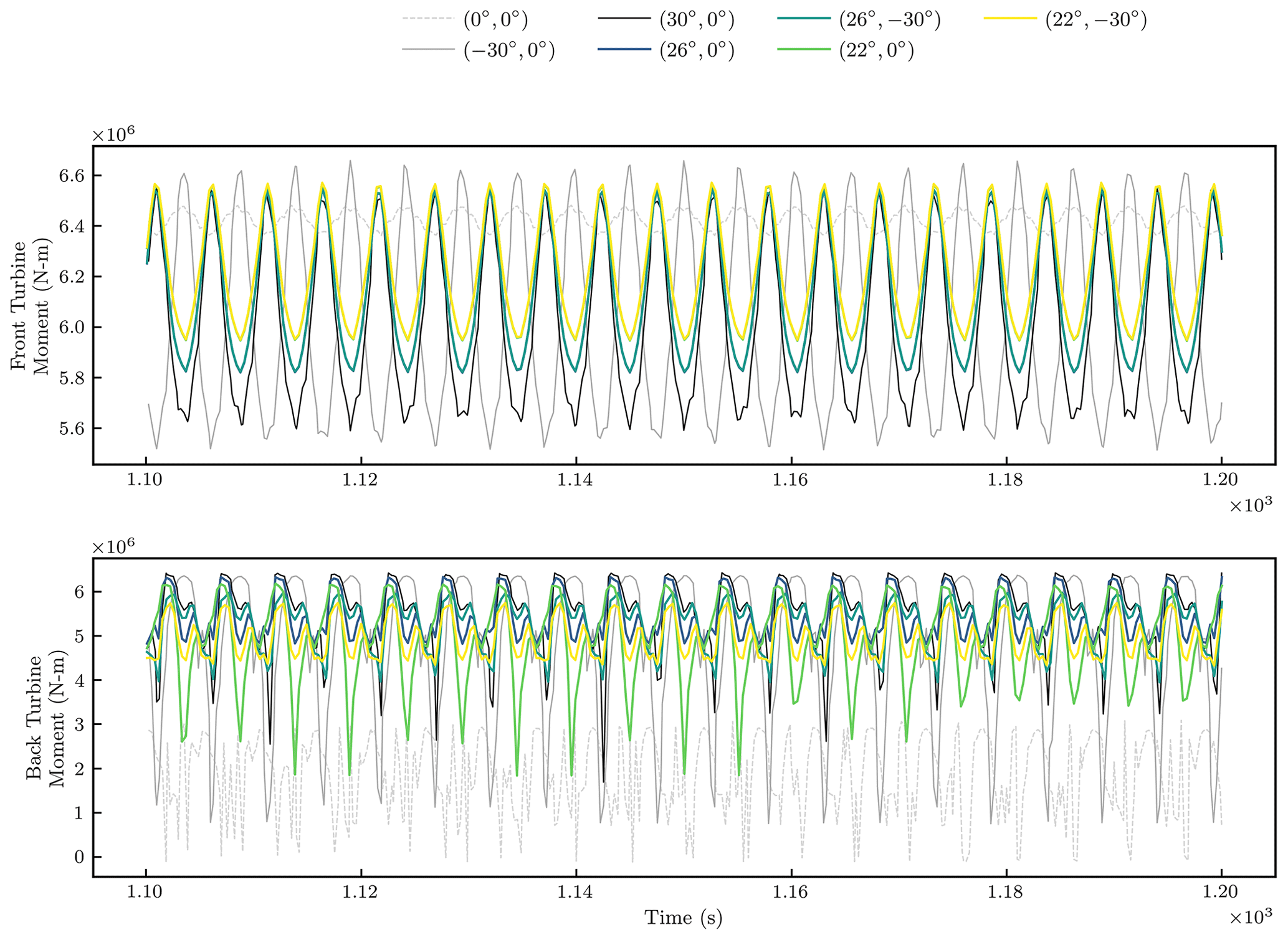
Figure 8 shows time histories of the flapwise bending moment associated with the front and back turbines for various wake-steering strategies. The spikes in the back turbine loading history are caused by the wake impacting the back turbine. When , the back turbine shows greater downward spikes in loading than when , because of the greater velocity deficit discussed above. The case yields smaller downward spikes associated with the back turbine loading than when , because the strength of the counter-rotating vortices is such that the structure convected from the boundary layer does not impact the back turbine as adversely. The offset case has larger downward spikes in the back turbine loading than the offset case, because the latter steers the wake further away from the back turbine. When the back turbine is offset to −30∘, the back turbine thrust and associated moments are generally reduced. With this extreme back turbine yaw offset, there is less variation in the back turbine loading when the front turbine is offset by 22∘ than when it is offset by 26∘, because the former case results in greater variation of velocity across the back turbine rotor plane. These results are specific to the specified spacing between turbines and atmospheric conditions.
This paper has demonstrated a multifidelity multiobjective optimization approach for wake-steering strategies. Actuator line simulations were carried out using the WindSE tool and using a coarser simulation as the low-fidelity model. The high-fidelity loading was characterized as the sum of flapwise bending moment DELs on blades on the front and back turbines. Due to oscillations in the low-fidelity simulations, characterizing the low-fidelity loading with a DEL resulted in a relatively low correlation between the low- and high-fidelity loading predictions, so a different low-fidelity surrogate was developed with a higher correlation.
The multifidelity multiobjective optimization approach was effective in exploring the trade-offs between loading and power when developing a wake-steering design. Convergence was achieved in the multifidelity optimization case after approximately 30 % as many equivalent high-fidelity model evaluations as in the single-fidelity case. Future work should apply this approach and a low-fidelity loading function to more complex wind plant layouts to confirm their effectiveness. Exploring the solutions in the final Pareto sets guided insights into the fundamental flow physics. Given the specified turbine spacing and atmospheric conditions, a positive front turbine yaw offset is more effective at reducing loading and increasing power than a negative yaw offset because the counter-rotating vortices associated with the negative front turbine yaw offset produce a greater velocity deficit in the downstream wake. The boundary layer is convected by the counter-rotating vortices, adversely affecting loading, and this may be avoided using less-extreme front turbine yaw offsets. Slightly modifying the back turbine yaw offset reduced loading by 4 % and only reduced power by 0.3 %. Greater offsets in the back turbine also led to less overall loading, with significantly less power generation.
It is well known that yaw position errors can adversely affect the performance of wake-steering strategies. This is especially true when it comes to turbine loading. A 30∘ yaw offset is already an aggressive strategy, and unfavorable yaw position errors may result in even more aggressive yaw offsets in practice. Yaw offset errors are generally extreme in lower wind speeds, which is when wake-steering strategies are most efficient at increasing power. Previous work has examined the potential of considering yaw error uncertainties in the wake-steering optimization problem (Quick et al., 2017, 2020). The multifidelity optimization approach presented in this paper could conceivably be extended to optimization under uncertainty, using the final GP models to propagate yaw position uncertainty, and potentially even modifying the EHVI definition to include uncertainty information. Incorporating uncertainty will likely change the shape of the discovered Pareto front.
A drawback of the presented approach is that it requires sequential high-fidelity model evaluations. In practice, it is often feasible to evaluate a high-fidelity model several times in parallel, and the greatest expense is the time needed to run the optimization. This framework may be extended to allow for parallel function evaluations. A simple approach is to use predictions of the GP as stand-ins for future model evaluations, iteratively using these points to construct the next iteration of the GP and the associated EHVI (Ginsbourger et al., 2010). Yang et al. (2019) propose dividing the input space into separate regions for parallelization of EHVI optimization. Another intuitive approach could be to include refinement points during each iteration. Refinement points could be selected using the Pareto set predicted by the GP models or interpolated along the observed Pareto set. Care should also be taken when applying this method to ensure convergence of the Pareto set with respect to convergence of the underlying simulation.
In future work, this framework can be applied to a larger array of turbines using more realistic control strategies with different turbine spacings and atmospheric conditions. While considering more turbines presents additional complications in maximizing the EHVI, we anticipate there will be even greater cost savings from the multifidelity approach as the number of turbines increases. Additionally, the framework can be extended to allow for optimization under uncertainty, as it is not realistic to assume perfect control of wind turbine yaw positions. Finally, the framework can incorporate more lower-fidelity models and be combined with layout optimization to realize the full benefits of multifidelity multiobjective wake-steering optimization.
A leave-one-out analysis was performed to assess the accuracy of the single-fidelity and multifidelity GP models. For each point considered, the model was trained using the remaining points available, excluding the point of interest. Then, the accuracy of the prediction was quantified by comparing it to the observed value. The single-fidelity and multifidelity approaches were analyzed using the data associated with the optimization case study. When assessing the accuracy of the multifidelity model, the low- and high-fidelity samples associated with each point considered in the leave-one-out analysis were removed. Figure A1 shows results of the leave-one-out analysis associated with the single-fidelity GP. Figure A2 shows the results of the leave-one-out analysis associated with the multifidelity GP.
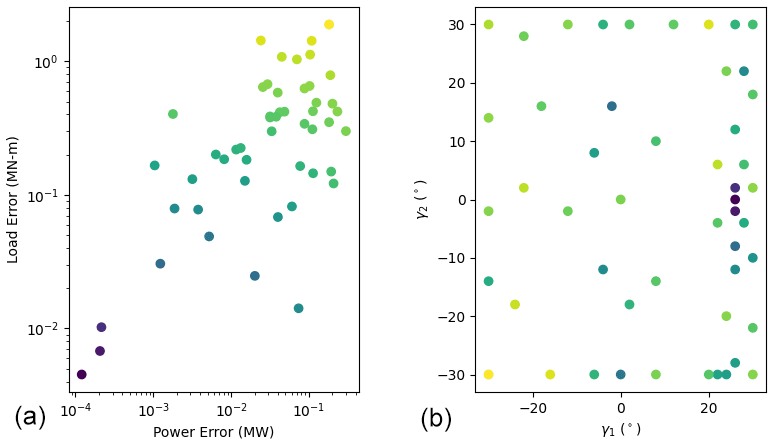
Figure A1Results of the single-fidelity leave-one-out analysis. Panel (a) shows the leave-one-out prediction errors associated with power and loading, and the points are colored by the sum of both errors. The same points are plotted in panel (b), showing their associated γ1 and γ2 values.
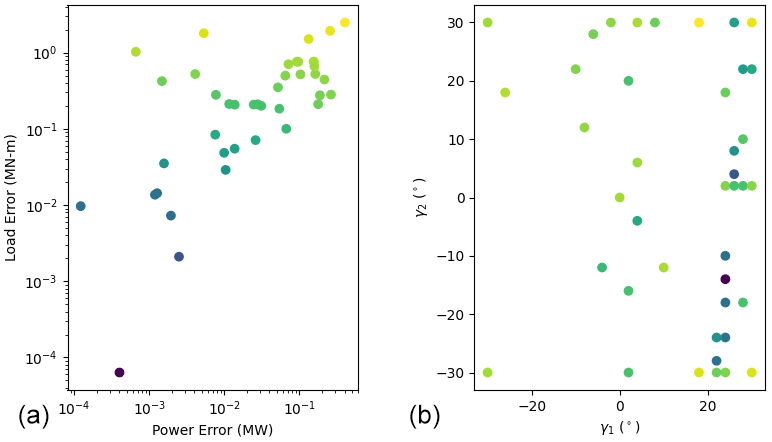
Figure A2Results of the multifidelity leave-one-out analysis. Panel (a) shows the leave-one-out prediction errors associated with power and loading, and the points are colored by the sum of both errors. The same points are plotted in panel (b), showing their associated γ1 and γ2 values.
Based on these results, both GPs served as reasonably accurate surrogates. Many of the sampled errors are less than 0.1 MW and 0.1 MN m, particularly in the region of the discovered Pareto set, which correspond to 3 % of the maximum power and 6 % of the minimum loading, respectively. The multifidelity approach yielded higher maximum errors and lower minimum errors than the single-fidelity approach. This analysis focused on the final results of the optimization, and we generally expect the leave-one-out errors to shrink as the optimization progresses.
This study employed the WindSE software, commit hash f217bd0986325d86ee0ffac083a71fd4ead91b63. The repository is available at https://github.com/NREL/WindSE (last access: 19 September 2022; National Renewable Energy Laboratory, 2021).
The data set associated with our analysis can be accessed at https://doi.org/10.5281/zenodo.7097352 (Quick, 2022).
GB, PEH, RNK, and JQ designed the experiments. RNK, GB, and JQ developed the problem formulation. JQ and PEH performed the simulations. JQ, RNK, and PEH prepared the manuscript with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was authored in part by the National Renewable Energy Laboratory, operated by Alliance for Sustainable Energy, LLC, for the U.S. Department of Energy (DOE) under contract no. DE-AC36-08GO28308. Funding was provided by the U.S. Department of Energy Wind Energy Technologies Office. The views expressed in the article do not necessarily represent the views of the DOE or the U.S. Government. The U.S. Government retains and the publisher, by accepting the article for publication, acknowledges that the U.S. Government retains a nonexclusive, paid-up, irrevocable, worldwide license to publish or reproduce the published form of this work, or allow others to do so, for U.S. Government purposes. This research was performed using computational resources sponsored by the Department of Energy's Office of Energy Efficiency and Renewable Energy and located at the National Renewable Energy Laboratory.
This research has been supported by the U.S. Department of Energy (grant no. DE-AC36-08GO28308).
This paper was edited by Johan Meyers and reviewed by Ishaan Sood and one anonymous referee.
Allen, J., Young, E., Bortolotti, P., King, R., and Barter, G.: Blade planform design optimization to enhance turbine wake control, Wind Energy, 25, 811–830, https://doi.org/10.1002/we.2699, 2022. a
Andersson, L. E. and Imsland, L.: Real-time optimization of wind farms using modifier adaptation and machine learning, Wind Energ. Sci., 5, 885–896, https://doi.org/10.5194/wes-5-885-2020, 2020. a, b, c
Annoni, J., Fleming, P., Scholbrock, A., Roadman, J., Dana, S., Adcock, C., Porte-Agel, F., Raach, S., Haizmann, F., and Schlipf, D.: Analysis of control-oriented wake modeling tools using lidar field results, Wind Energ. Sci., 3, 819–831, https://doi.org/10.5194/wes-3-819-2018, 2018. a
Ariyarit, A. and Kanazaki, M.: Multi-Fidelity Multi-Objective Efficient Global Optimization Applied to Airfoil Design Problems, Applied Sciences, 17, 1318, https://doi.org/10.3390/app7121318, 2017. a, b
Bortolotti, P., Tarrés, H. C., Dykes, K. L., Merz, K., Sethuraman, L., Verelst, D., and Zahle, F.: IEA Wind TCP Task 37: Systems Engineering in Wind Energy – WP2.1 Reference Wind Turbines, United States, https://doi.org//10.2172/1529216, 2019. a
Damiani, R., Dana, S., Annoni, J., Fleming, P., Roadman, J., van Dam, J., and Dykes, K.: Assessment of wind turbine component loads under yaw-offset conditions, Wind Energ. Sci., 3, 173–189, https://doi.org/10.5194/wes-3-173-2018, 2018. a
Emmerich, M. T., Giannakoglou, K. C., and Naujoks, B.: Single-and multiobjective evolutionary optimization assisted by Gaussian random field metamodels, IEEE T. Evolut. Comput., 10, 421–439, 2006. a
Emmerich, M. T., Deutz, A. H., and Klinkenberg, J. W.: Hypervolume-based expected improvement: Monotonicity properties and exact computation, in: 2011 IEEE Congress of Evolutionary Computation (CEC), IEEE, 2147–2154, https://doi.org/10.1109/CEC.2011.5949880 2011. a
Ern, A. and Guermond, J.-L.: Theory and practice of finite elements, Springer, vol. 159, https://doi.org/10.1007/978-1-4757-4355-5, 2004. a
Fleming, P., Annoni, J., Churchfield, M., Martinez-Tossas, L. A., Gruchalla, K., Lawson, M., and Moriarty, P.: A simulation study demonstrating the importance of large-scale trailing vortices in wake steering, Wind Energ. Sci., 3, 243–255, https://doi.org/10.5194/wes-3-243-2018, 2018. a
Frøseth, G. T. and Capponi, L.: fatpack, GitHub [code], https://github.com/Gunnstein/fatpack (last access: 19 Septemebr 2022), 2021. a
Ghoreishi, S. F. and Allaire, D. L.: A fusion-based multi-information source optimization approach using knowledge gradient policies, 2018 AIAA/ASCE/AHS/ASC Structures, Structural Dynamics, and Materials Conference, 1159 pp., https://doi.org/10.2514/6.2018-1159, 2018. a
Ginsbourger, D., Le Riche, R., and Carraro, L.: Kriging is well-suited to parallelize optimization, in: Computational intelligence in expensive optimization problems, Springer, 131–162, https://doi.org/10.1007/978-3-642-10701-6_6, 2010. a
Giselle Fernández-Godino, M., Park, C., Kim, N. H., and Haftka, R. T.: Issues in deciding whether to use multifidelity surrogates, AIAA Journal, 57, 2039–2054, 2019. a
He, X., Tuo, R., and Wu, C. J.: Optimization of multi-fidelity computer experiments via the EQIE criterion, Technometrics, 59, 58–68, 2017. a
Hennig, P. and Schuler, C. J.: Entropy search for information-efficient global optimization, J. Mach. Learn. Res., 13, 1809–1837, 2012. a
Howland, M. F., Lele, S. K., and Dabiri, J. O.: Wind farm power optimization through wake steering, P. Natl. Acad. Sci. USA, 116, 14495–14500, 2019. a
Huang, D., Allen, T. T., Notz, W. I., and Miller, R. A.: Sequential kriging optimization using multiple-fidelity evaluations, Struct. Multidiscip. O., 32, 369–382, 2006. a
Hulsman, P., Andersen, S. J., and Göçmen, T.: Optimizing wind farm control through wake steering using surrogate models based on high-fidelity simulations, Wind Energ. Sci., 5, 309–329, https://doi.org/10.5194/wes-5-309-2020, 2020. a, b, c
Hupkens, I., Deutz, A., Yang, K., and Emmerich, M.: Faster exact algorithms for computing expected hypervolume improvement, in: international conference on evolutionary multi-criterion optimization, Springer, 65–79, https://doi.org/10.1007/978-3-319-15892-1_5, 2015. a
International Electro-technical Commission: IEC 61400-13: Wind turbines-Part 13: Measurement of mechanical loads, International Electro-technical Commission (IEC), Geneva, 219 pp., 2015. a
Jones, D. R., Schonlau, M., and Welch, W. J.: Efficient global optimization of expensive black-box functions, J. Global Optim., 13, 455–492, 1998. a
Lin, M. and Porté-Agel, F.: Power Maximization and Fatigue-Load Mitigation in a Wind-turbine Array by Active Yaw Control: an LES Study, J. Phys. Conf. Ser., 1618, 042036, https://doi.org/10.1088/1742-6596/1618/4/042036, 2020. a
López, B., Guggeri, A., Draper, M., and Campagnolo, F.: Wake steering strategies for combined power increase and fatigue damage mitigation: an LES study, J. Phys. Conf. Ser., 1618, 022067, https://doi.org/10.1088/1742-6596/1618/2/022067, 2020. a
Martínez-Tossas, L. A. and Branlard, E.: The curled wake model: equivalence of shed vorticity models, J. Phys. Conf. Ser., 1452, 012069, https://doi.org/10.1088/1742-6596/1452/1/012069, 2020. a
Martínez-Tossas, L. A., Annoni, J., Fleming, P. A., and Churchfield, M. J.: The aerodynamics of the curled wake: a simplified model in view of flow control, Wind Energ. Sci., 4, 127–138, https://doi.org/10.5194/wes-4-127-2019, 2019. a
National Renewable Energy Laboratory (NREL): WindSE, commit hash f217bd0986325d86ee0ffac083a71fd4ead91b63, GitHub [code] https://github.com/NREL/WindSE (last access: 19 September 2022), 2021. a, b
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E.: Scikit-learn: Machine Learning in Python, J. Mach. Learn. Res., 12, 2825–2830, 2011. a, b, c
Picheny, V., Ginsbourger, D., Richet, Y., and Caplin, G.: Quantile-based optimization of noisy computer experiments with tunable precision, Technometrics, 55, 2–13, 2013. a
Qin, C., Klabjan, D., and Russo, D.: Improving the expected improvement algorithm, in: 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017, edited by: Guyon, I., Von Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., Advances in Neural Information Processing Systems, 5381–5391, ISBN: 9781510860964, 2017. a
Quick, J.: WES_MFMOFWSS, Version 1, Zenodo [data set], https://doi.org/10.5281/zenodo.7097352, 2022. a
Quick, J., Annoni, J., King, R., Dykes, K., Fleming, P., and Ning, A.: Optimization under uncertainty for wake steering strategies, J. Phys. Conf. Ser., 854, 012036, https://doi.org/10.1088/1742-6596/854/1/012036, 2017. a
Quick, J., King, J., King, R. N., Hamlington, P. E., and Dykes, K.: Wake steering optimization under uncertainty, Wind Energ. Sci., 5, 413–426, https://doi.org/10.5194/wes-5-413-2020, 2020. a
Rajnarayan, D., Haas, A., and Kroo, I.: A multifidelity gradient-free optimization method and application to aerodynamic design, in: 12th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, Victoria, British Columbia, Canada, 10–12 September 2008, p. 6020, https://doi.org/10.2514/6.2008-6020, 2008. a
Rasmussen, C. E. and Williams, C. K. I.: Gaussian processes for machine learning, Adaptive computation and machine learning, MIT Press, Cambridge, Mass, https://doi.org/10.1007/978-3-540-28650-9_4, 2006. a, b
Rinker, J. M., Soto Sagredo, E., and Bergami, L.: The Importance of Wake Meandering on Wind Turbine Fatigue Loads in Wake, Energies, 14, 7313, https://doi.org/10.3390/en14217313, 2021. a
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., and De Freitas, N.: Taking the human out of the loop: A review of Bayesian optimization, P. IEEE, 104, 148–175, 2015. a
Van Dijk, M. T., van Wingerden, J.-W., Ashuri, T., and Li, Y.: Wind farm multi-objective wake redirection for optimizing power production and loads, Energy, 121, 561–569, 2017. a
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, İ., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., and SciPy 1.0 Contributors: SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python, Nat. Methods, 17, 261–272, https://doi.org/10.1038/s41592-019-0686-2, 2020. a, b
Voorneveld, M.: Characterization of pareto dominance, Oper. Res. Lett., 31, 7–11, 2003. a
Wang, C., Campagnolo, F., and Bottasso, C.: Does the use of load-reducing IPC on a wake-steering turbine affect wake behavior?, J. Phys. Conf. Ser., 1618, 022035, https://doi.org/10.1088/1742-6596/1618/2/022035, 2020. a
Yang, K., Palar, P. S., Emmerich, M., Shimoyama, K., and Bäck, T.: A Multi-Point Mechanism of Expected Hypervolume Improvement for Parallel Multi-Objective Bayesian Global Optimization, in: GECCO '19: Proceedings of the Genetic and Evolutionary Computation Conference, Prague, Czech Republic, 13–17 July 2019, Association for Computing Machinery, New York, NY, USA, 656–663, https://doi.org/10.1145/3321707.3321784, 2019. a
Yin, X., Zhang, W., Jiang, Z., and Pan, L.: Data-driven multi-objective predictive control of offshore wind farm based on evolutionary optimization, Renew. Energ., 160, 974–986, 2020. a
Zalkind, D. S. and Pao, L. Y.: The fatigue loading effects of yaw control for wind plants, in: 2016 American Control Conference (ACC), IEEE, 537–542, https://doi.org/10.1109/ACC.2016.7524969, 2016. a
Zhan, D. and Xing, H.: Expected improvement for expensive optimization: a review, J. Global Optim., 78, 507–544, 2020. a